Optimize video semantic search intent with Amazon Nova Model Distillation on Amazon Bedrock

Developing video semantic search models requires measurement accuracy, cost, and latency. Fast, small models lack routing intelligence, while large, intuitive models add significant latency overhead. In part 1 of this series, we showed how to build a multimodal video semantic search system on AWS with a smart goal path using the Anthropic Claude Haiku model on Amazon Bedrock. While the Haiku model delivers strong accuracy of the user's search intent, it increases the end-to-end search time to 2-4 seconds. This contributes to 75% of the overall latency.
Figure 1: An example of an end-to-end query breakdown
Now consider what happens as the routing logic grows more complex. Business metadata can be more complex than the five attributes in our example (title, caption, people, type, and timestamp). Customers may consider camera angles, mood and feel, licensing and rights windows, and additional site-specific fees. More logical understanding means more demanding information, and more demanding information leads to more expensive and slower responses. This is where customizing the model comes in. Rather than choosing between a fast but very simple model or an accurate but expensive or very slow model, we can achieve all three by training a small model to perform a task accurately with very low latency and cost.
In this post, we show you how to use Model Distillation, a model customization method in Amazon Bedrock, to transfer routing intelligence from a large teacher model (Amazon Nova Premier) back to a smaller student model (Amazon Nova Micro). This method reduces overhead by more than 95% and reduces latency by 50% while maintaining the characteristic routing quality required by the job.
Solution overview
We'll walk through the full distillation pipeline at the end to end up in a Jupyter notebook. At a high level, the notebook consists of the following steps:
- Prepare training data – 10,000 synthetic samples labeled using Nova Premier and upload the dataset to Amazon Simple Storage Service (Amazon S3) in Bedrock distillation format
- Do a distillation training exercise – Configure work with teacher and student model identifiers and submit through Amazon Bedrock
- Enter the distilled model – Promote a custom model using the on-demand index for flexible, pay-per-use access
- Measure the distilled model – Compare the quality of the route against the Nova Micro base and Claude Haiku's original base using the Amazon Bedrock Model Evaluation
The complete notebook, training data generation script, and testing resources are available in the GitHub repository.
Prepare training data
One of the main reasons we chose model fitting over other fine-tuning methods such as supervised fine-tuning (SFT) is that it does not require a fully labeled dataset. With SFT, every training example requires human-generated feedback as a ground truth. With distillation, you only need to be informed. Amazon Bedrock automatically prompts the teacher model to generate high-quality responses. It uses data fusion techniques and optimization methods behind the scenes to generate a diverse training dataset of up to 15,000 instant pairs.
That said, you can optionally provide a labeled dataset if you want more control over the training signal. Each record in the JSONL file follows the bedrock-conversation-2024 schema, where the user role (input information) is required, and the helper role (desired response) is optional. See the following examples, and the reference Prepare your training datasets for processing for more details:
In this post, we prepared 10,000 labeled simulations using Nova Premier, the largest and most capable model in the Nova family. Data was generated with equal distribution across all visual, audio, transcription, and signal metadata queries, Examples cover the full range of expected search inputs, represent different levels of difficulty, including extremes and variations, and prevent excessive corrosion to reduce query patterns. The following chart shows the weight distribution across the four mode channels.
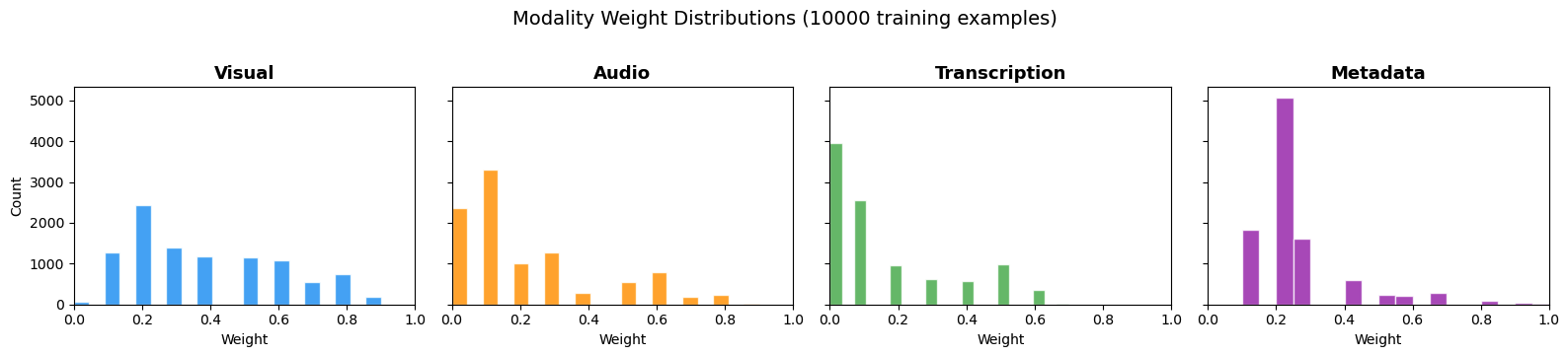
Figure 2: Weight distribution across 10,000 training examples
If you need more examples or want to adjust the distribution of the question in your content domain, it is provided generate_training_data.py script can be used to generate additional training data using Nova Premier.
Do a distillation training exercise
With the training data uploaded to Amazon S3, the next step is to run the filter function. The distillation model works by using your information to first generate responses from teacher model. It then uses those fast feedback pairs to fine-tune student model. In this project, the teacher Amazon Nova Premier and the student Amazon Nova Microa fast, cost-effective model optimized for high-output interpretation. The teacher's route decisions become a coaching signal that directs the student's behavior.
Amazon Bedrock manages all training and infrastructure orchestration automatically. No cluster configuration, no hyperparameter tuning, and no teacher-to-student pipeline setup model required. You specify a teacher model, a student model, an S3 path to your training data, and an AWS Identity and Access Management (IAM) role with the necessary permissions. Bedrock handles the rest. The following is an example of a code snippet to trigger the distillation training function:
The work is equally effective. You can monitor the progress in the Amazon Bedrock console below Base models > Custom modelsor in order:
status = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job status: {status}") # Training, Complete, or FailedThe training time varies depending on the size of the dataset and the selected learner model. For 10,000 samples labeled with Nova Micro, expect the job to be completed in a few hours.
Enter the distilled model
Once the distillation process is complete, the custom model is available in your Amazon Bedrock account and is ready to use. Amazon Bedrock offers two shipping options for custom models: Exit Provided with a predictable, high-volume load, and The Idea of Wanting for flexible, pay-as-you-go access with no upfront commitment.
For most start-up teams, defining a requirement is the recommended method. There is no supply limit, no hourly commitment, and no minimum application requirement. Following is the implementation code:
Once the status is displayed InService, yyou can invoke a fused model as you would any other base model using the standard InvokeModel or Converse API. You only pay for the tokens you consume at Nova Micro inference rates: $0.000035 for 1,000 input tokens and $0.000140 for 1,000 output tokens.
Measure the distilled model
Before comparing with the original router, it is worth confirming that the distillation has improved the ability of the base model to follow the routing function. The following table shows the same acceleration in base Nova Micro and distilled Nova Micro side by side.
| Question | Distilled Nova Micro | Nova Micro base |
"CEO discussing quarterly earnings " |
{"visual": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "The query focuses on spoken content (transcription) about earnings, but visual cues (CEO's appearance) and audio (tone/clarity) are also important..."} |
Here is a JSON representation of the information you requested for a video search query about a CEO discussing quarterly earnings:
|
"sunset over mountains" |
{"visual": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "The query focuses on a visual scene (sunset over mountains), with no audio or transcription elements. Metadata might include location or time-related tags."} |
Here is a JSON representation of the video search query “sunset over the mountains” that includes visual, audio, text, metadata weights (sum=1.0), and logic:
|
The base model struggles with both instructions and output format consistency. It produces free-text responses, incomplete JSON, and non-numeric weight values. The distilled model consistently returns well-formed JSON with four numeric weights that sum to 1.0, matching the schema required by the routing pipeline.
Comparing against the original Claude Haiku router, both models are evaluated against a held-out set of 100 labeled examples generated by Nova Premier. We use Amazon Bedrock Model Evaluation to run the comparison in a structured, managed workflow. To assess routing quality beyond standard metrics, we defined a custom OverallQuality rubric (see the following code block) that instructs Claude Sonnet to score each prediction on two dimensions: weight accuracy against ground truth and reasoning quality. Each dimension maps to a concrete 5-point threshold, so the rubric penalizes both numerical drift and generic boilerplate reasoning.
The fused Nova Micro model earned a large language model (LLM)-score from the judge 4.0 out of 5, almost identical routing quality to the Claude 4.5 Haiku at about half the latency (833ms vs. 1,741ms). The cost benefit is equally important. Switching to the Nova Micro molten model reduces the cost of projection by more than 95% for both input and output tokens, without prior commitments below the maximum demand price. Note: The LLM-as-judge assessment is non-deterministic. Scores may vary slightly from run to run.
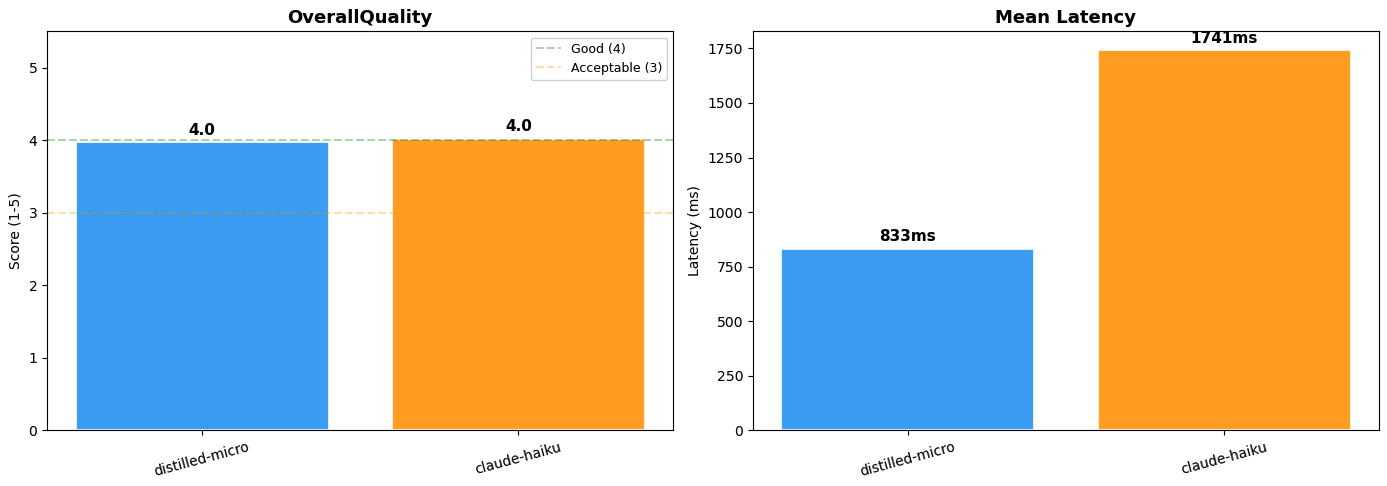
Figure 3: Comparison of model performance (Distilled Nova Micro vs. Claude 4.5 Haiku)
The following is a tabular summary of the corresponding results:
| Metric | Distilled Nova Micro | Claude 4.5 Haiku |
| LLM-as-judge score | 4.0 / 5 | 4.0 / 5 |
| It means Delay | 833 ms | 1,741ms |
| Cost of Entry Token | $0.000035 / 1K | $0.80–$1.00 / 1K |
| Cost of Issuance Token | $0.000140 / 1K | $4.00–$5.00 / 1K |
| Output Format | Fixed JSON | Inconsistent |
Clean up
To avoid ongoing costs, use the cleanup section of the notebook to remove any allocated resources, including used storage locations and any data stored in Amazon S3.
The conclusion
This post is the second part of a two-part series. Building on Part 1, this post focuses on using a filtering model to improve the intent routing layer built into a video semantic search solution. The techniques discussed help address real productivity trade-offs, such as balancing routing intelligence with latency and cost at scale while maintaining search accuracy. By integrating Amazon Nova's Premier behavior into Amazon Nova Micro using Amazon Bedrock Model Distillation, we've reduced computational cost by over 95% and cut preprocessing latency in half while maintaining the routing quality required by the job. When using multimodal video search at scale, model overlay is a cost-effective method for production-grade production without sacrificing search accuracy. To check out the full implementation, visit the GitHub repository and try the solution yourself.
About the writers

