Google AI issues Vaultgemma: The largest and most powerful model (1 parameter is trained from the beginning of a different secret

Google Ai study and Deepmind Vaultgemma 1bThe most significant model of a large open space is fully trained Unique privacy (DP). This development is a major step to build ai-powerful AI models and privacy – the prescription.
Why do we need the privacy separated from llms?
Large models of the language trained Dast-Scale Dapets are inclined to Head attackWhen sharp or identical information can be removed from the model. Studies have shown that Debatim training data can be renewed, especially in open weight loss.
The opposite privacy provides a Mathematical Confirmation That prevents any instance of one training from exacerbating the model. Unlike ways that use DP only during good order, Vaultgemma is forced Full order of perfectTo ensure that Privacy Protection begins at the basis of the basis.
What is Vaululgemma last church?
Vaultgemma is like gemma paintings in previous models, but is prepared for private training.
- The model size: 1B parameters, 26 layers.
- Transformmer version: DECODER ONLY.
- Performance: Glu with 13,824 feeds.
- Awareness: The attention of many questions (MQA) have international tokens times.
- General: Rmsnorm in pre-ordinary configuration.
- Tokenzer: Judgment of vocabulary 256k.
Noteworthy change is Reduction of sequence to 1024 tokensthat is lower cost and enables large batch sizes under DP problems.

What data is used for training?
Valultgemma was trained in Same 13 trillion-token data Like Gemma 2, it was mainly composed of English from the Web Docs, code, and scientific articles.
The data adds a few sorting categories to:
- Delete unsafe or sensitive content.
- Reduce the exposure of personal information.
- Hinder the test data contamination.
This guarantees safety and impartiality on observing marks.
How was the privacy of different variations used?
A used vaultgemma DP-SGD (Stochastic Gradient FaceCent) In a gradient and gaussian and noise. Implementation is built on The privacy of jax including presented the scale of the scales:
- Per-Example Separation by the corresponding efficiency.
- Collection imitating the big badges.
- Poisson decrease combined in the data loader for a successful sample of the fly.
The model found a A formal DP guarantee of (ε ≤ 2.0, δ ≤ 1.1E-10) at a sequence level (1024 tokens).
How does the estimate apply to private training?
Training large models under DP problems require new measurement strategies. Vaultgemma team developed Special measuring rules for DP For three new things:
- Top Top Learning model Using the quadratic equity of training run.
- Parametric EXTRAPOLATION OF FASESS FASS reducing dependence on average assessment.
- Semi-Pharametric fits In order to do the standard for model size, training measures, and noise-batch ratings.
This method has enabled the direct prediction of the possible loss and use of effective services in TPUV6e Training Cluster.
What was the training configuration?
Valultgemma was trained 2048 tpuv6e chips Using the GSPMD separation and the combination of Megascale Xla.
- Batch size: ~ 518k tokens.
- Interations training: 100,000.
- The sound of the Music: 0.614.
Liked loss was within 1% forecasts from the DP measurement of the DP, to ensure procedure.
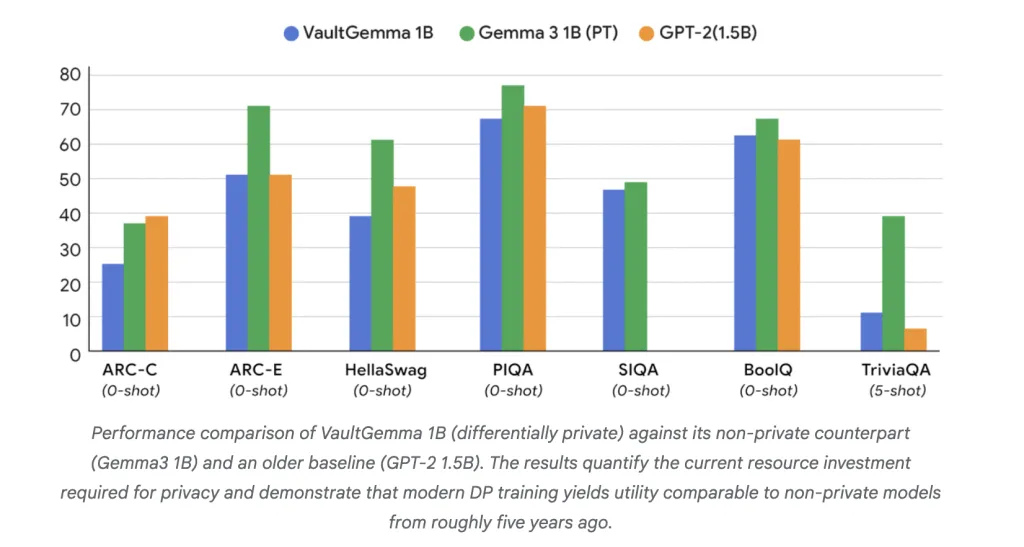
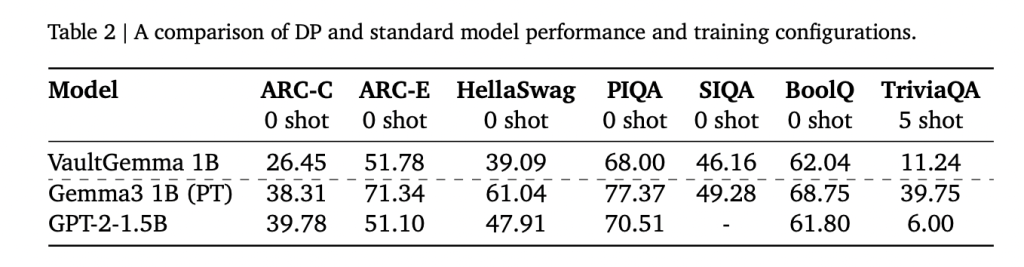
How does Vaultgemma work in comparison with non-private models?
In the education benches, Vaultgemma follows its non-confidential partner but shows strong use:
- Arc-c: 26.45 vs. 38.31 (Gemma-3 1B).
- Jump: 68.0 vs. 70.51 (GPT-2 1.5b).
- Triviala (5-Shot): 11.24 vs. 39.75 (Gemma-3 1b).
These results suggest that DP trained models are currently compared to Non-private models are from about five years ago. What is important, tests of remember to confirm that No data refund It was found in Vaultgemma, unlike gemma models.
Summary
In short, Vaultgemma 1B proves that models of large languages can be trained in solid privacy issues without pretending to use them. While the use gap consists of comparable with non-true partners, the release of both model and its training system is providing the public on a solid basis for private Ai private development AI. This work signs the transition to building only unknown models but also a natural, obvious, and confidentiality.
Look Paper, the model in the sight of the face including Technical Details. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


