Researchers from MIT, Google DeepMind, and Oxford Reveal Why Visual Language Models Don't Understand Objections and Propose a Groundbreaking Solution

Visual language models (VLMs) play an important role in multimodal tasks such as image retrieval, visualization, and medical diagnosis by manipulating visual and linguistic data. However, understanding denial in these models is still one of the biggest challenges. Negation is important in different systems, such as distinguishing a “room without windows” from a “room with windows.” Despite their advances, current VLMs fail to interpret denial reliably, greatly limiting their performance in advanced domains such as security monitoring and healthcare. Addressing this challenge is important to extend their applicability to real-world situations.
Current VLMs, such as CLIP, use shared embedding spaces to align visual and textual representations. Although these models perform very well on tasks such as cross-path retrieval and image captioning, their performance drops significantly when it comes to negative statements. This limitation arises due to the bias of the pre-training data because the training data sets contain mostly affirmative examples, which leads to confirmation bias, where the models treat negative and affirmative statements as equivalent. Existing benchmarks such as CREPE and CC-Neg rely on simple template examples that represent the richness and depth of negation in natural language. VLMs tend to break down the embedding of negative and positive captions so it is very challenging to distinguish the difference between the concepts. This creates a problem in using VLMs for precision language understanding applications, for example, querying medical image databases with complex inclusion and exclusion criteria.
To address these limitations, researchers from MIT, Google DeepMind, and the University of Oxford proposed the NegBench framework for testing and improving negation understanding with VLMs. The framework assesses two basic tasks: Negligible Retrieval (Neg-Retrieval), which tests the model's ability to retrieve images according to both affirmative and negative meanings, such as “desolate sea,” and Negligible Multiple Choice Questions (MCQ-Neg), which tests multiple-point comprehension. by requiring the models to select the appropriate captions from the minimum variance. It uses large synthetic datasets, such as CC12M-NegCap and CC12M-NegMCQ, augmented with millions of captions containing a variety of negation conditions. This will expose VLMs to somewhat challenging anomalies and published labels, improving model training and testing. Standard datasets, such as COCO and MSR-VTT, were also modified, including denominators and idioms, to further expand linguistic diversity and test robustness. By combining various and complex negation models, NegBench successfully overcomes existing limitations, greatly improving model performance and generalization.
NegBench uses both real and synthetic data sets to test the understanding of negation. Datasets such as COCO, VOC2007, and CheXpert are modified to include negation conditions, such as “This image includes trees but not buildings.” In MCQs, templates such as “This picture includes A but not B” are used in conjunction with a variable defined by different words. NegBench is also supplemented with the HardNeg-Syn dataset, where images are combined to present pairs that differ from each other based on the presence or absence of certain objects alone, making it difficult to deny recognition. The correctness of the model depends on two training objectives. On the other hand, contrast loss facilitates alignment between pairs of image captions, which improves performance in retrieval. On the other hand, using multiple-choice loss helped to make well-characterized negation judgments by choosing the correct captions in the context of the MCQ.

The fine-tuned models showed significant improvement in retrieval and understanding tasks using enriched data sets. For retrieval, the recall of the model is increased by 10% for convoluted queries, where the performance is almost equal to normal retrieval tasks. In the multiple-choice question tasks, an improvement in accuracy of up to 40% was reported, indicating a better ability to distinguish between implicit positive and negative captions. Improvements were consistent over a range of datasets, including COCO and MSR-VTT, as well as synthetic datasets such as HardNeg-Syn, where the models handled negation and complex language development appropriately. This suggests that representing situations with different types of negation in training and testing is effective in reducing confirmation bias and generalization.
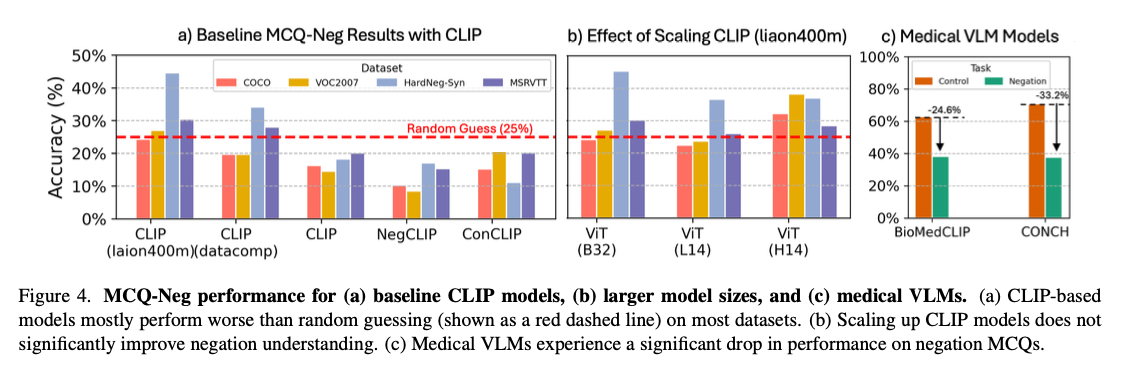
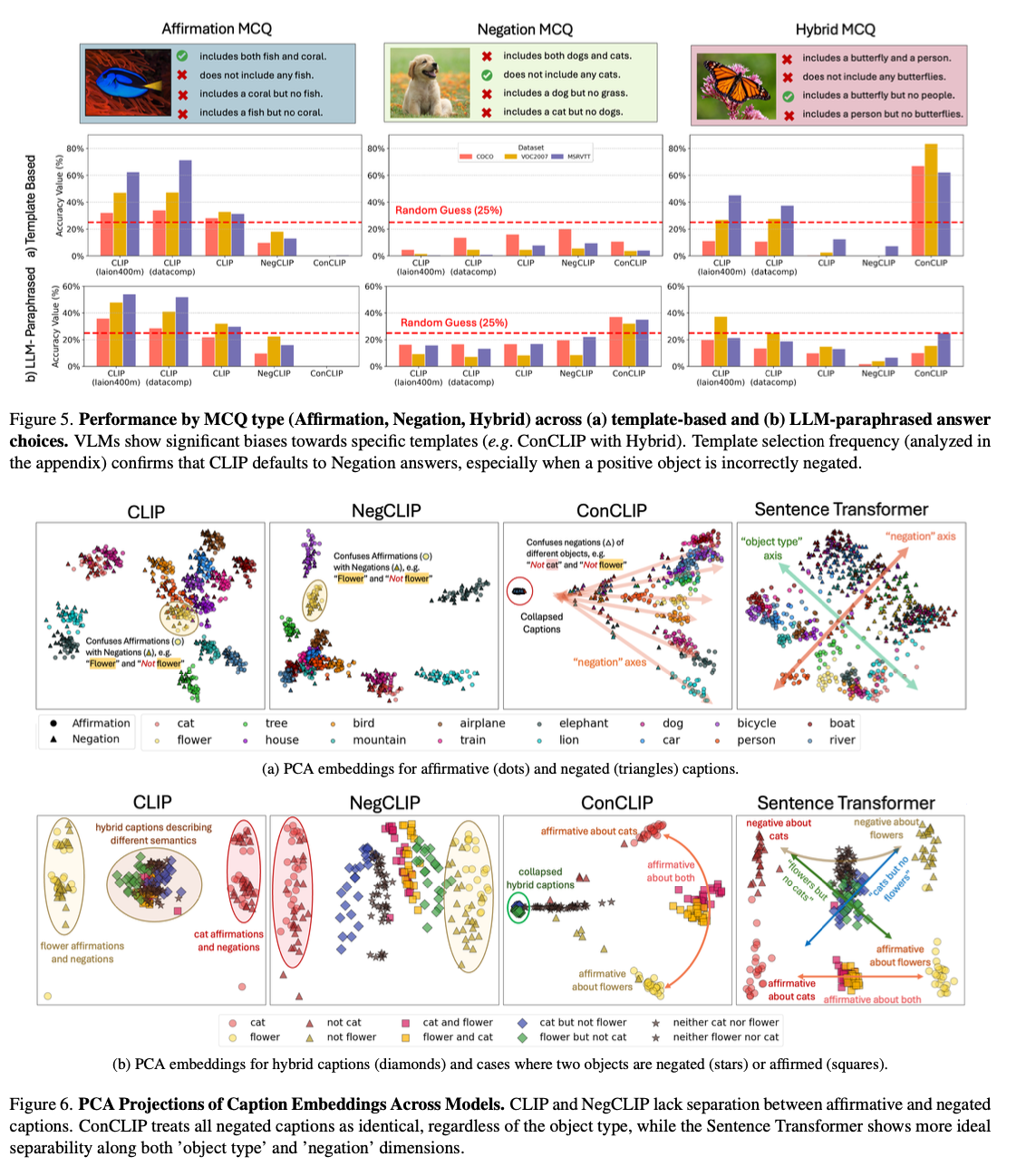
NegBench addresses a critical gap in VLMs by being the first work to address their inability to understand negation. It brings significant improvements in retrieval and comprehension tasks by combining various negation examples in training and testing. Such developments pave the way for more robust AI systems capable of understanding different languages, with important implications for critical domains such as medical diagnosis and semantic content retrieval.
Check it out Paper and Code. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio extends with vision models, new language models, embeddings and LoRA (Promoted)
Aswin AK is a consultant at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, which brings a strong academic background and practical experience in solving real-life domain challenges.
📄 Meet 'Height': Independent project management tool (Sponsored)
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


