Meet Harness-1: A 20B Retrieval Subagent Trained by Reinforcement Learning Inside the Stateful Search Harness at gpt-oss-20b

Most of the search agents are trained as policies over the growing text. The model determines the search method. It must also remember what it saw, what evidence was important, and what it said was checked. A team of researchers from the University of Illinois Urbana-Champaign, UC Berkeley, and Chroma argue that this is asking too much. Reinforcement learning ends up improving both search decisions and general bookkeeping at the same time.
Their answer is Wires-120B retrieval subagent built into gpt-oss-20b. It was trained by reinforcement learning within a sophisticated search harness. The harness handles the bookkeeping. The policy stores semantic decisions. Weights and code of strings are released publicly.
What Is Harness-1 Actually
Harness-1 produces a standard set of documentation for the response model below. It does not answer the questions itself. It operates within a state machine harness centered on each of the WORKINGMEMORY pieces.
Each curve acts as a loop. The harness provides a unified search mode and recent actions. The model outputs one built-in verb. The harness operates, reviews the situation, and provides the following observations.
The Stateful Harness: Outputs in Policy
The research team calls their goal logical loading. The policy determines what to search, select, and validate, and when to stop. The harness maintains a state that can be restored to those decisions.
That situation includes several pieces. The candidate pool consists of compressed, extracted documents. The selected set marked by importance is the final result, which is included in 30 documents. Tags take four values: very_high, high, fair, or low. A full-text store stores all returned episodes without prompts.
The evidence graph adds structure. A regex extractor scans each passage for proper nouns, years, and dates. The harness then provides common entities, bridge scripts, and singletons. Bridge documents contain two or more common entities. Singletons appear in a single document and suggest tracking clues.
The policy works through eight instruments. These are fan_out_search, search_corpus, grep_corpus, read_document, review_docs, curate, verify, and end_search. Search results are filtered by phrase-BM25, which keeps the top four phrases. Two-level subtraction removes duplication with episode ID and content fingerprinting.
One design option deals with a cold start. The first successful search produces a selected seed for a selected set with eight times the results at the appropriate value. The policy then promotes strong documents and removes weak ones. This changes the work from beginning to development.
The research team mentions three requirements for a trainable harness. This is a warm-hearted consideration, a united country offering, and a motivation to preserve diversity. Harness-1 uses all three.
How to Train
The training splits in the same line as the harness. Supervised fine-tuning teaches the model to use the interface. Reinforcement learning improves search decisions over an attended situation.
One instructor, GPT-5.4, works live inside a full harness. After filtering, 899 trajectories remained for SFT. The model uses LoRA at a level of 32 for three epochs. Step-550 checkpoint initializes RL.
RL uses CISPO on policy with a 40-turn cap and terminal reward only. It only trains on SEC questions. Groups with similar rewards were dropped from the gradient. Training began on Tinker.
The award distinguishes the acquisition of the selected. It also adds the bonus of tool versatility. Besides that bonus, the agent folds to be searched repeatedly. Selective recall then plateaus around 0.53. As a bonus, the variance is stable and the recall reaches about 0.60.
The Benchmark Case
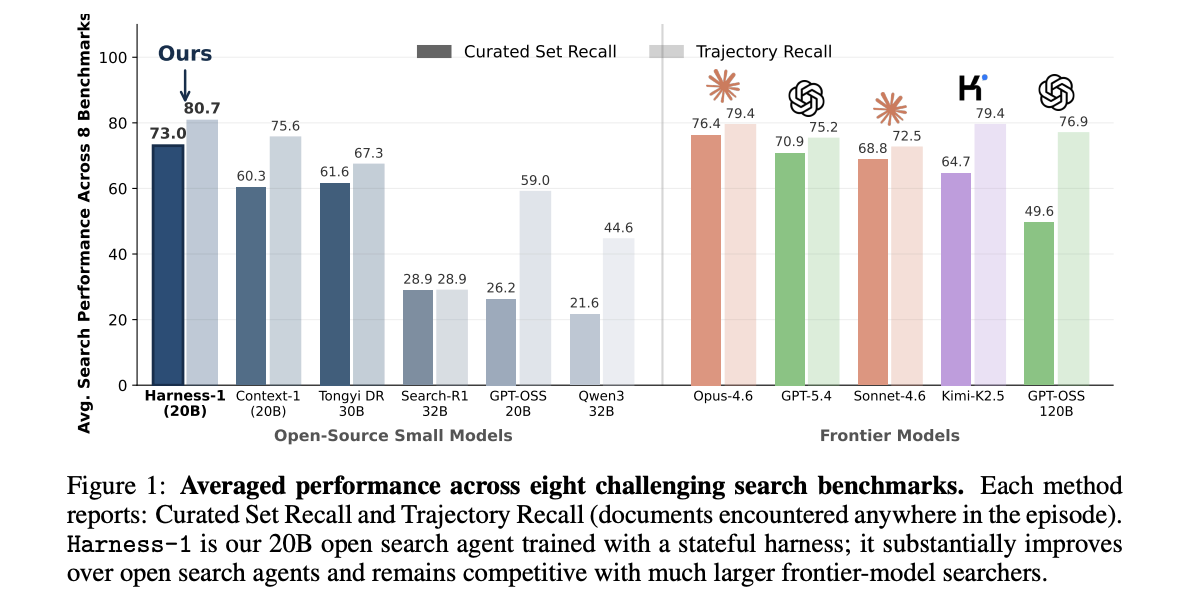
Harness-1 was tested on eight benchmarks including web, financial, proprietary, and multi-hop QA. The primary metric is selective recall: the coverage of relevant documents in the final set. Trajectory recall evidence is calculated anywhere in the episode.
| Model | Kind of | Central Selective Recall | Avg Trajectory Recall |
|---|---|---|---|
| Binding-1 (20B) | Open a small one | 0.730 | 0.807 |
| Tongyi DeepResearch 30B | Open a small one | 0.616 | 0.673 |
| Context-1 (20B) | Open a small one | 0.603 | 0.756 |
| Search-R1 (32B) | Open a small one | 0.289 | 0.289 |
| GPT-OSS-20B | Open a small one | 0.262 | 0.590 |
| Qwen3 (32B) | Open a small one | 0.216 | 0.446 |
| Opus-4.6 | The Frontier | 0.764 | 0.794 |
| GPT-5.4 | The Frontier | 0.709 | 0.752 |
| Sonnet-4.6 | The Frontier | 0.688 | 0.725 |
| For me K2.5 | The Frontier | 0.647 | 0.794 |
| GPT-OSS-120B | The Frontier | 0.496 | 0.769 |
Harness-1 achieves a mean selective recall of 0.730. That beats the next open subagent, Tongyi DeepResearch 30B, by 11.4 points. Among the border scanners tested, only Opus-4.6 scores higher on average.
The transmission pattern is a clear mechanical signal. SFT used four measurement families; RL used SEC only. In those family source functions, Harness-1 scored 7.9 points above the nearest open baseline. Out of the four benchmarks held, it scored 17.0. That's a massive 2.2x gain on tasks far from the training data.
Ablations support the harness claim. Disabling all harness methods reduces Recall by 12.2 percent relative to BrowseComp+. A trained policy continues to search but cannot measure what it sees.

Use Cases
The method refers to the retrieval of evidence where the documents support the answer. Several workflows fit this scenario.
Another book and copyright review. Evidence graph and selected set help organize multiple sources. Another analysis is financial savings. The SEC's case study finds the exact date of the major change in most 8-Ks.
The third is to check multi-hop facts. Fan_out_search and validation tools resolve ambiguous entities before committing. The fourth is the modular RAG. The selected set feeds the frozen generator, and better sets give higher response accuracy.
Strengths and Weaknesses
Power
- The highest recall rating among the open models tested, and behind only Opus-4.6 overall.
- Profit adheres to benchmarks that are held, suggesting common domain search functions.
- He was trained on 4,352 unique items, far less than a few basics.
- Open the inspection area and tie code, usable during normal working hours.
Weakness
- The proof graph uses a regex domain, not a complete business link.
- The validation tool is a proxy for LLM that can err on the side of ambiguous claims.
- BM25 sentence compression may reduce the context bound to the speech structure.
- The research team reports point estimates without full confidence intervals.
Key Takeaways
- Harness-1 is a 20B search agent that moves search bookkeeping to the environment, leaving semantic decisions to policy.
- It achieves a selective recall ratio of 0.730 across all eight benchmarks, beating the next open subagent by 11.4 points.
- Among the browsers tested, only Opus-4.6 scores higher for average selective recall.
- The gains are even greater for benchmarks held (+17.0 vs +7.9 points), suggesting a transfer of learned search functions.
- The weights and harness code are public, works with vLLM, SGlang, or Transformers.
Marktechpost Visual Explainer
Strong Search Agents
1 / 7
Check it out paper, Model weights again GitHub Repo. Also, feel free to follow us Twitter and don't forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? Connect with us




