NVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1B

Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The student learns from the teacher’s full output probability distribution over tokens, not just correct answers. This is done via per-position Kullback–Leibler (KL) divergence over next-token probability distributions.
This formulation requires a shared tokenizer. A practitioner committed to Llama-3.2-1B cannot leverage stronger teachers with incompatible tokenizers — such as Phi-4-mini or Qwen3-4B — because token positions do not correspond across vocabularies. This also prevents multi-teacher distillation across tokenizer families.
NVIDIA researchers introduced X-Token, a logit-distribution-based method for cross-tokenizer KD (Knowledge distillation). It operates as a drop-in replacement for the standard KD loss, requiring no auxiliary trainable components and no architectural changes.
The Problem X-Token is Solving
Two prior approaches dominate cross-tokenizer KD. ULD (Universal Logit Distillation) sidesteps vocabulary alignment by rank-sorting both distributions and minimizing L1 distance. It discards token identity entirely. GOLD adds span alignment and a hybrid loss. It partitions tokens into a 1-to-1 string-matched common subset, trained with KL divergence, and an uncommon remainder, trained with ULD-style rank matching. GOLD is the current state of the art.
The research team identifies two structural failures in GOLD’s design:
Failure 1: Uncommon-token failure– When tokenizers fragment text differently, critical tokens fall into the unmatched uncommon subset. Llama-3 packs multi-digit numbers as single tokens — “201” is one token. Qwen3 splits them digit by digit: “2”, “0”, “1”. Under GOLD, all 1,100 of Llama’s two- and three-digit numerals (100 two-digit, 1,000 three-digit) fall into the uncommon set when Qwen3-4B is the teacher. Those tokens receive two types of harmful signal: identity-agnostic noise from rank-based ULD matching, and suppressive gradients from the common-KL term acting through the full-vocabulary softmax. The result: GSM8k accuracy drops to 2.56 under GOLD with Qwen3-4B, compared to 12.89 for same-tokenizer KD from a weaker Llama-3.2-3B teacher.
Failure 2: Over-conservative matching– GOLD uses strict string equality to define the common subset. A student token Hundreds corresponds to teacher tokens Hund followed by reds under teacher-side re-tokenization, but strict matching discards this pair. Useful alignment signal is lost even when the correspondence is well-formed.
These two failures require opposite remedies: eliminate the partition when critical tokens are misaligned, and relax it when alignment is structurally sound.
How X-Token Works
X-Token has three components: span alignment, a projection matrix W, and two complementary loss formulations — P-KL and H-KL.
Span Alignment
Teacher and student tokenizers produce sequences of different lengths for the same text. X-Token uses dynamic-programming (DP) span alignment, grouping tokens into chunks where each chunk-pair decodes to the same underlying text substring. A chain-rule merge then combines per-token probabilities within each chunk into a single chunk-level distribution for use in the distillation loss. The alignment is cached per sequence and adds no per-step training overhead.
The research team also identifies a failure in TRL’s surface-substring alignment, which is used in TRL’s GOLD trainer. TRL accumulates per-side decoded buffers and flushes only when both buffers match as equal raw strings. A byte-level disagreement — such as Llama-3 auto-prepending
The Projection Matrix W
After alignment, teacher and student distributions still operate over different vocabularies. The projection matrix W ∈ ℝVS|×|VT| maps each student token to a weighted combination of teacher tokens, bridging the vocabulary mismatch.
W is constructed deterministically in two passes:
Pass 1 (exact-match): For every (student token, teacher token) pair whose decoded strings match after canonicalization, set W[s, t] = 1. Canonicalization unifies space prefixes (Ġ, _, ␣), newlines, byte-fallback tokens of the form <0xHH>, and model-specific special tokens across tokenizer families.
Pass 2 (multi-token rule): For each student token without an exact match, re-tokenize its decoded text under the teacher tokenizer. If the resulting sequence has length ≤ 4, assign exponentially-decayed weights: W[s, τᵢ] = β·γⁱ with (β, γ) = (0.9, 0.1). A length-2 span receives normalized weights (0.909, 0.091). A length-3 span receives (0.9009, 0.0901, 0.0090). A length-4 span receives (0.9000, 0.0900, 0.0090, 0.0009). The leading sub-token receives the highest weight because it typically carries the most informative probability mass — for example, “_inter” in [“_inter”, “national”] or “_20” in [“_20”, “24”].
Each row is truncated to its top-4 entries and row-normalized. Because each row of W is non-negative and sums to 1, left-multiplication by W⊤ is probability-preserving: if pS is a probability vector, W⊤pS is also a valid probability vector over VT. W is constructed once before training and can optionally be jointly refined with the student under P-KL.
P-KL: Addressing Erroneous and Suppressive Gradients
P-KL removes the partition entirely. It projects the student distribution p̂S(k) into teacher vocabulary space via W:
There is no uncommon set, so rank-based ULD noise is eliminated. The suppressive gradient problem is also eliminated: the projection routes the student’s probability mass for “201” directly onto {2, 0, 1} in the teacher vocabulary via W.
The research team formally proves (Proposition 1) that GOLD’s common-KL term induces non-negative gradients on every uncommon student logit. The gradient on an uncommon student logit j is: ∂ℒcommon/∂zj = pS[j] · MC(T), where MC(T), is the teacher probability mass on the common subset. Under gradient descent, this always drives zj downward — suppressing every uncommon token’s probability regardless of the ground-truth token.
H-KL: Relaxing the 1-to-1 Matching
H-KL applies when the partition is structurally sound — that is, when critical tokens land in the common subset. In that case, GOLD’s direct KL on identity-aligned pairs delivers sharper per-pair supervision than P-KL’s projection, which blends student probability mass across multiple teacher tokens. The opportunity is to make the partition less wasteful by relaxing the strict string-equality criterion.
H-KL retains GOLD’s hybrid loss structure but expands the common set C using W. For each student token s, it selects the top-ranked teacher token t* = argmax_{t’∈V_T} W[s, t’], and adds (s, t*) to C. Exact matches are preserved since they receive weight 1 in W, the highest possible. Near-equivalent pairs like (Hundreds, Hund) — excluded by GOLD — are now admitted. The expanded C feeds the same hybrid loss: direct KL on common pairs, ULD on the remainder.
Selecting Between P-KL and H-KL
The selection uses a coverage audit over token categories in the student vocabulary. For math tasks, multi-digit numerals are the critical category. Table 8 in the research paper shows: under Qwen3-4B, 0 out of 100 two-digit Llama numerals and 0 out of 1,000 three-digit Llama numerals appear in C. Under Phi-4-mini-Instruct, all 100 two-digit and all 1,000 three-digit numerals appear in C. ASCII punctuation and single-digit numerals are fully covered in both cases.

The rule: use P-KL when critical tokens fall outside C (Qwen3-4B), and H-KL when the partition is sound (Phi-4-mini-Instruct). Table 2 in the research paper shows the mode reversal is sharp: P-KL outperforms H-KL by +3.55 avg. on Qwen3-4B, while H-KL outperforms P-KL by +1.68 avg. on Phi-4-mini.

Multi-Teacher Distillation
X-Token extends to multiple teachers. Each teacher has its own projection matrix W_m and loss selection. For same-tokenizer teachers, standard token-level KL is used. The multi-teacher loss aggregates per-teacher losses with weights αm:
The research team evaluates static and confidence-adaptive weighting schemes. Confidence-adaptive variants compute α_m from cross-entropy, Shannon entropy, or maximum predicted probability of the teacher’s distribution. Static weighting outperforms adaptive schemes in both multi-teacher setups evaluated.

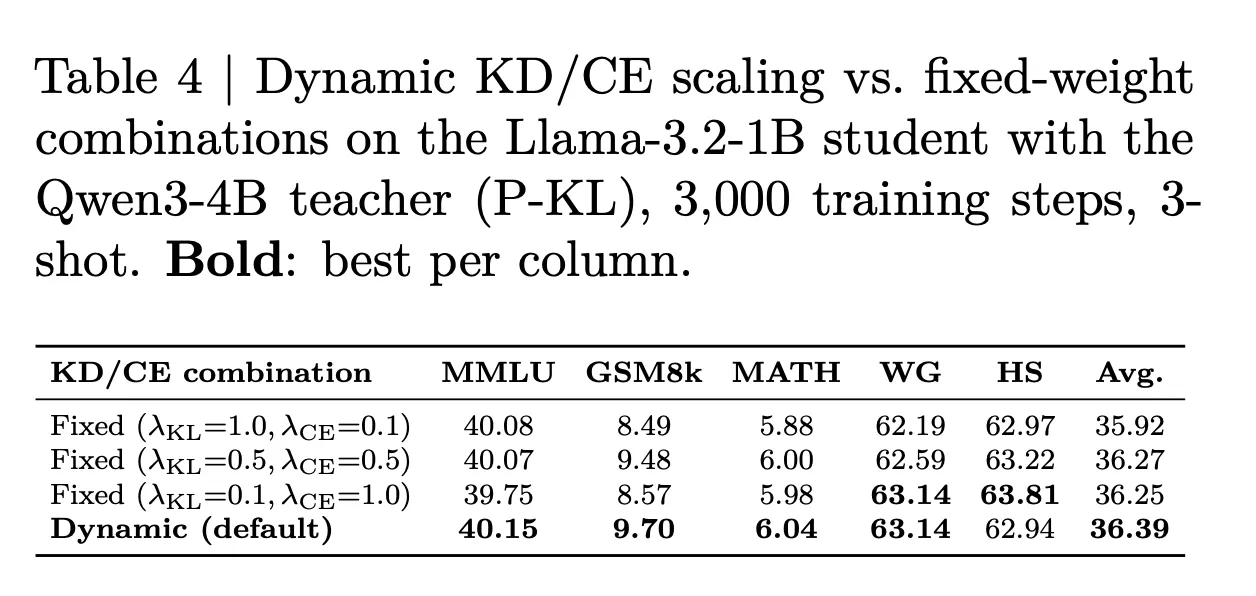
Dynamic KD/CE Scaling
Training combines the distillation loss ℒKD with next-token cross-entropy ℒCE. Because these terms differ in magnitude and shift during training, X-Token rescales the KD term at each step to match the scale of ℒCE:
where sg(·) is stop-gradient. Table 4 in the paper shows dynamic scaling outperforms three fixed-weight settings (KD-heavy, balanced, CE-heavy) on the Qwen3-4B (P-KL) pair.
Experiments and Results
Student: Llama-3.2-1B. Teachers: Llama-3.2-3B (same tokenizer), Qwen3-4B, and Phi-4-mini-Instruct. Training data: NemotronClimbMix dataset, 30,000 steps, batch size 768, context length 4096. Optimizer: AdamW, learning rate 5×10⁻⁵, 5% warmup with cosine decay, weight decay 0.1, gradient clipping 1.0. Each experiment is feasible on a single NVIDIA H100 GPU; the research team used 128 H100s to speed up iteration.
Evaluation: 3-shot accuracy on MMLU, GSM8k, MATH-Hendrycks, Winogrande, and HellaSwag.
Key results:
| Setting | Method | Avg. |
|---|---|---|
| No distillation | Llama-1B (base) | 33.96 |
| No distillation | Continued pre-training | 36.63 |
| Same tokenizer | Llama-3B → 1B (KL) | 38.40 |
| Cross-tokenizer | Qwen-4B, ULD | 36.77 |
| Cross-tokenizer | Qwen-4B, GOLD | 35.03 |
| Cross-tokenizer | Qwen-4B, X-Token (P-KL) | 38.85 |
| Cross-tokenizer | Phi-mini, ULD | 38.31 |
| Cross-tokenizer | Phi-mini, GOLD | 38.66 |
| Cross-tokenizer | Phi-mini, X-Token (H-KL) | 39.18 |
| Multi-teacher | Phi-mini + Llama-3B (X-Token) | 40.48 |
On Qwen-4B (P-KL regime): GOLD reaches 35.03 avg., below even continued pre-training without a teacher (36.63). This confirms the partition is actively harmful when critical tokens are misaligned. Pure ULD (36.77) already improves over GOLD, indicating the partition is the primary failure source. P-KL further improves to 38.85 avg. (+3.82 over GOLD). GSM8k alone moves from 2.56 to 15.54, surpassing same-tokenizer KD from Llama-3.2-3B (12.89) on that benchmark.
On Phi-mini (H-KL regime): GOLD reaches 38.66 avg. — a reasonable baseline where the partition is structurally sound. H-KL improves to 39.18 avg. (+0.52 over GOLD). P-KL applied to Phi-mini drops to 37.50 avg., confirming that the wrong loss mode hurts even when W is available.
Multi-teacher: Phi-mini (H-KL, α=0.8) + Llama-3B (standard KL, α=0.2) under static weighting reaches 40.48 avg. This is +2.08 over same-family KD from Llama-3B alone, and +1.30 over the best single cross-tokenizer result (39.18). Combining Phi-mini + Qwen-4B — two teachers with overlapping reasoning strengths — scores only 38.49, below the best single teacher. Adding Qwen-4B as a third teacher yields 40.15, with math/reasoning degrading (GSM8k 20.39 → 19.18) while commonsense improves slightly. Teacher complementarity, not teacher count, drives gains.
Strengths and What to Watch
Strengths:
- The suppressive gradient problem in GOLD’s hybrid loss is formally proved (Proposition 1), not just observed empirically
- W is constructed rule-based from tokenizer strings alone; no training data or learned parameters needed at initialization
- Dynamic KD/CE scaling removes the need to tune fixed loss weights; it outperforms three fixed-weight baselines in ablations
- Multi-teacher extension adds no architectural changes; each teacher uses its own W_m and appropriate loss
- The coverage audit for P-KL vs H-KL selection is a defined, reproducible criterion based on per-category token retention in C
What to Watch:
- Experiments use only Llama-3.2-1B as the student under continued pre-training; larger students and instruction-tuned settings are not evaluated
- Only three teacher pairs are tested; low-overlap tokenizer families (SentencePiece, byte-level BPE) are left for future work
- Static weighting outperforms confidence-adaptive weighting in all tested multi-teacher setups, but why?
- The multi-token rule in Pass 2 skips student tokens whose decoded text re-tokenizes to sequences longer than 4 under the teacher; those rows remain zero in W
Marktechpost’s Visual Explainer
Key Takeaways
- X-Token identifies two distinct, opposite failure modes in GOLD: uncommon-token suppression (fix: remove the partition with P-KL) and over-conservative matching (fix: relax it with H-KL).
- The projection matrix W is built rule-based from tokenizer strings before training; it can optionally be jointly refined with the student for additional gains.
- P-KL on Qwen3-4B improves over GOLD by +3.82 avg. and recovers GSM8k from 2.56 to 15.54.
- Multi-teacher distillation gains (+1.3 over single-teacher) come from teacher complementarity, not just from adding more teachers.
- Loss mode selection (P-KL vs H-KL) is determined by a coverage audit on token categories; applying the wrong mode reverses the ranking.
Check out the Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us



