Meet OSGym: A New OS Infrastructure Framework That Manages 1,000+ Replicas for $0.23/Day Computer Usage Agent Research

Training AI agents that can actually use a computer — open apps, click buttons, browse the web, write code — is one of the toughest infrastructure problems in modern AI. It's not a data problem. It's not a model problem. It's a plumbing problem.
You need to explore hundreds, if not thousands, of full operating system environments with real user interface graphics. Each one needs to use real software. Each one needs to handle unexpected crashes. And you need them all to work simultaneously at a cost that doesn't disrupt a university research lab.
That's the problem'OSGym', a new study from a team of researchers at MIT, UIUC, CMU, USC, UVA, and UC Berkeley, is designed to solve.
What is a Computer Use Agent?
Before unpacking the infrastructure, it helps to understand what a computing agent actually is. Unlike a chatbot that responds to text prompts, a desktop agent looks at a desktop screenshot, decides what to do — click a button, type text, open a file — and performs that action using keyboard and mouse input. Think of it as an AI that can run any software like a human would.
Models like Anthropic's Claude Computer Use and OpenAI's Operator are early commercial examples. Research models such as UI-TARS, Agent-S2, and CogAgent are pushing the boundaries. But training any of these systems requires large amounts of interactive data generated within the actual OS environment – and that's where things get expensive and complicated quickly.
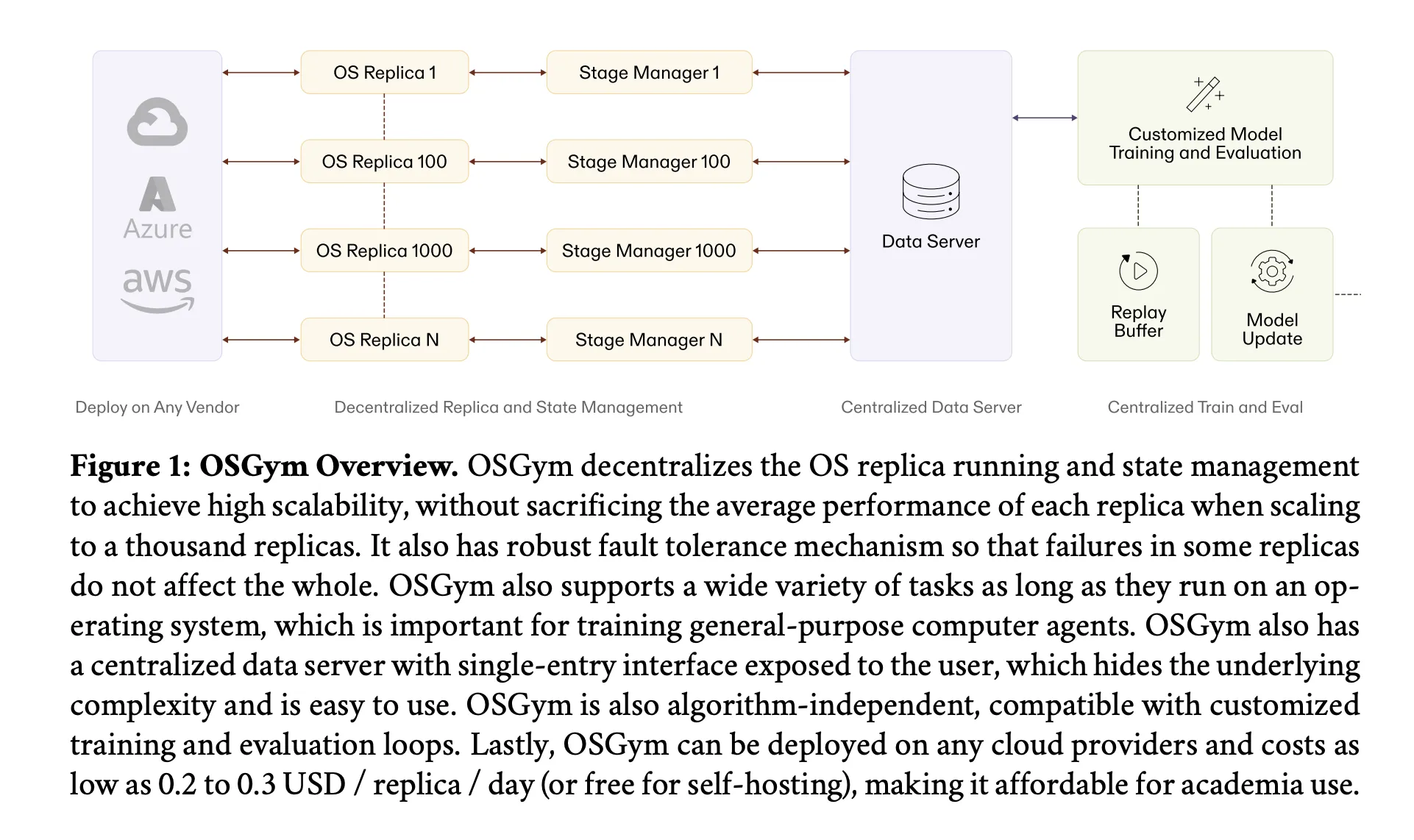
Core Problem: OS Sandboxes at Scale
A coding environment or web browser sandbox is easy to use. A full OS sandbox with a GUI is missing. Each virtual machine needs its own bootable disk (about 24 GB), its own CPU and RAM allocation, and its own display stack. Multiply that by hundreds or thousands of similar instances and you have a resource utilization problem that typical computing budgets can't absorb.
On top of utility costs, there is the issue of reliability. The software crashes. The browser timed out. Requests are frozen. If your training pipeline can handle this failure well, one bad VM can stop a lot of training.
OSGym addresses both problems with four different architectural configurations.
Decentralized OS State Management
The first design choice is about how the system manages the state of each virtualized OS – it keeps track of whether it's healthy, what work is running, and how to find out if something goes wrong.
A naive approach uses a single manager for all simulations. This is one classic point of failure: as the number of instances grows into the thousands, the central manager gets overwhelmed, latency increases, and a single crash can bring the entire system to a standstill. OSGym instead gives every OS replica its own dedicated region manager. Each region manager exposes the public methods identified behind the OpenAI Gym API – reset, stepagain shutdown – but handles its own health monitoring and crash recovery internally. The failure of one analogy cannot spread to any other.
Hardware-Aware OS Replica Orchestration
Here's a subtle detail in this research: if you're running multiple OS emulators on a single server, the bottleneck depends on how many emulators you pack on each machine. With a small number of simulations per server (low K), the system is CPU bound – many simulations fight for processing time. But as you stack more replicas per server (big K), the bottleneck shifts to RAM – and RAM is much cheaper than CPU.
A 32 GB DDR4 RAM module typically costs 10–20% of what a 16-core CPU costs. OSGym uses replicas as Docker containers (using Docker images from OSWorld as a base) rather than full Virtual Machines to minimize each replica further. By choosing servers with higher RAM capacity and using more simulations per machine, the daily cost drops from about $300 for 128 simulations at K=1, to about $30 for K=64 – about $0.234 per simulation per day, a number that fits well within most educational grant budgets.
KVM Virtualization with Copy-on-Write Disk Management
The disk provisioning problem is solved by a file system method called reflink copy-on-write (CoW). Typically, spinning up 128 VM instances would mean replicating a 24 GB base image 128 times – over 3 TB of storage and 30 seconds of rendering time per VM.
OSGym instead uses cp --reflink=always on XFS-formatted NVMe drives. Each VM disk image shares virtual disk blocks with the base image and allocates new blocks only when the VM writes to them. The result: 128 VMs consume 366 GB of virtual disk instead of 3.1 TB – an 88% reduction – and the disk provisioning time drops from 30 seconds to 0.8 seconds per VM, a 37× speedup. Each VM still sees its own 24 GB logical disk running alongside the native CPU.
Robust Container Pool with Multi-Layer Fault Detection
OSGym maintains a pre-heated pool of runners – by default, 128 runners per pool – that are primed before training begins. Rather than creating and destroying VMs as needed, runners are recycled between jobs. Before each VM creation, OSGym reads /proc/meminfo again /proc/loadavg to ensure that the host can safely receive another instance, preventing creation if the available memory falls below 10% or below 8 GB altogether. Each container is memory-limited to 6 GB to prevent over-provisioning under explosive conditions.
The program also tunes Linux kernel parameters that would have caused silent failures with high compatibility – for example, fs.aio-max-nr increased from 65,536 to 1,048,576, too fs.inotify.max_user_instances from 128 to 8,192. Error detection works at two levels: at the step level, each action gets 10 retries automatically; at the task level, if a runner fails permanently, the task is automatically reassigned to a new runner.
Integrated Workflow and Central Database Server
The two most important design elements for devs include OSGym: every task follows a four-stage integrated execution flow – Configure, Reset, Use, Measure – regardless of the software or domain involved. This configuration makes it easy to add new types of operations without changing the surrounding infrastructure.
Above the replica layer, the central data server Python class exposes a single integrated interface (__next__ again async_step) which hides all the complexities of communicating with the country manager line. The integrated step method is asynchronous, meaning that the training loop is never blocked while waiting for the OS simulations to complete their actions.
How Numbers Look in Use
Using 1,024 parallel OS replicas, the system collected trajectories for all ten task categories – including LibreOffice Writer, Calc, and Impress, Chrome, ThunderBird, VLC, VS Code, GIMP, OS system configuration, and multi-application workflow – at approximately 1,420 trajectories per minute, without paralysis which is 65411. Every dataset costs $43 for cloud computing.
The research team then used that data to optimize Qwen2.5-VL 32B with supervised optimization, followed by reinforcement learning using an online PPO-based asynchronous pipeline (200 steps, cluster size 64, learning rate 1e-6). The resulting model achieved a 56.3% success rate in the OSWorld-Verified benchmark — competing with existing 32B parameter base model methods without task-specific tuning.
Key Takeaways
- Training computerized agents is primarily an infrastructure issue: Full OS sandboxes with GUIs are much heavier than coding or browser environments – each VM requires ~24 GB of disk, dedicated CPU and RAM, and display stack. Without careful optimization, scaling in hundreds of simulations is unaffordable for most academic labs.
- RAM is a smarter benchmark than CPU: OSGym's hardware-aware orchestration reveals that stacking multiple simulations per server shifts the bottleneck from CPU to RAM – and RAM is 5–10× cheaper. This single insight reduces the cost of each replica from ~$2.10/day to as low as $0.23/day.
- Copy-and-write disk management eliminates the storage wall. Using XFS reflink CoW (
cp --reflink=always), OSGym reduces physical disk usage by 88% and speeds up VM disk provisioning by 37 × – turning a 3.1 TB, 30-second VM problem into a 366 GB, 0.8-second problem. - Fixed-state management is the key to stability at scale. Giving each instance of the OS its own dedicated regional manager means that failures remain isolated. Even starting from a completely crashed state, OSGym automatically restores all documents in a short window – essential for long-term uninterrupted training activities.
- Agent research for computing at scale in education is now financially viable. With 1,024 simulations generating 1,420 trajectories per minute and a complete dataset costing just $43 in cloud computing, OSGym brings the infrastructure costs of training general-purpose computing agents within reach of university research budgets.
Check it out Paper here. Also, feel free to follow us Twitter and don't forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



