
Chatgt is something like: “Please check out all the technology and summarize styles and patterns based on what you think I will be interested, when a few websites searches, where it is investigating.
This is because Chatgpt is designed for normal use charges. It works the most common search methods for download information, often protect themselves on a few web pages.
This article will show you how to build a niche agent that can organize all the technical tech, combine millions of documents, filter data based on a person, and get patterns and themes you can.
The point of this work is to avoid sitting and investigate the stadiums and resources for your own. Agent should do for you, holding anything useful.

We will be able to deduct this using a unique data source, a controlled function, and certain proployment strategies.

For saved details, we can keep the costs call a few cents per report.
If you want to try the bot without separating yourself, you can join the import station. You will find the last place here if you want to build it on your own.
This document is focused on the standard formulation and how to create it, not smaller information as you can find those in Guthub.
Notes in the building
If you are new to creating agents, you may feel as if this is not enough enough.
However, if you want to build something that works, you will need to use multiple engineering software in your AI programs. Even if the llms can now do itself, it still requires guidance and Guardrails.
For areas such as this, where there is a clear way the program to take, you should create organized systems “if you have a person in the loop, can work with something moving.
The reason for work abundance is effective because I have a very good route source behind it. Without this data Mooat, work flow would not be done better than Chatgpt.
Preparation and reserves for data
Before we can create a agent, we need to prepare for a data source you can affect.
The thing that I think is the fault of working with the LLM programs is the belief that AI can process and combine data completely.
Sometimes, we may give us enough tools to build themselves, but we have not been honest.
So when we create similar systems, we need data pipes to be clean as one program.
The program I've created here uses a source of existing data, which means I understand how to teach the LLM to enter it.
It includes thousands of documents from Tech stadiums and websites a day and uses small NLP models to destroy large keywords, distinguish, and analyze the feeling.
This allows us to see which keywords the keywords tend to be different in different categories.
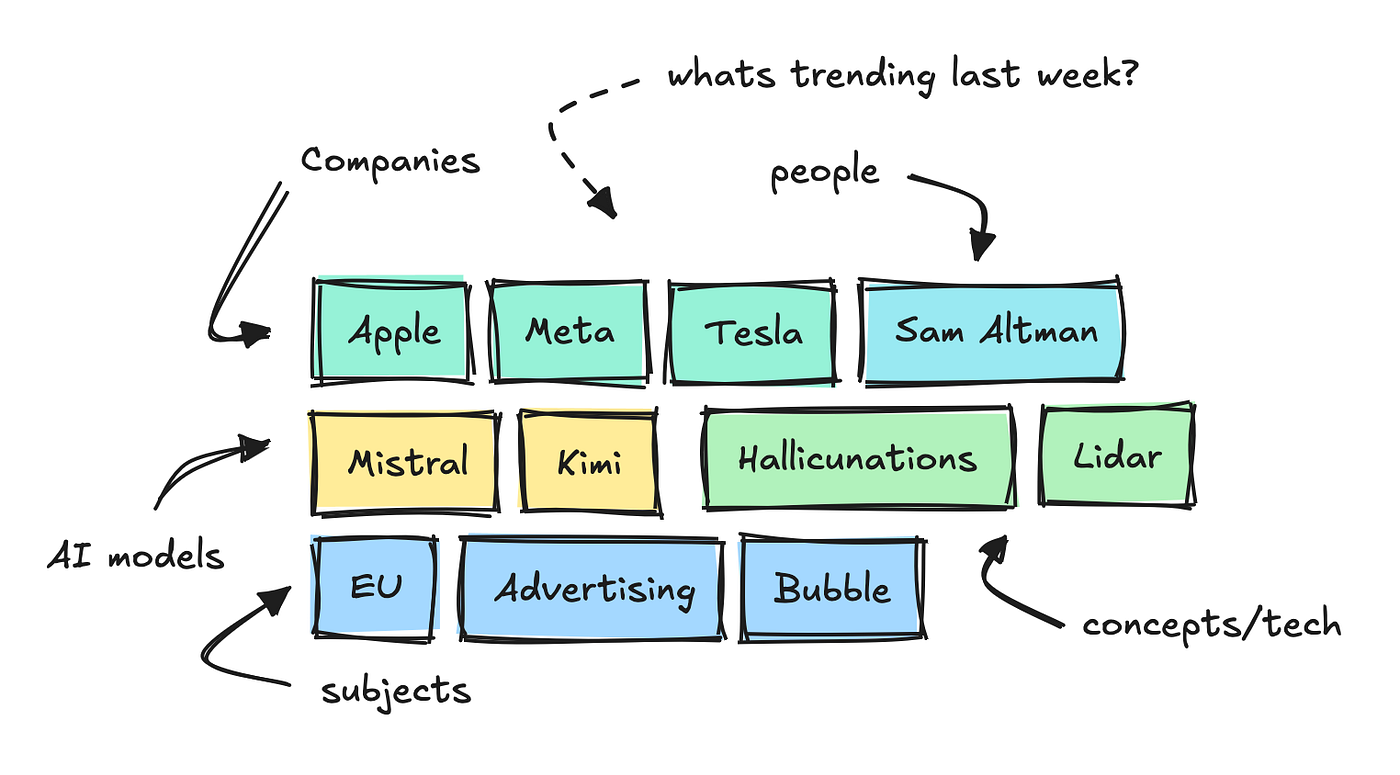
Building this Angel, I added another conclusion to each of these keywords.
This conclusion finds keyword and time, and the program filters the comments and posting. Then process the texts to Chunks in small models that can determine which “facts” should keep.
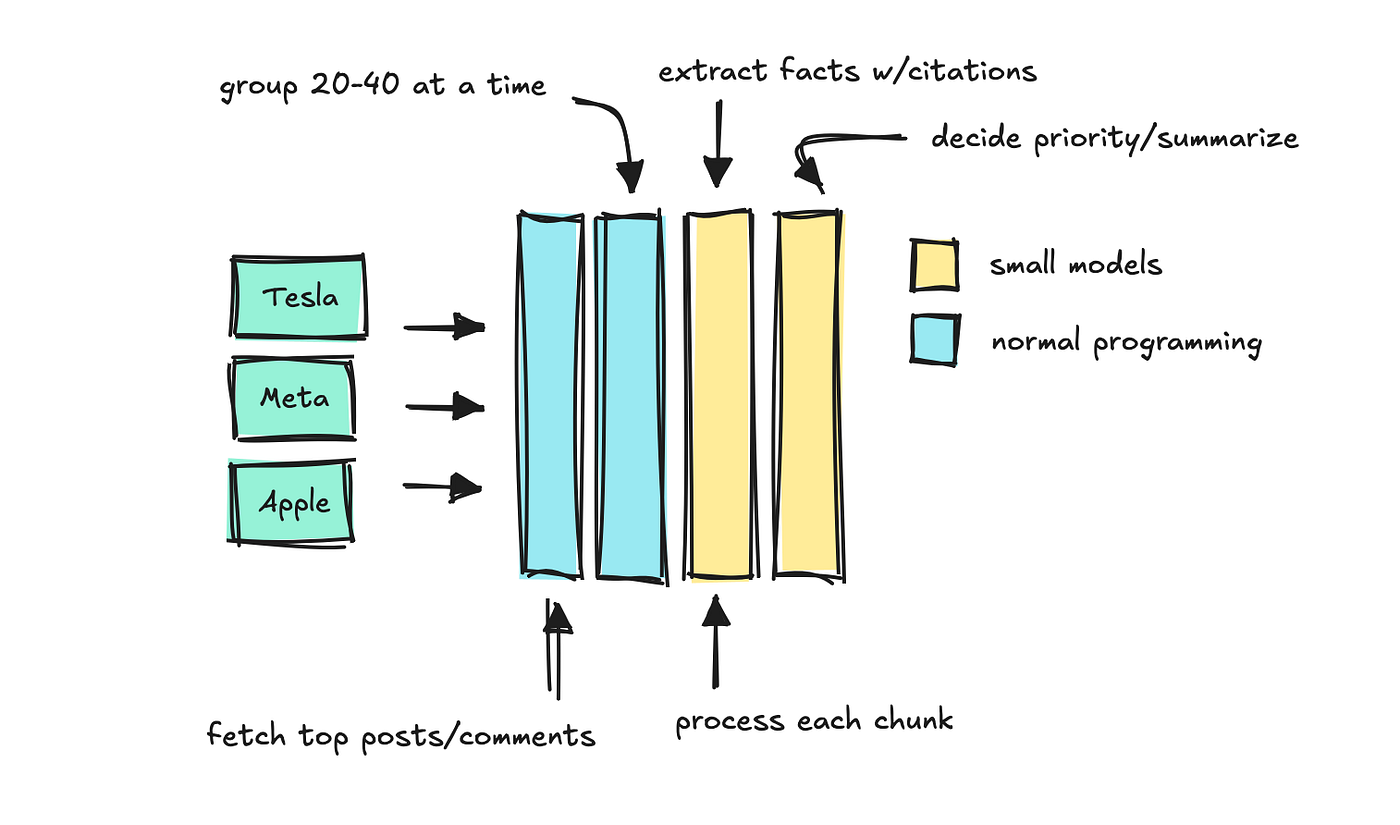
We use the last LLM to summarize the most important facts, keeping source quotes are strong.
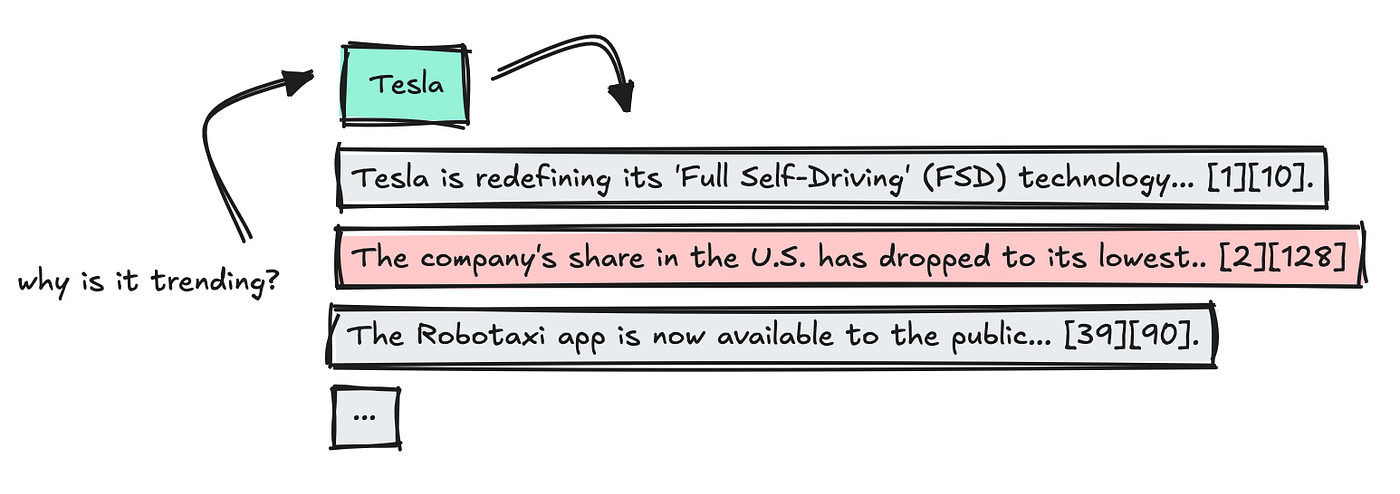
This is a form of quick process to install the key, and I have created in Memic LMAindex's Citation Engine.
The first time is the only word called keyword, it may take up to part of a minute to finish. But as the program keeps the result, any application for repetition takes just a few mileses.
As long as the models are sufficient enough, the cost of using this is a few hundred keywords per day. Later, we can have that program and running a few words exactly like.
You can think now that we can create a download program keywords and facts to create different reports on llms.
When can you work in small vs models
Before moving forward, let's just say that choosing the right size conditions.
I think this is in everyone's mind now.
There are very advanced models that you can use in any work flow, but as we start installing many llms in these applications, the number of calls by effective startup and this can be expensive.
So, when you can, use smaller models.
You have seen that I have used small models to talk along with group resources with chunks. Some good functions in smaller models include the environment and repair environment in orderly data.
If you find that the model pulls down, you can break the work into small problems and use Prompt Chained, first do one thing, and use the person to do the following, and so on.
You still want to use big llms when you need to find patterns in the biggest text, or when you communicate with people.
In this incident, costs are small because it is saved, using smaller models of many jobs, and the only major Calls of different LLM are the last.
How: This MENTI works
Let's go how you work under the hood. I built an agent to run inside inside, but it is not the focus here. We will focus on the creation of agent.
I divide the process into two parts: one setup, and one issues. The first process asks the user to set their profile.
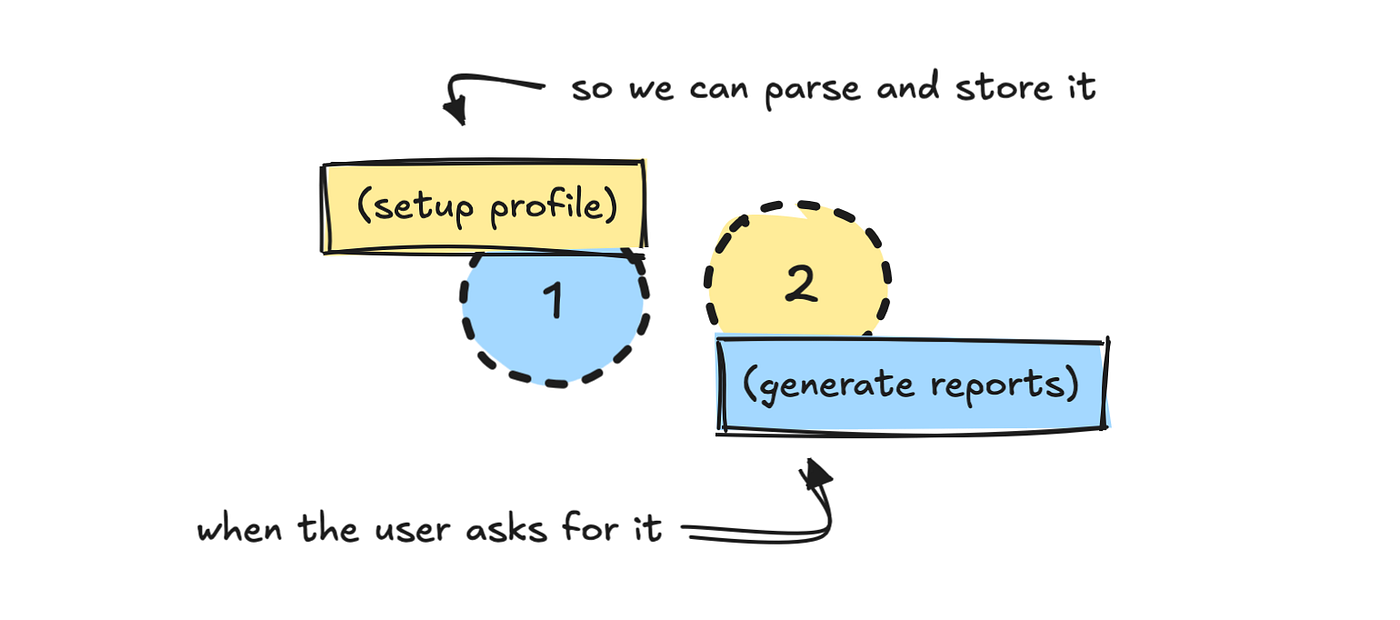
As I already know how I work with a database source, I have immediately developed a system that helps the LLM translated those inputs to which we can later.
PROMPT_PROFILE_NOTES = """
You are tasked with defining a user persona based on the user's profile summary.
Your job is to:
1. Pick a short personality description for the user.
2. Select the most relevant categories (major and minor).
3. Choose keywords the user should track, strictly following the rules below (max 6).
4. Decide on time period (based only on what the user asks for).
5. Decide whether the user prefers concise or detailed summaries.
Step 1. Personality
- Write a short description of how we should think about the user.
- Examples:
- CMO for non-technical product → "non-technical, skip jargon, focus on product keywords."
- CEO → "only include highly relevant keywords, no technical overload, straight to the point."
- Developer → "technical, interested in detailed developer conversation and technical terms."
[...]
"""
I also explained a schema of the results I need:
class ProfileNotesResponse(BaseModel):
personality: str
major_categories: List[str]
minor_categories: List[str]
keywords: List[str]
time_period: str
concise_summaries: boolWithout getting the API domain information and how it works, it is impossible for the llm to find out how to do this itself.
You can try to build a very comprehensive program when the llm begins to read the API or programs to be used, but it will make the travel travel may be expected and expensive.
For activities like this, I try to use the formal results in JSON format. That way we can guarantee the result, and if the verification fails, we re-eliminate it.
This easiest way to work and llms in the system, especially if no one is in the loop to look at the model.
When the LLM translates the user profile in the building that describes the schema, we keep the profile elsewhere. I used MongDb, but that is optional.
Keeping personality is not required firmly, but you need to interpret the user mentioned in the form that allows you to generate the data.
It creates reports
Let's look at the event of the second stage when the user causes a report.
When the user beats the /news Direct, with progress or outdoor, we begin to download the user's profile data we kept.
This gives the system the context requires downloading the correct data, using both sections and keywords tied to the profile. The default time period of the week.
From this time, we find a list of higher keywords and tend to be a selected time to interest in the user.

Without this data source, to create something such as that it would be difficult. Details require correction in a pre-advance of the llM to work with it well.
After downloading keywords, it can add a LLM step to filter the non-user names. I didn't do that here.
The most unnecessary information of the LLM has been dispensed, it is difficult for them to focus on what is really important. Your work is to make sure that whatever you are feeding the right question of the user.
Next, we use the front ending, containing “facts” are stored. This provides information already organized and each is organized.
We run keywords alike to speed up things, but the first person asks the new keyword should wait a long time.
When the results have entered, we combine data, delete twice, and then combine quotes so each truth connects back to a specific source with keyword.
We then run details about the fastest cruise process. The first LLM receives 5 to 7 themes and set them in line with the user profile. It also releases key points.
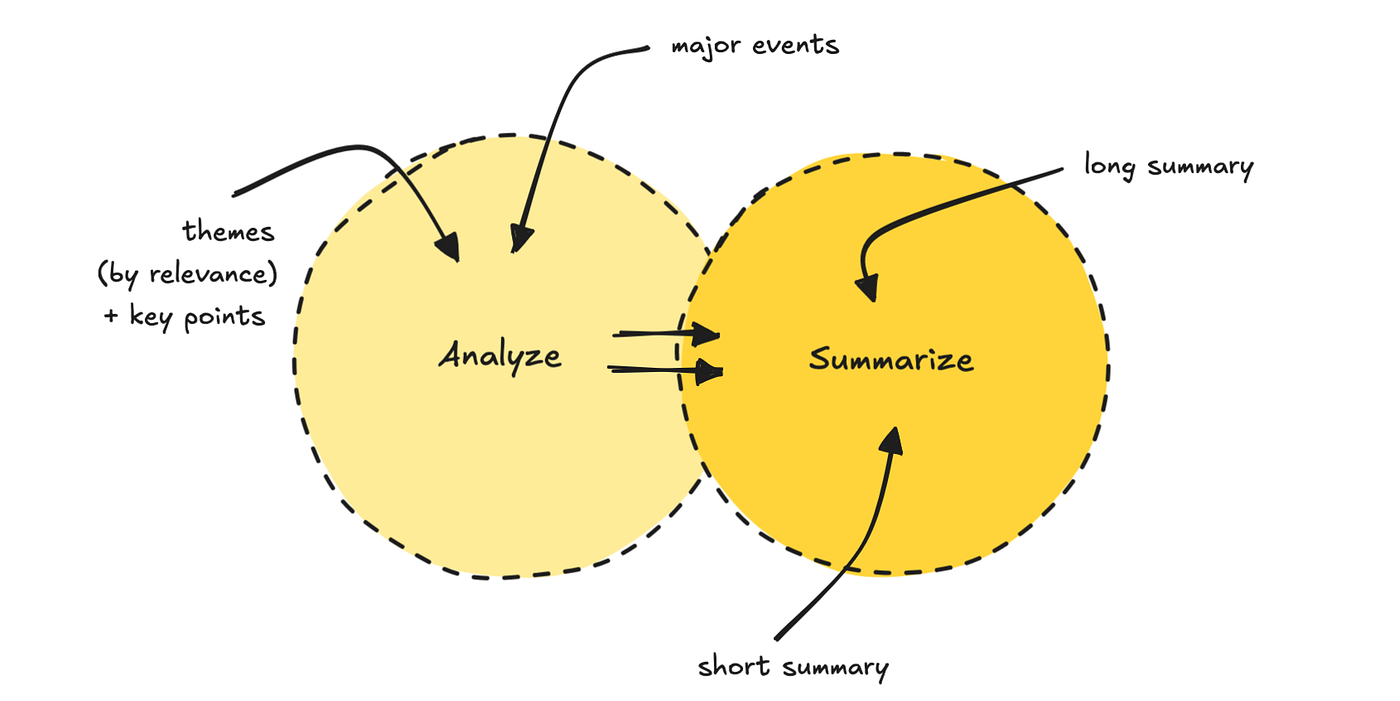
SECOND LLM PASS uses both themes and original data to produce a thick length of summarism, and the topic.
We can do this to make sure to reduce the burden of understanding in the model.
This final step of building this report takes a lot of time, because I have chosen to use a model of a consulting model like GPT-5.
You can change about something quickly, but I get better models better in this last thing.
The perfect procedure takes a few minutes, depending on how much day has been released.
View the last result below.
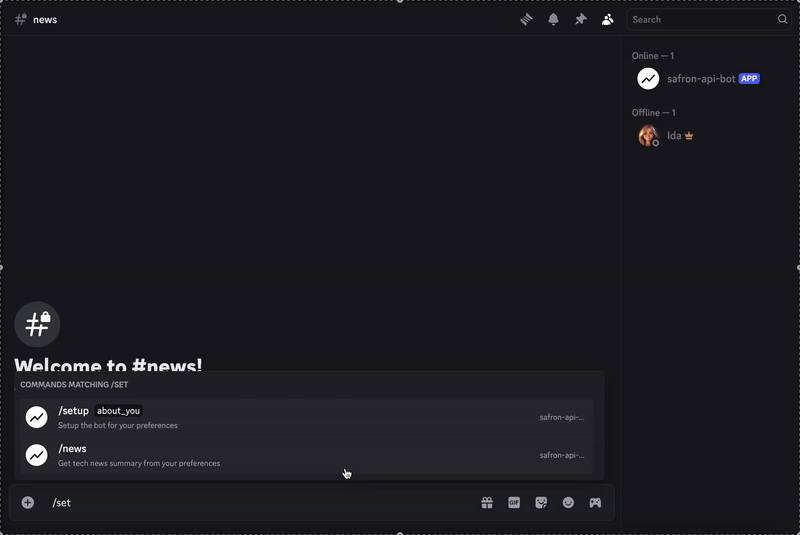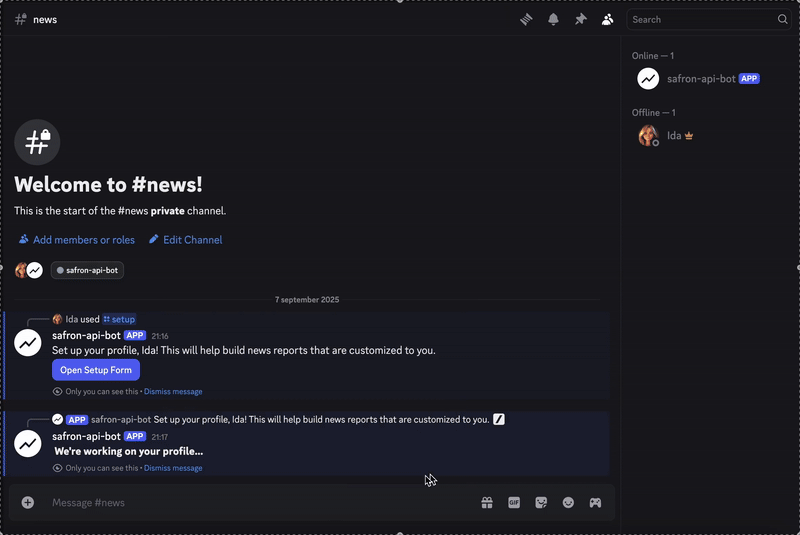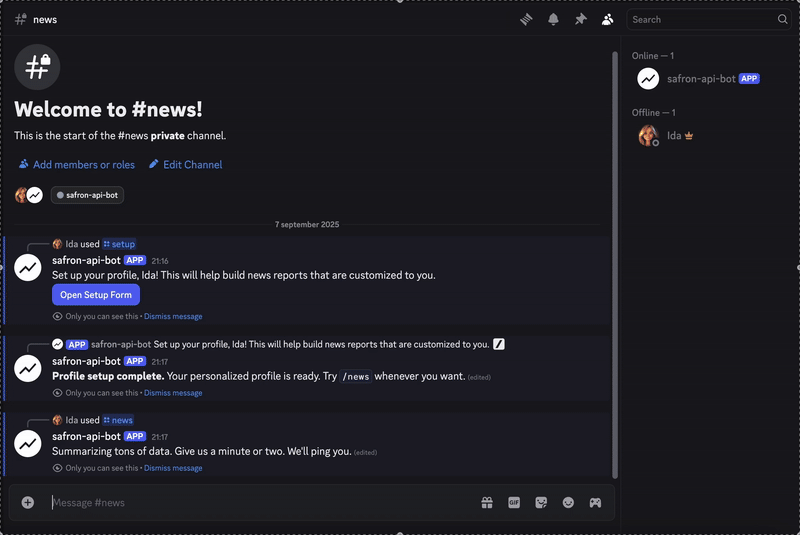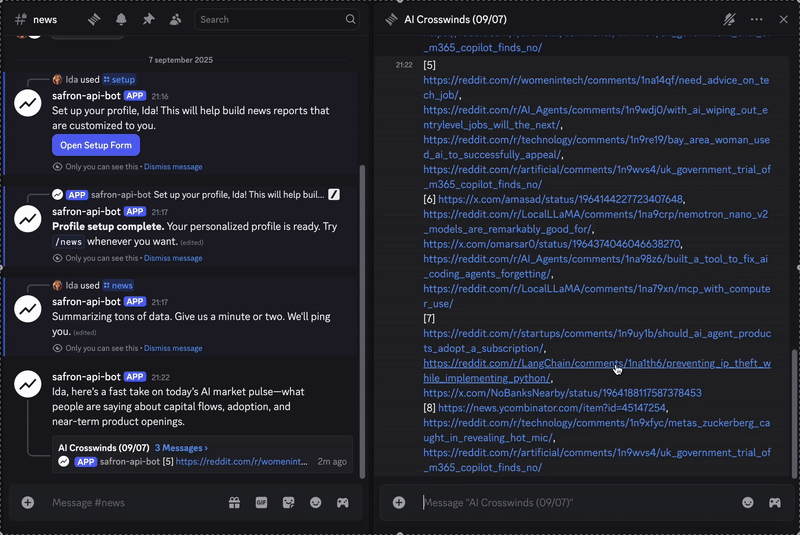
If you want to look at the code and create this experience, you can get it here. As long as you want to produce a report, you can join this channel.
I have some programs to improve, but I'm glad to hear the answer if you find it useful.
And if you are looking for challenge, you can rebuild another object, such as the content generator.
Notes on Building agents
All the constructive agents will be different, so this is not a BLUEPRONT and Construction and LLMS. But you can see the quality of the software engineering of the software.
LLMS, at least yet, do not remove the need for a good software and data engineer.
In this work incident, I use the llms a lot to translate the environment into JSON and submit that through a formal program. It is an easy way to control agent process, but not what people think when thinking about AI apps.
There are situations where an agent is used for a good free, especially when there is someone on the waist.
Still, I hope you learn something, or get inspiration to build something yourself.
If you want to follow my writing, follow me here, my website, Susceck, or LinkedIn.
❤



