This AI Paper Introduces Virgo: A Large Multimodal Language Model for Slow Advanced Thinking

Artificial intelligence research has steadily progressed towards creating systems capable of complex reasoning. Multimodal large-scale linguistic models (MLLMs) represent an important advance in this journey, combining the ability to process text and visual data. These programs can deal with complex challenges such as mathematical problems or graphical reasoning. By allowing AI to bridge the gap between processes, MLLMs expand the scope of their application, providing new opportunities in education, science, and data analysis.
One of the main challenges in developing these systems is to integrate visual and written thinking seamlessly. Traditional macro-language models excel at processing text or images but fall short when tasked with integrating these modes of thought. This limitation hinders their performance in various tasks, especially in situations that require extended and deliberate thought processes, often called “slow thinking.” Addressing this issue is important to develop MLLMs for practical applications where multimodality thinking is important.
Current approaches to developing thinking skills in MLLMs are based on two broad strategies. The first involves using systematic search methods, such as Monte Carlo tree search, guided by reward models to refine the logic. The second focuses on training LLMs with long-form thinking instructions, often organized as chains of thought (CoT). However, these approaches are mainly focused on text-based tasks, leaving multimodal situations underexplored. Although a few commercial systems such as OpenAI's O1 model have shown promise, their proprietary nature limits access to methodologies, creating a public research gap.
Researchers from Renmin University of China, Baichuan AI, and BAAI have introduced Virgo, a model designed to improve slow thinking in multimodal situations. Virgo was developed by fine-tuning the Qwen2-VL-72B-Instruct model, using a straightforward but innovative approach. This involved training the MLLM using text data considered over a long period of time, a rare choice to transfer inference power to all methods. This approach differentiates Virgo from previous efforts, as it focuses on the inherent thinking capabilities of the LLM core within the MLLM.
Virgo's approach to growth is detailed and deliberate. The researchers selected a data set that included 5,000 long-term thought instruction examples, mostly in math, science, and coding. These instructions were formatted to include systematic thought processes and final solutions, ensuring clarity and repeatability during training. To improve Virgo's capabilities, the researchers selected fine-tuned parameters for LLM and cross-modal interfaces, leaving the interface untouched. This method preserved the visual processing power of the basic model while improving its reasoning performance. In addition, they experimented with filtering themselves, using a fine-tuned model to generate long-term considered visual data, further refining Virgo's multi-dimensional thinking capabilities.
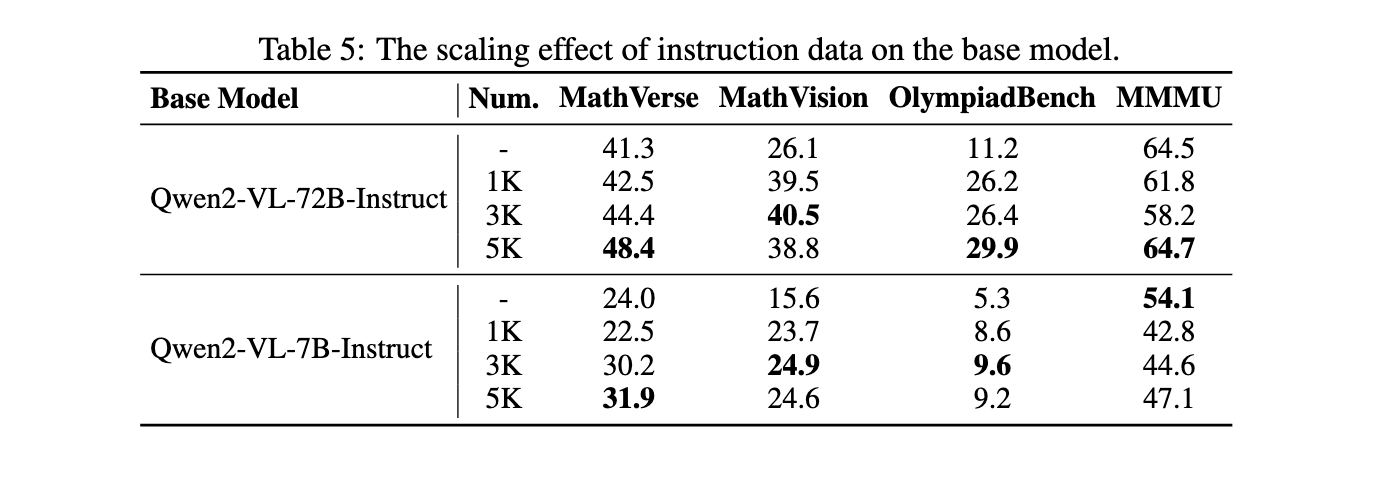
Virgo's performance was evaluated across four challenging benchmarks: MathVerse, MathVision, OlympiadBench, and MMMU. These benchmarks include thousands of multimodal problems, testing the model's ability to reason over text and visual input. Virgo has achieved impressive results, outperforming several advanced models and competing commercial systems. For example, in MathVision, Virgo recorded an accuracy of 38.8%, outperforming many existing solutions. In OlympiadBench, one of the most demanding benchmarks, it achieved a 12.4% improvement over its base model, highlighting its complex reasoning capabilities. In addition, the text-based optimization of Virgo has shown superior performance in extracting the power of slow thinking compared to multi-modal training data. These findings underscore the potential of using textual instruction to develop multimodal systems.
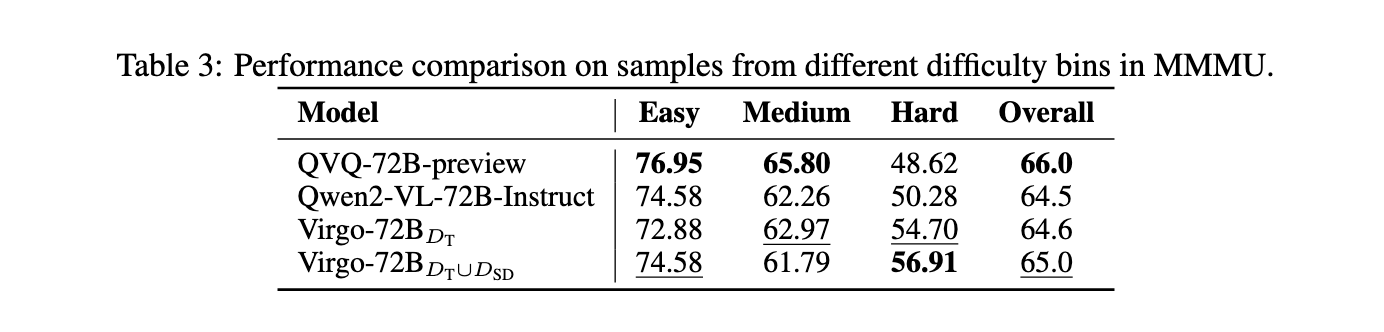
The researchers also analyzed Virgo's performance by classifying results based on difficulty levels within the benchmarks. While Virgo has shown consistent improvement in challenging tasks that require extended thinking, it has seen limited gains in simple tasks, such as those in the MMMU benchmark. This understanding emphasizes the importance of aligning thinking systems to the complexity of the problems they are designed to solve. Virgo's results also revealed that textual reasoning data generally outperformed visual reasoning instruction, suggesting that textual training can effectively transfer reasoning skills in multimodal domains.
By demonstrating an effective and efficient way to develop MLLMs, researchers have contributed greatly to the field of AI. Their work fills a gap in multidisciplinary thinking and opens avenues for future research in refining these systems. Virgo's success demonstrates the transformative power of using long-term considered text data in training, offering a promising solution for developing advanced thinking models. With further refinement and testing, this methodology can drive significant progress in multimodal AI research.
Check it out i Paper and GitHub page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 60k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.
Nikhil is an intern consultant at Marktechpost. He is pursuing a dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is constantly researching applications in fields such as biomaterials and biomedical sciences. With a strong background in Material Science, he explores new developments and creates opportunities to contribute.
✅ [Recommended Read] Nebius AI Studio expands with vision models, new language models, embedded and LoRA (Enhanced)



