Liquid Ai Releases LFM2-8B-A1B: A mixture of device combination with 8.3b packets and active 1.5B paramas with each token

How much energy is the lower 8.3B-parameter Moe with a ~ 1.5B is a practical way bring to your phone without hitting the latency or memory? The cream has built the issue LFM2-8B-A1BA MOTHER MOTE of a mixture of murder of – the experts built for the murder of service under strong memory, latency, and power budgets. Unlike most of the MOE function designed to serve the batch cloud, LFM2-8B-A1B phones, laptops, and embedded systems. Indicates 8.3B Parameters But it only works ~ 1.5B Parameter with each tokenUsing a sparse scholarship route to maintain a small shape of compute while increasing your ability to. The model is released under the Lfm v1.0 (LFM1.0)
Understanding the construction of buildings
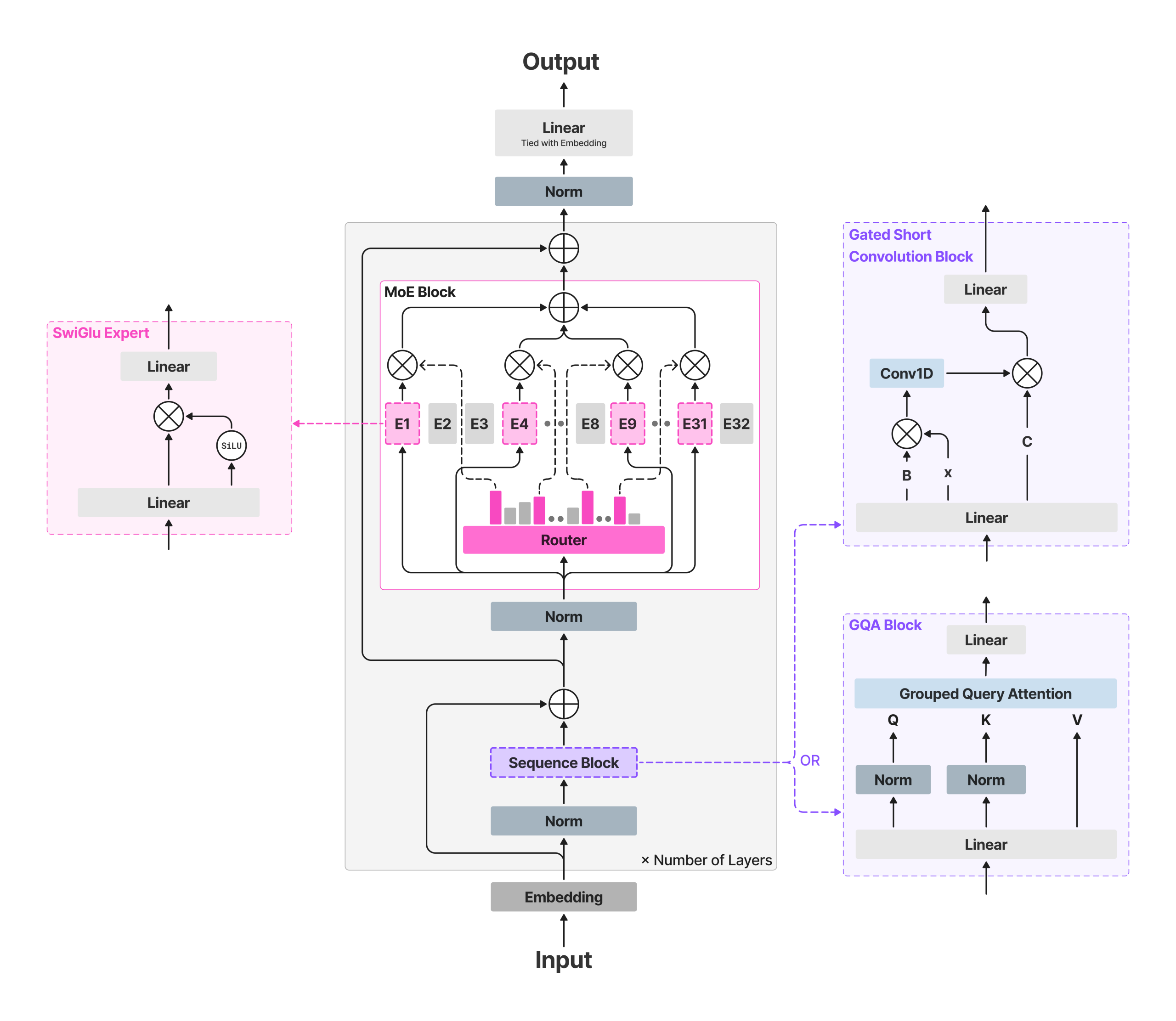
LFM2-8B-A1B maintains LFM2 'backback' and includes Sparse-Moe Feed-forward features of power without enhancing sturments. The use of the back back 18 SATED SATED BLUS including 6 Attention Collected to Blocks (Cross). All the layers Without the first first Enter MOE block; The first two remained intensified. MOE BLOCK means 32 Experts; The router is selective Top 4 specialists for each token with a Sigmoid usual gateway including Adaptive Routiting Bias to estimate the load and settle training. Length 32,768 tokens; vocabulary size 65,536; An adversal budget is reported ~ 12T tokens.
This approach is keeping the growth of the per-towken growth of cache.
Service signals
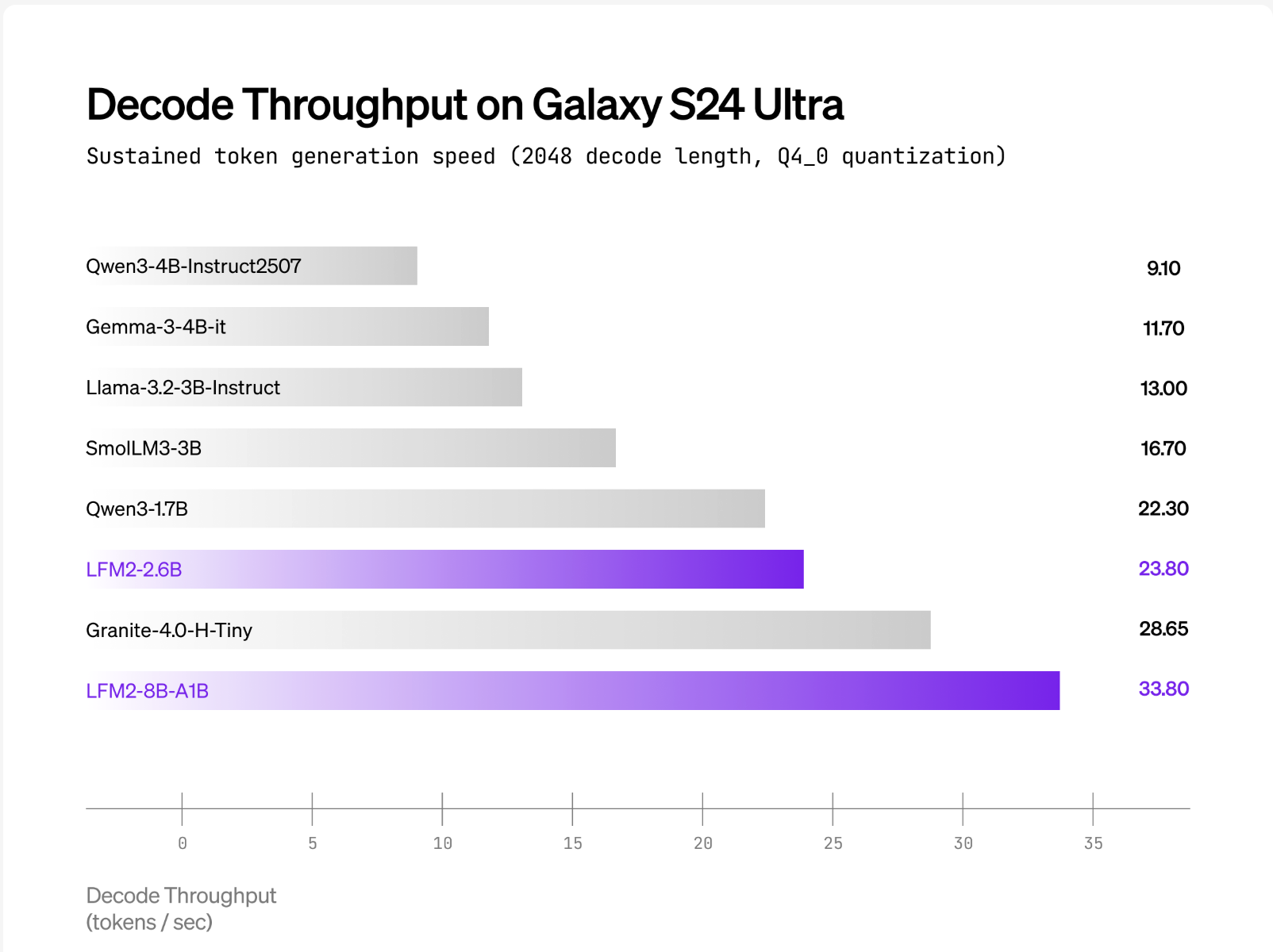
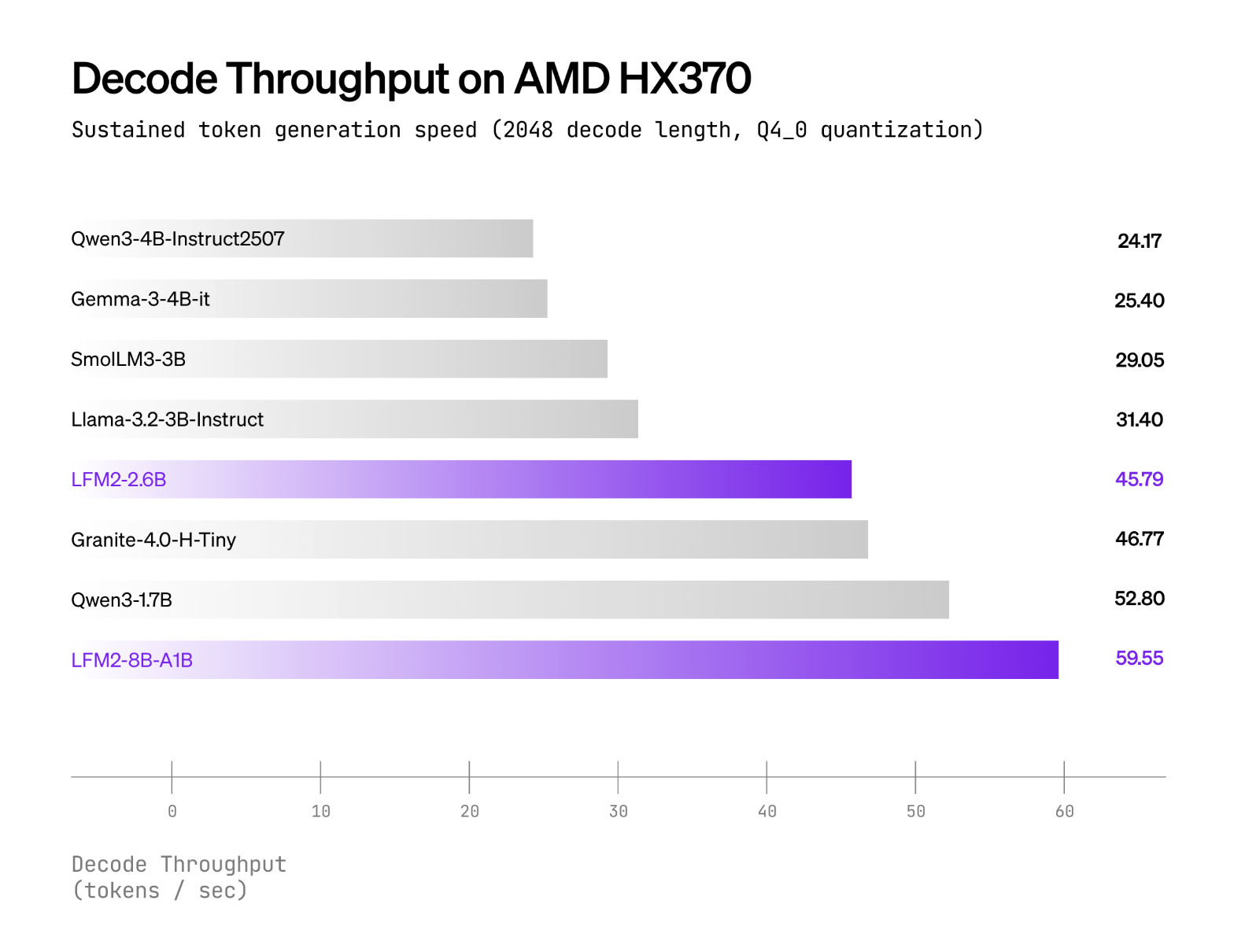
Liquid Ai reports that LFM2-8B-A1B Works as soon as possible than QWEN3-1.7b Under CPU test using the internal Xnnpack-based stack and CPU MOE Kernel of custom. The Cover of Public Buildings Int4 Nightionition with IT8 Dynamic Activations despite of- Amd ryzen ai 9 hx370 including Samsung Galaxy S24 Ultra. Liquid Ai Quality Ai Quality compared to Him as 3-4B models are thickWhile keeping active computing nearby 1.5b. Neither the seller of the Cross-Vendor “× and various published; Claims are included compared with the comparative per-device Versus the same models are active models.
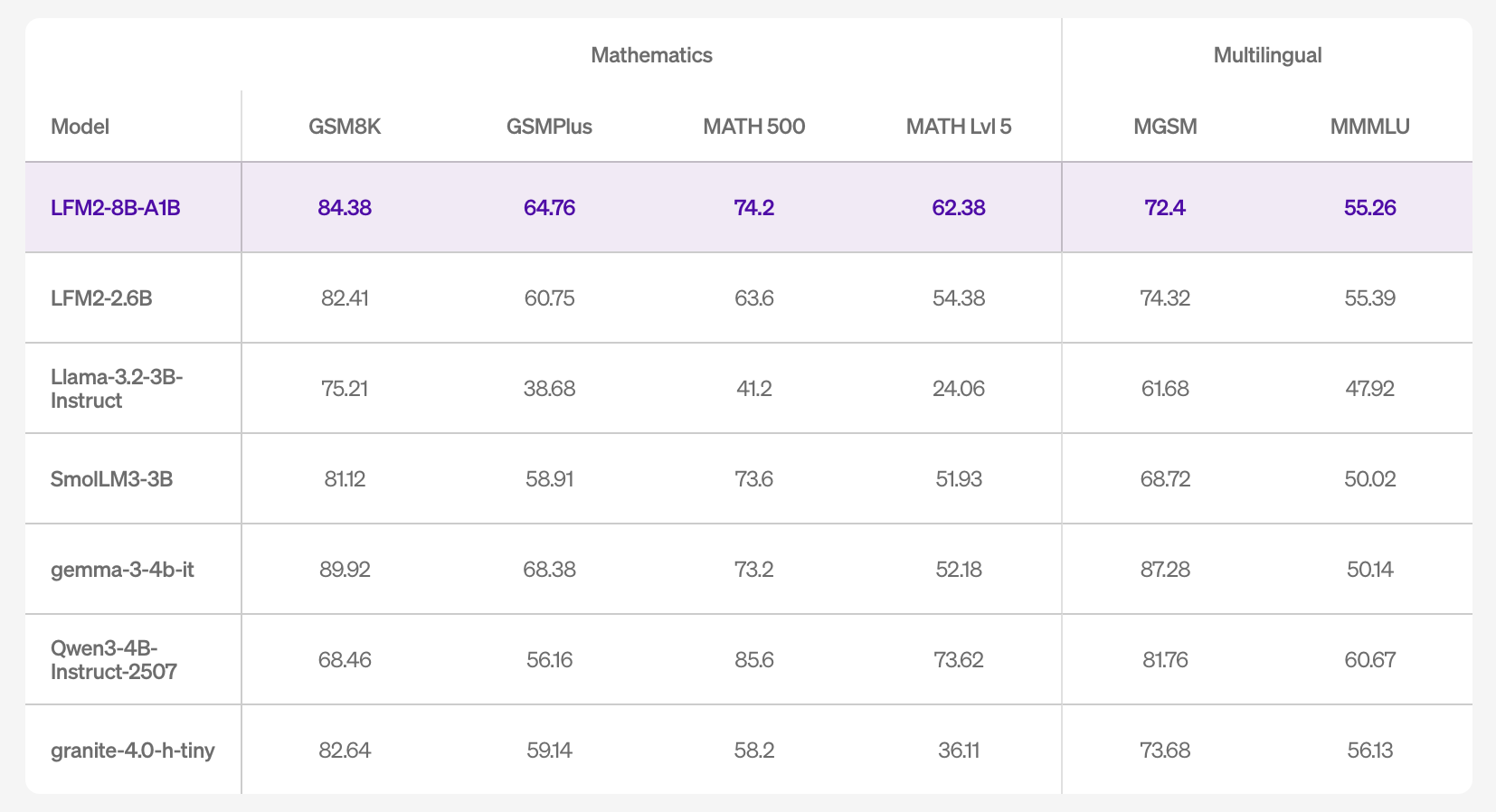
On Accecy, the Model Card Lists Resus Across 16 Benchmarks, Including MMLU / MMLU-Pro / IFBEWING / MATH-LvL-5 (MATT), and Mgsm / mmmlu (multilingual). Numbers show competition tutorial – Next and Math's operations within a small model band, and developed information associated with LFM2-2.6B, accompanied by a major parameter.

Shipment and Finding Power
LFM2-8B-A1B Ships With Advantes / VLLM of GPU inducers and GGUF Build Illama.cpp; The official GGUF repo lists ordinary quants from Q4_0 ≈4.7 GB up to F16 ≈16.7 GB For local run, while Lama.cpp needs recent construction with lfm2moe Support (B6709 +) Avoid “Rose errors model is unknown”. CPU CPU usage Q4_0 reference AT8 Dynamic Activation despite of- Amd ryzen ai 9 hx370 including Samsung Galaxy S24 UltraWhen LFM2-8B-A1B indicates higher conversion to higher QWEN3-1.7B in the same practical class – parameter; Fog Organized by mobile phones / embedded by CPU.
Healed Key
- Properties and Trailway: LFM2-8B-A1B Back Backbone (18 GAF BACKSHONE (18 GAAD block EXAMINATIONS OF 8.3B, 1.5B active in each Token.
- Target device: Designed, laptops, and CPUS / GPUS; Variants are separated by “well appropriate” with higher private sales, lower than latency.
- Standing of work. Liquid reports LFM2-8B-A1B More quickly than QWEN3-1.7B In the CPU tests and target The quality of the upper 3-4b While keeping the active way of ~ 1.5b.
LFM2-8B-A1B indicates that Sparse Moe may apply to the bottom of the standard server state. The model includes LFM2 Back-Enlisting LEFM-SANDS with PER-MLPS expert (without the first two layers) to keep the tokens meet near 1.5b With the usual weight, GGUF, LLAMA.CPP / EXECKING Percious, and VFM2-8B-A1B is a concrete option to build a latentct, the private sector and the sale of consumer and EDGE.
Look The model in the kisses of face including Technical Details. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper. Wait! Do you with a telegram? Now you can join us with a telegram.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
Follow MarkteachPost: We have added like a favorite source to Google.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


