Meet Search-o1: An AI Framework That Integrates Agentic Search Workflows into o1-like LRM Consulting Process to Achieve Increased Autonomy

Major models of thinking they are developed to solve complex problems by breaking them down into small, manageable steps and solving each step individually. Models are used to reinforce learning to develop their thinking skills and develop more detailed and logical solutions. However, although this method is successful, it has its challenges. Overthinking and error from missing or insufficient information comes from an extended thought process. Gaps in understanding can disrupt the entire chain of reasoning, making it difficult to reach accurate conclusions.
Traditional approaches to large inference models aim to improve performance by increasing the size of the models or increasing the training data during the training phase. Although experimental time scales show potential, current methods rely heavily on static, parameterized models that can use external information when internal understanding is insufficient. Strategies such as policy reward combinations and Monte Carlo Tree SearchDeliberate compilation of errors, and data abstraction improves thinking but fails to internalize or develop thinking skills fully. Recovery of advanced generation (RAG) systems that address some limitations by incorporating external information retrieval but strive to incorporate the robust reasoning capabilities seen in advanced models. These gaps reduce the ability to solve complex, knowledge-intensive tasks effectively.

To solve the challenge of multi-step reasoning tasks that require external knowledge, researchers from Renmin University of China again Tsinghua University proposed i Search-o1 frame. The framework combines the task instructions, questions, and returned information documents into a coherent discussion thread to find solutions and logical responses. Unlike traditional models that combat information loss, Search-o1 extends the retrieval-augmented production method by adding a Reason-to-documents module. This module consolidates the long information returned into precise steps, ensuring a logical flow. The iterative process continues until a complete chain of reasoning and a final answer are formed.
The framework was compared to vanilla logic and basic retrieval-enhanced methods. Vanilla reasoning tends to fail when information gaps arise, while basic advanced methods find overly detailed and redundant documentation, disrupting the coherence of reasoning. The Search-o1 framework avoids this by creating searches on the fly whenever needed, extracting documents, and converting them into clear and related thought steps. The agent method is another server that ensures the integration of relevant information, and Reason-Within-Documents appears to be compatible, which is why it keeps the thinking more accurate and stable.
The researchers tested the framework in two categories of activities: challenging thinking tasks again open-domain question-answer (QA) activities. Challenging thinking tasks are included GPQAQA dataset for multiple choice science PhD level; statistical benchmarks such as MATH500, AMC2023again AIME2024; again LiveCodeBench to test coding skills. Open source QA activities have been tested using similar datasets Natural Questions (NQ), TriviaQA, HotpotQA, 2WikiMultihopQA, MuSiQueagain Bamboogle. The evaluation involved a comparison with basic methods, including direct reasoning methods, augmented-retrieval-augmentation reasoning, and the Search-o1 framework proposed by the researchers. Tests were performed under different conditions using a fixed setup, incl QwQ–32B– Preview the model as a spine and Bing Web Search API to retrieve.
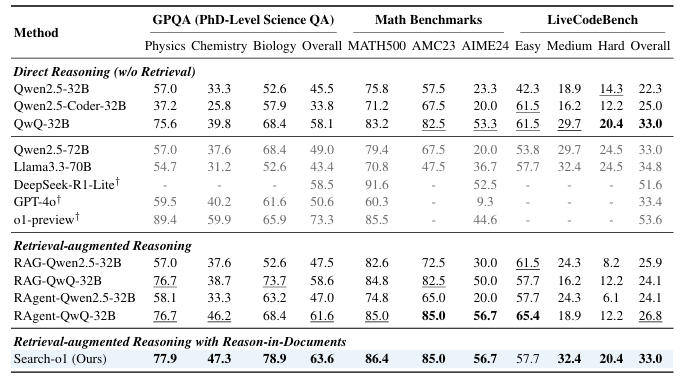
Results he showed that QwQ-32B-Preview he excelled in all thinking tasks, surpassing great models like Q2.5-72B again Llama3.3-70B. Search-o1 less effective recovery methods like RAgent-QwQ-32B with significant convergence and information pooling benefits. For example, on average, Search-o1 is skipped RAgent-QwQ-32B again QwQ-32B with 4.7% again 3.1%respectively, and achieve a 44.7% better than similar smaller models Q2.5-32B. Comparison with human experts in GPQA The expanded set revealed Search-o1's superiority in integrating reasoning strategies, especially in science-related tasks.
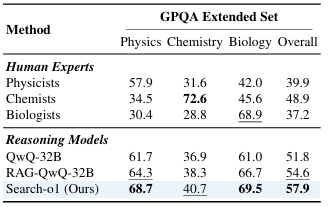
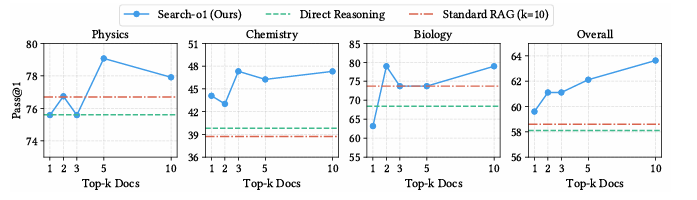
In conclusion, the proposed framework addressed the problem of lack of knowledge in large-scale reasoning models by incorporating an augmented-generation Reason-in-Documents module to allow better use of external knowledge. This framework can be the basis for future research to develop retrieval systems, document analysis, and intelligent problem solving in all complex domains.
Check it out Paper and GitHub page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these advanced technologies in the agricultural domain and solve challenges.
✅ [Recommended Read] Nebius AI Studio expands with vision models, new language models, embedded and LoRA (Enhanced)



