DSGym Provides a Reusable Container-Based Platform for Building and Evaluating Data Science Agents

Data science agents must explore data sets, design workflows, execute code, and return verifiable answers, not just autocomplete Panda code. DSGym, launched by researchers from Stanford University, Together AI, Duke University, and Harvard University, is a framework that tests and trains such agents on more than 1,000 data science challenges with expertly selected truth and a consistent pipeline of training after training.
Why are existing benchmarks falling short??
The research team first investigated existing benchmarks that test data-aware agents. If the data files are encrypted, the models still maintain high accuracy. For QRData the average drop is 40.5 percent, for DAEval it is 86.8 percent, and for DiscoveryBench it is 44.4 percent. Many queries are solved using values and pattern matching in the text alone instead of analyzing the actual data, and they find annotation errors and inconsistent numerical tolerances.
Activity, agent and environment
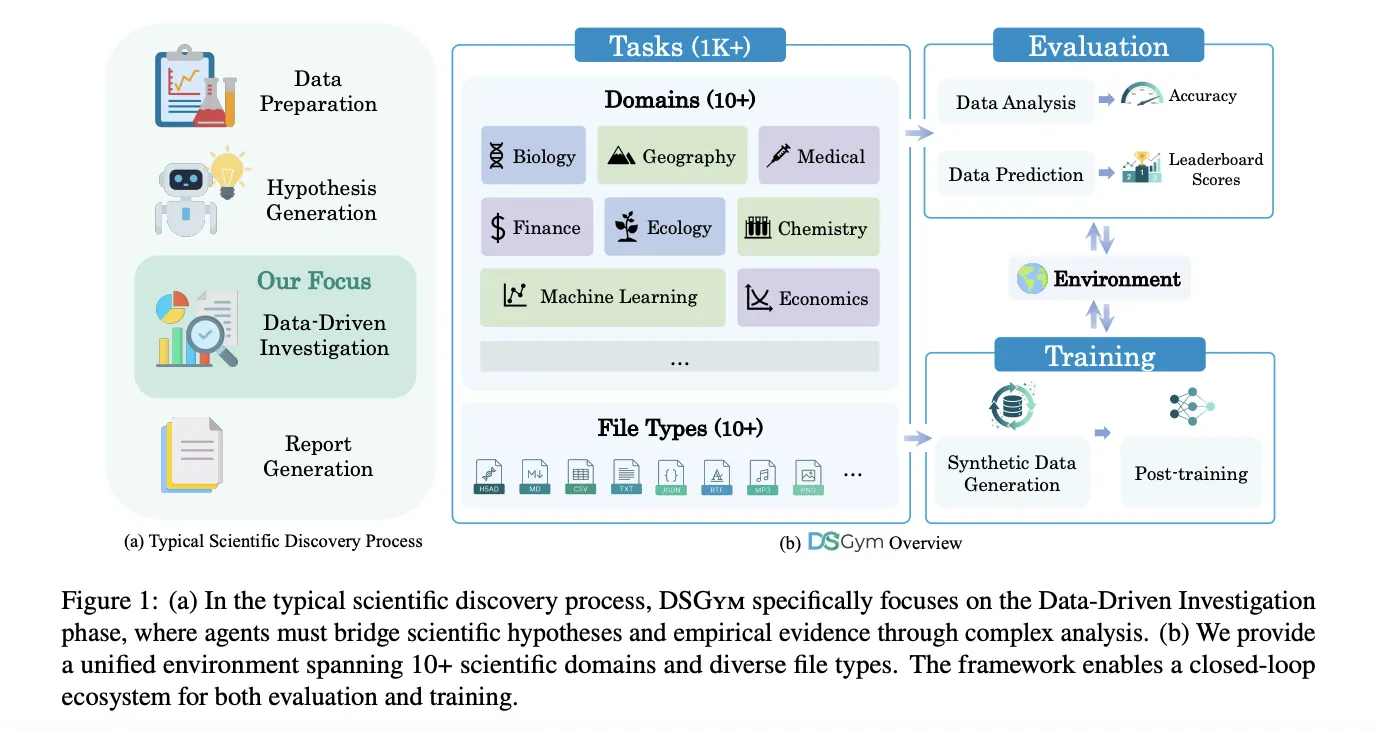
DSGym rates the test at three things, Activity, Agent, and Location. Functions are data analysis or Data Prediction. Data Analysis Functions provide one or more files and a natural language question to be answered in code. Data Prediction functions provide train and test classification and clear metrics and require an agent to build a pipeline for modeling and forecasting outputs.
Each task is packaged into a Task Object that holds the data files, query information, scoring function, and metadata. Agents interact in a CodeAct-style loop. At each instance, the agent writes a logic block that describes its program, a block of code that runs within the environment, and a response block when it is ready to commit. Environment is used as a manager and worker pool of Docker containers, where each worker mounts data as read-only volumes, exposes a writable workspace, and ships with domain-specific Python libraries.
DSGym, DSBio, and DSPredict functions
In addition to this runtime, DSGym Tasks integrates and refines existing datasets and adds new ones. The research team cleans QRData, DAEval, DABStep, MLEBench Lite, and others by discarding objectionable items and using a cut-off filter that removes questions easily solved by multiple models without accessing the data.
To cover scientific discovery, they present DSBio, a series of 90 bioinformatics works available from peer-reviewed papers and open source datasets. Activities include single-cell analysis, spatial and multi-omics, and human genetics, with numerical or categorical responses supported by reference textbooks.
DSpredict aims to model itself on real Kaggle competitions. The search engine collects the latest competitions that accept CSV submissions and satisfy size and clear rules. After pre-processing, the suite is divided into DSpredict Easy with 38 playground style and introductory competitions, and DSpredict Hard with 54 complex challenges. In total, DSGym Functions includes 972 data analysis functions and 114 prediction functions.
What current agents can and cannot do
The tests include closed source models such as GPT-5.1, GPT-5, and GPT-4o, open source models such as Qwen3-Coder-480B, Qwen3-235B-Instruct, and GPT-OSS-120B, and small models such as Qwen2.5-7B-Instruct-4B and Qwe-Instruct-4B. All using the same CodeAct agent, 0 temperature, and disabled tools.
In refined general analysis benchmarks, such as QRData Verified, DAEval Verified, and simple DABStep classification, the top models achieve between 60 percent and 90 percent matching accuracy. For DABSstep Hard, the accuracy decreases throughout the model, indicating that multi-step reasoning over financial tables is still difficult.
DSBio reveals a very serious weakness. Kimi-K2-Instruct achieves an overall accuracy of 43.33 percent. Across all models, between 85 and 96 percent of failures tested in DSBio are domain errors, including misuse of specialized libraries and incorrect biological descriptions, rather than basic coding errors.
In MLEBench Lite and DSpredict Easy, most of the borderline models reach close to the Valid Transmission Rate of more than 80 percent. On DSpredict Hard, valid submissions rarely exceed 70 percent and award rates on Kaggle leaderboards are close to 0 percent. This pattern supports the research team's observation of a simplistic bias in which agents stop after a basic solution instead of evaluating competing models with parameters.
DSGym as a data factory and training environment
The same environment can also include training data. From a subset of QRData and DABStep, the research team asks agents to explore datasets, raise questions, solve them with code, and record trajectories, generating 3,700 synthetic questions. A judge model filters this into a set of 2,000 high-quality query and trajectory pairs called DSGym-SFT, and fine-tuning the 4B Qwen3-based model in DSGym-SFT produces an agent that achieves competitive performance with GPT-4o in standard analysis benchmarks despite having very few parameters.

Key Takeaways
- DSGym provides an integrated Task, Agent, and Environment framework, with containerized functionality and a CodeAct-style loop, to test data science agents in real-code-based workflows instead of static instructions.
- The benchmark suite, DSGym-Tasks, integrates and cleans previous datasets and complements DSBio and DSPredict, reaching 972 data analysis tasks and 114 prediction tasks across domains such as finance, bioinformatics, and earth sciences.
- Analysis of shortcuts in existing benchmarks shows that removing access to data only reduces accuracy in most cases, confirming that pretests tend to estimate pattern similarity in text rather than analyzing actual data.
- Frontier models achieve strong performance in refined general analysis tasks and simple prediction tasks, but do not perform well in DSBio and DSPredict-Hard, where most errors come from domain and sequencing issues, under structured modeling pipelines.
- The DSGym-SFT dataset, built from 2,000 filtered synthetic trajectories, enables the 4B Qwen3-based agent to reach GPT-4o level accuracy in several analytical benchmarks, showing that performing supervision based on structured tasks is an effective way to develop data science agents.
Check it out Paper, again Repo. Also, feel free to follow us Twitter and don't forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.
 Method That Reduces Doom Loops in Consulting Models")

 Open Model with 21B Functional Parameters and 256K Content")
