
Major Language Models (LLMs) aims to align with people's preferences, to ensure reliable and trustworthy decision-making. However, these models experience biases, logical leaps, and illusions, which make them invalid and harmless for critical tasks involving logical thinking. Logical consistency problems make it impossible to construct logically consistent LLMs. They also use ad-hoc thinking, optimization, and automatic systems, leading to less reliable conclusions.
Current methods of aligning Large Language Models (LLMs) and human preferences depend on them supervised training with data following instructions and reinforced learning from human feedback. However, these methods suffer from problems such as omissions, biases, and logical inconsistencies, thus undermining the validity of LLMs. Much of the development of LLM consistency has therefore been done on simple factual knowledge or simple inclusion within just a few statements while ignoring other, more complex decision-making situations or tasks involving more than one factor. This gap limits their ability to provide coherent and reliable reasoning in real-world applications where consistency is critical.
To examine logical consistency in large linguistic models (LLMs), researchers from at the University of Cambridge again Monash University proposed a global framework for measuring rational consensus by evaluating three key factors: to walk, walking aroundagain the immutability of negation. Transitivity ensures that if the model determines that one item is preferred over the second and the second over the third, it also concludes that the first item is preferred over the third. Commutativity ensured that the judgment of the model remained the same regardless of how the objects were compared.
At the same time, incompatibility and incompatibility were examined for compatibility in handling relationship opposition. These properties form the basis for reliable reasoning in models. The researchers formalized the evaluation process by treating the LLM as a user activity FFF which compared pairs of objects and assigned decisions about relationships. Logical consistency was measured using similar metrics stran(K)s_{tran}(K)stran(K) for to walk again scomms_{comm}scommof walking around. Stran (K)s_{tran}(K)stran(K) quantified transitivity by taking sample subsets of objects and finding cycles in the correlation graph. At the same time, scomms_{comm}scomm tested whether the model's conclusions remained stable when the order of the compared factors was changed. Both metrics range from 0 to 1with higher values indicating better performance.
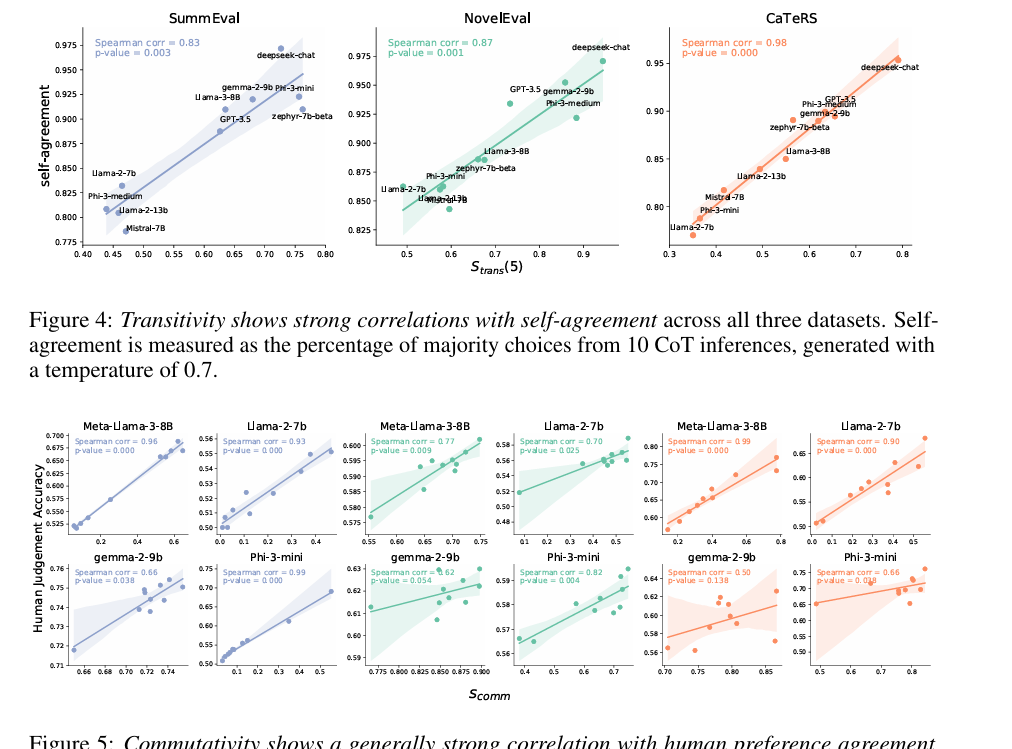
Researchers have applied these metrics to various LLMs, revealing vulnerability to biases such as favoritism and position bias. To address this, they presented a data optimization method and additive methods using rank summation methods to estimate partial or ordered preference ratings from noisy or few pairwise comparisons. This improved logical consistency without compromising alignment with human preferences and emphasized the important role of logical consistency in improving the performance of a logic-based algorithm.
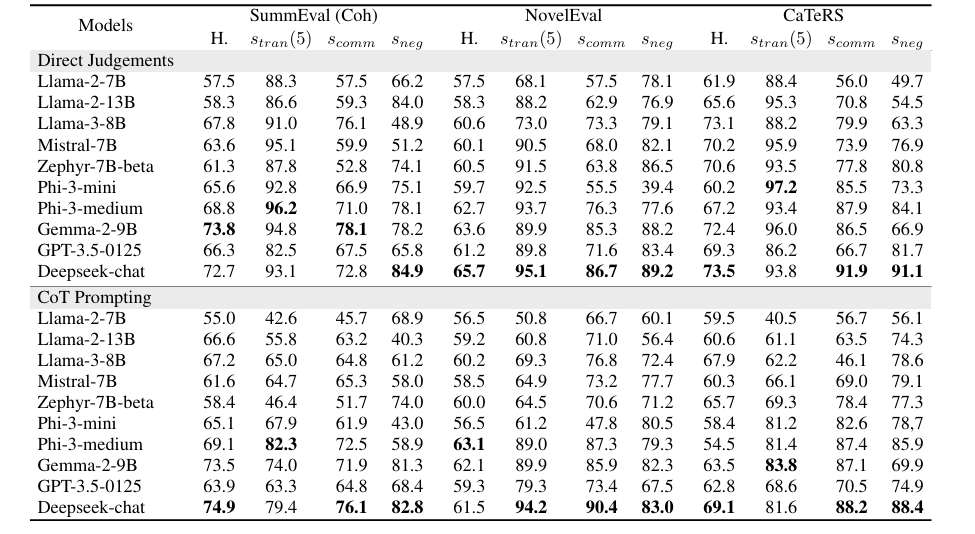
The researchers tested three tasks to assess logical consistency in LLMs: abstract summary, document re-arrangement, again temporal event order using data sets such as SummEval, NovelEvalagain CATERS. They examined flexibility, flexibility, negation consistency, and personal agreement and commitment. The results showed that the new models liked Deepseek-chat, Phi-3-medium, again Gemma-2-9B it had high reasonable agreement, although this was not significantly related to the accuracy of the person's agreement. I CATERS The data set showed strong consistency, focusing on temporal and causal relationships. Thought chain information has had mixed results, sometimes reducing the likelihood of occurrence due to additional thought cues. Adaptation itself was related to mobility; this shows that consistent reasoning is the basis of logical consistency, and models like Phi-3-medium and Gemma-2-9B have equal reliability for each task, emphasizing the need for clean training data.
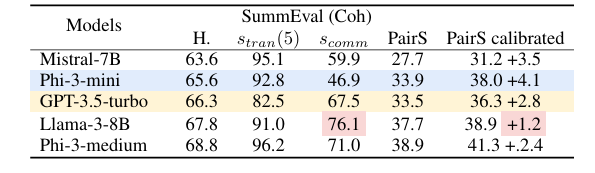
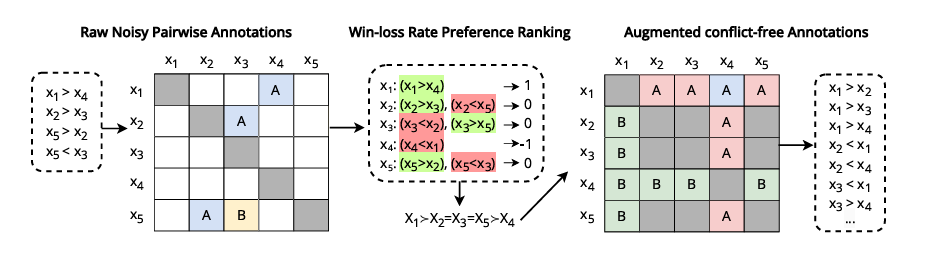
Finally, researchers have shown the importance of logical consistency in improving the reliability of large linguistic models. They presented a method for quantifying important aspects of consistency and described a data cleaning process that reduces the amount of randomness while still being relevant to people. This framework can also be used as a guide for further research on improving the consistency of LLMs and ongoing efforts to implement LLMs in decision-making systems to improve effectiveness and productivity.
Check it out Paper. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 60k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these advanced technologies in the agricultural domain and solve challenges.
✅ [Recommended Read] Nebius AI Studio expands with vision models, new language models, embedded and LoRA (Enhanced)
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


