Cut researchers present the work that calls llms: Eliminating SQL relief to improve the accuracy of information and efficiency

Details are essential for the maintenance and restore formal data to support the business of business, research, and business requests. Questions information usually requires SQL, varying the programs and can be complex. While IllMS provides automated power, many methods depend on the environmental language in SQL, often lead to errors due to the variations of syntax. API based on work-based API appears as an alternative way, enabling the llMs to communicate with systematic data effectively in different data systems.
In this study, a problem that is addressed to enhance the accuracy and efficiency of the data questions conducted by the LLM. The existing Pert-to-SQL solutions tend to struggle:
- Different programs for data management (DBMS) use their SQL languages, making it difficult for llms to get common in all many platforms.
- Many of the real world questions include filters, integrated, and the FUCE transformation, which current models treat them easily.
- It is important to ensure that questions intend to prepare database sets, especially in cases involving multi-projected data structures.
- The performance of the llm in a formal database varies depending on the difficulty of question. Employment requires regular test benches.
The database based on the LLM-based Completely depends largely on the text-to-SQL translation, where models transform natural language to the questions of SQL. Benchmarks are like Wikisql, spider, and accuracy of birds based on SQL generation but does not interfere with systematic information. These methods often fight with search questions, forms of buildings, and the tracking lane. As the Database buildings are far more different, more flexible method is required – one moves more than the SQL dependence on the killer.
Investigators from church, AI of Ai, and in the morning submit a systematic calling method to question the information without depending on SQL. This approach describes the functions of the search, filters, integration, and groups, to improve accuracy and redress Text-to-SQL errors. They promote DBGORILLA BENCHMARK Examining to work and test eight llms, including GPT-4O, Claude 3.5 Sonnet, and Gemini 1.5 Pro. By removing SQL dependence, this method improves fluctuations, making data interactions more reliable and large.
DBGORILLA is a set of 315 questions in all five database, each containing three related collections. The data adds between numbers, text, and boolean filters and combinations such as a SUM, AVG, and counting. Working tested using the direct matching of the game, the syntax drug in Astralax (AST), and collecting the accuracy of the route. DBGORILLA tested llms at a controlled area, unlike bench-based benchmarks, confirming systematic API questions including SQL raw.
Research has examined eight llMs operations across all three main matters:
- Match the specific points
- The alignment of the AST
- Collecting the correctness of the route
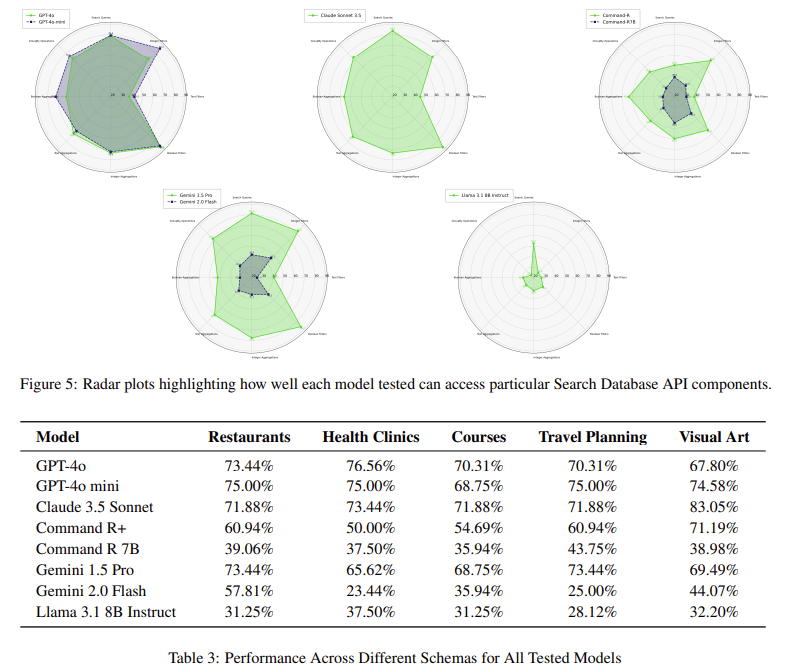
Claude 3.5 Sonnet has achieved the highest points such as 74.3%, followed by GPT-4O mini in 73.7%, Gemt-4O, and Gemini 1.5 screen. Boolean buildings were treated with highest accuracy, up to 87.5%, and documentation indicating asset indicates low accuracy, models often confuse them. The accuracy of the collection system was consistent, with highly operational models to between 96% and 98% accuracy. When analyzing the question is the issue, GPT-4O has received 87.5% accurate questions that require only one objections, but% of the complex questions including multiple parameters include multiple parameters include multiple parameters They involve many parameters.
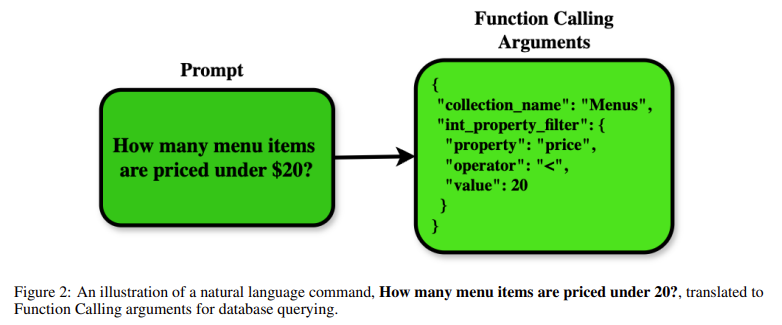
The investigators conduct other tests of evaluation the impact of telecommunications management. To allow the llMS to perform the delivery function reduce slow accuracy, with a direct match score of 71.2%. Separate calls applies to individual sets collections had a small impact, which score 72.3%. Instead of work with a fixed response generation has provided the same results, with the accuracy of 72.8%. Call resistance activity is gradually impacted, but structured structure continues to regularly apply to different configuration.
In conclusion, research has shown that calling needed provides for other visual methods of Scriptural-to-to-SQL questions. The main detection including:
- The higher accuracy of a fixed generation: high models found in the accuracy of 74%, exceeding many Text-to-SQL bench bench.
- Database Reging Reabase's performance
- Challenges with text assets: The llms struggled to distinguish between the planned sorting and search questions, indicating the development area.
- Function call diversity has little effect on working, and different work configurations, including mental-based, similar phones, had only small results.
Survey the paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Record Open-Source Ai Platform: 'Interstagent open source system with many sources to test the difficult program' (Updated)
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
✅ [Recommended] Join Our Telegraph Channel
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


