Meta Ai introduces Paretoq: Computer's frame of the lower 4-bit amount in large modes of language

Since deep study models continue to grow, the construction of the machine's learning models is important, and the need for practical jumping methods have become stronger. The lower quote is a means reduced the model size while trying to keep accuracy. Investigators have been determining the best width of improving proper performance without compromising performance. Different studies have considered different settings for a thick diameter, but conflicting conclusions are emerging due to the absence of regular assessment framework. This continuous attainment affects the development of the maximum articulation models, determine whether it is possible to be used in the pressed environments.
The biggest challenge for the smallest of the smallest to indicate a complete trade between computational and accuracy. The debate where the most effective width is constantly in solidism. However, the previous research has been unpunished to compare different settings to reduce the size, resulting in non-relevant conclusions. This gap of information is accompanied by establishing reliable laws of measurement of the minimum accuracy of accuracy. In addition, achieving stable training in the lowest preparation creates a technical problem, as low-bit models often hear the highest shifts representing the top partners.
Methods of using prices vary from working and performance. After training the model with full accurate accuracy, Post-Training (PTQ) is applied to the construction of the amount, making it easier to reduce the corruption of lower scope. Training of a decent amount (Qat), on the other hand, includes the construction of training, which allows modeling models effectively. Some strategies, such as the readable amount and combined combined strategies, inspected to confirm the balance between accuracy and model size. However, these methods do not have a universal structure of formal assessment, making it difficult to compare their performance under different circumstances.
Inactive investigators silence Partoq, a formal framework for combining 4 smaller strategies. This framework allows strong comparisons into different range settings, including 1-bit, 1.58-bit, 2-bit, and 4-bit quality. By evaluating training schemes and the functions of the specified value, the Paretoq reaches advanced accuracy and efficiency of previous paths. Unlike previous works that work best at certain levels, Paretoq establishes the consistent test process directly compared prices.
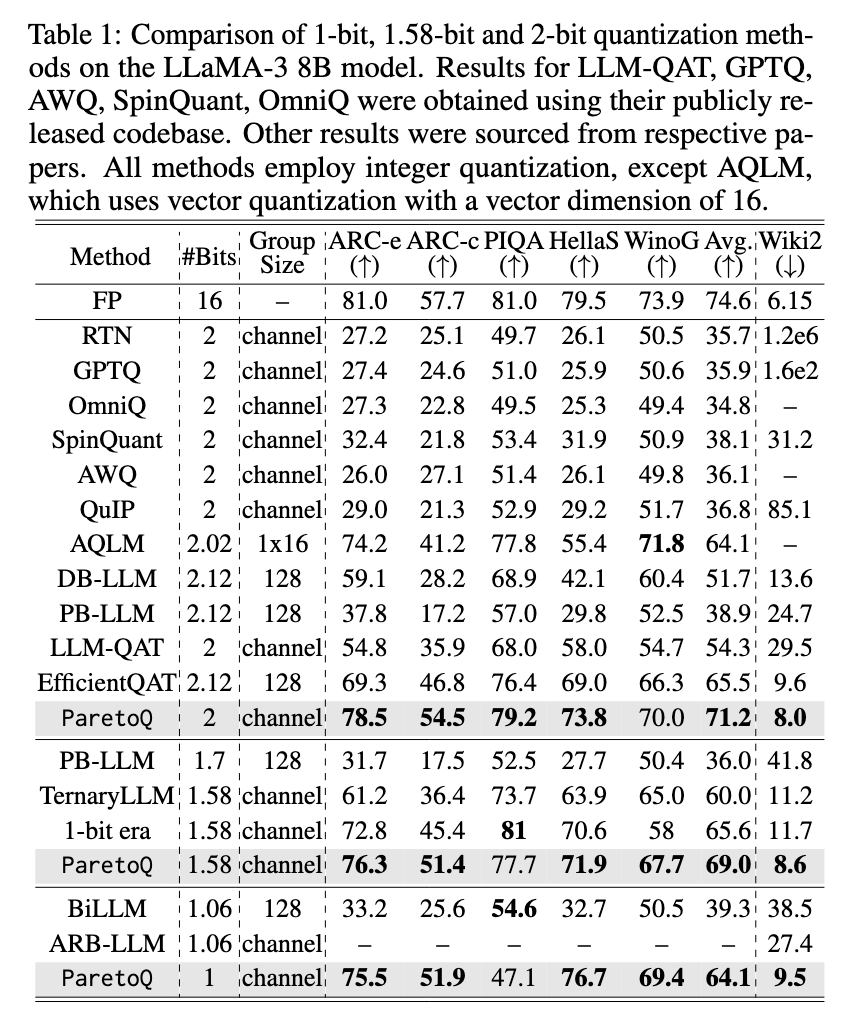
Paroq uses the training strategy for the fair value of reducing the loss of accuracy while storing the efflion efficiency. The framework cleans the BIT functions to find the sensitive from this study of the unique transformation of the stored learning between 2-bit prices and 3. Models are trained 3 accuracy and high storage such as their pre-training distribution, and 2-bit or low-bolters are trained. In order to overcome this challenge, the framework has formally organized the amount of grid, training, and specialized learning strategies.
The broader assessment guarantees the highest performance of paretoq in existing capacity. The 600M-parameter model is enhanced using Paretoq APPERPORMS TERNERY 3B-parameter modern 3B-parameter with accuracy while using only one five of the parameter. Studies show that 2 minor formation has achieved the development of 1,8% over 4-bit model of the same size, establishing its performance as a common 4-bit method. In addition, Paretoq enables more friendly use, which is prepared for 2-bit CPUs earning high speed and memory operation compared to 4-bit value. The test is also revealed that Terrerry models, 2-bit and 3
The acquisition of this study provides a solid basis for doing well less than a small language formulation of language. In submitting a structured framework, research deals with the challenges of commercial trading and performing well-performance. The results show that while the lowest rating is valid, 2-bit rate and 3-bit currently provides the best balance between work and efficiency. Future progress on hardware support for computer slowly will improve the effectiveness of these methods, making the proper submission of large machine learning models in the most pressed machines.
Survey the paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Record Open-Source Ai Platform: 'Interstagent open source system with many sources to test the difficult program' (Updated)
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel



