Microsoft Research Releases Webwright: A Terminal-Native Web Agent Framework That Scores 60.1% in Odysseys, Up from Base GPT-5.4's 33.5%

Most web agents today call the browser one action at a time. The model detects the state of the current page – such as a screenshot or DOM text – and predicts the next click, key press, or scroll. This action-at-a-time design makes sense when language models have limited reasoning ability. As models become more adept at writing and debugging, that tight loop has become a hindrance instead of a helpful structure.
Microsoft Research's AI Frontiers lab has developed a different approach. Their new open source framework, Webwrightprovides the agent with a destination instead of a high-level browser session. The agent writes Playwright code to control browsers, execute bash commands, inspect logs, and iteratively refine scripts. Playwright is an open source browser automation library, also from Microsoft, that supports programmatic control for Chromium, Firefox, and WebKit browsers.
What Webwrights Do Differently
Webwright separates the agent from the browser and treats the browser as an object that the agent can start, test, and dispose of while developing the application. The persistent artifact is not browser time but code and logs in the local workspace.
This is the same model that an engineer uses when writing an RPA (Robotic Process Automation) script. Instead of clicking the site manually each time, they type the text once. That script can be renamed, modified, and shared. Webwright uses this for LLM-enabled agents.
The program has three main parts: the Runner, Model Endpoint, and Terminal Environment. The runner is about 150 lines of code, the model interface about 550 lines, and the environment about 300 lines. There is no multi-agent orchestration or complex scheduling phase — just a single-agent loop.
All intermediate code, logs, screenshots, and results are stored in the workspace, making each run easy to test.
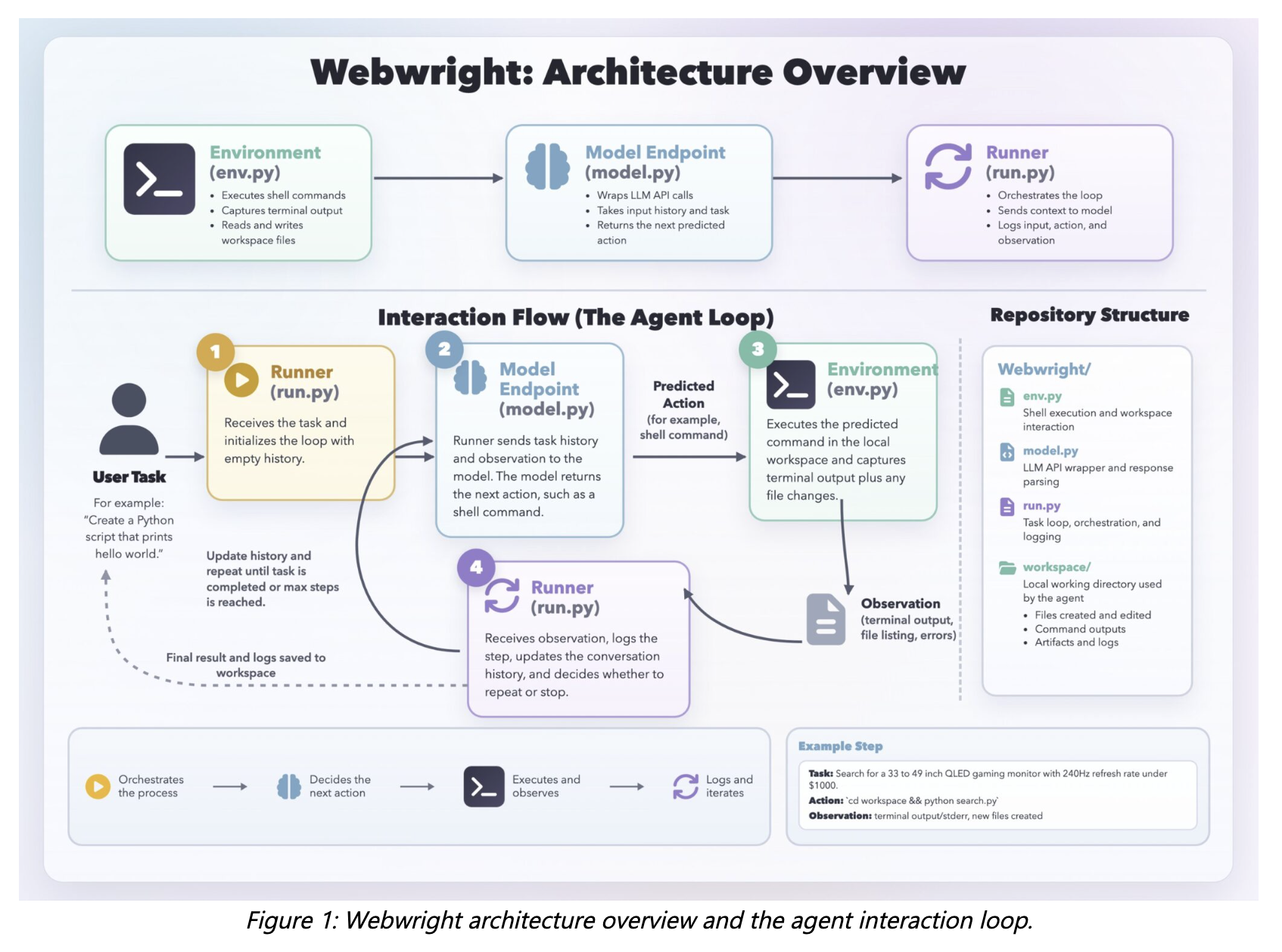
Agent Loop
The runner sends the current context to the model. The model returns a logic block and a shell command. That command runs on Environment, returning terminal output, logs, screenshots, or error traces. This view returns to the context, and the loop continues.
Rather than executing one primitive action at a time, the code agent can naturally express multi-step interactions — such as selecting a date or filling out an entire form — as a unified program. Loops, functions, and abstractions allow an agent to generalize across similar tasks without repeatedly predicting the same sequence of low-level steps.
Two Engineering Challenges
Premature 'done' and context explosion are two important problems. With open bash actions, the model should report itself and often seek success without finishing. They added a gateway: the agent must generate a self-monitoring configuration, run a final script in a new folder with logs and screenshots, and issue its own self-executing judgment of success or failure before exiting. done: true. If not, the flag drops and tries again.
With context length, long coding trajectories quickly exceed the context limit, so they combine the history every 20 steps into one summary.
Benchmark results
Webwright has been tested in two benchmarks: Online-Mind2Web and Odysseys.
Online-Mind2Web contains 300 activities across 136 widely used sites and uses the automated LLM-as-a-Judge assessment framework. GPT-5.4 achieves an overall accuracy of 86.67%, which represents the highest among all open-source cooking harnesses in the AutoEval category of the Online-Mind2Web benchmark, with a budget of 100 steps. Claude Opus 4.7 reached 84.7% overall but did better on the hard tasks at N=100 steps — 80.5% compared to 76.6% for GPT-5.4.
They also reproduced the baseline of GPT-5.4 in a typical screenshot-based agent setting, where the model predicts the x,y coordinates of clicks and typing actions. Using the same basic model, Webwright achieves significant gains across all three difficulty levels, highlighting the advantage of a code-driven conclusion-based approach over step-by-step integration predictions.
Odysseys examines long-term browsing activities spanning multiple websites. Jobs average 272.3 words of instruction. In the April 2026 leaderboard, the best performing model was the Opus 4.6, with a maximum score of 44.5. Webwright powered by GPT-5.4 reaches 60.1%, a relative improvement of 35.1% over the previous state of the art. Compared to GPT-5.4's baseline performance of 33.5%, this equates to a relative improvement of 79.4% — or a total of 26.6 points.
Cost Analysis
Claude Opus 4.7 performs better in the number of steps to solve each task (mean 21.9 steps) compared to GPT-5.4 (mean 26.3 steps). However, Claude Opus 4.7 has a higher price compared to GPT-5.4 ($5 vs. $2.50 for 1M input tokens, and $25 vs. $15.00 for 1M output tokens, in April 2026), making the average cost per transaction higher compared to GPT-5.4 ($2.309 vs. Initial steps 50 steps yield 82% accuracy, and the next 50 steps yield 3–4 more points.
Small Model Performance
The research team also tested Qwen3.5-9B on the hard classification of Online-Mind2Web. When the tasks are added with the scripts of the reconstructed tools, Qwen3.5-9B achieves 66.2% of the Online-Mind2Web websites with more than five tools. This shows that small, low-cost models can handle complex web tasks when paired with a library of pre-built tools.
Marktechpost Visual Explainer
Webwright
Quick Start Guide
What is a Webwright?
Webwright is an open source, native web agent framework from the Microsoft Research. Instead of predicting one browser at a time, the agent writes Playwright code, runs bash commands, and stores reusable scripts in the local workspace.
- ~1,000 lines of the harness code across all 3 modules – no hidden orchestration
- Single agent loop: Runner, Model endpoint, and Terminal Environment
- 86.7% on Online-Mind2Web | 60.1% on Odysseys with GPT-5.4
- Returns: OpenAI, Anthropic, OpenRouter
- Documents that can be reused internally Claude Code, Codex, OpenClaw
# GitHub repository
github.com/microsoft/Webwright
What you need Before installing
Make sure the following is correct before running any installation commands.
- Python 3.10+ – minimum working time required
- Chromium — included with Playwright in the next step
- API key – OpenAI, Anthropic, or OpenRouter
- Git — to combine the cache
# Check your Python version python --version # Must return Python 3.10 or higher
Clone and Install Webwright
Compile the repo, put it in editable mode, and install Chromium's Playwright browser control.
# 1. Clone the repository git clone cd Webwright # 2. Install the package in editable mode pip install -e . # 3. Install Chromium for Playwright playwright install chromium
I – e flagging means local source editing works immediately without reinstalling.
Do Your First Web Job
Extract your API key, then pass the task command and start URL to the CLI.
# Export your key export OPENAI_API_KEY="sk-..." export ANTHROPIC_API_KEY="sk-ant-..." # Run a task python -m webwright.run.cli -c base.yaml -c model_openai.yaml -t "Find cheapest economy flight SEA to JFK on 2026-05-15" --start-url --task-id demo_openai -o outputs/default
| Raise a flag | Explanation |
|---|---|
| -c | Edit the file from src/webwright/config/ — it's set |
| -t | Career guidance in plain English |
| – initial url | The initial URL of the browser session |
| -work identity | The name of the output subfolder |
| – o | The origin of the output of logs and scripts |
Use Webwright as a Claude code skill
Webwright ships with built-in Claude Code capability. No separate LLM API key is required beyond your Claude Code subscription. Claude Code reads PNG screenshots natively.
# Project-scoped (inside this repo only) mkdir -p .claude/skills .claude/commands ln -s "$PWD/skills/webwright" .claude/skills/webwright ln -s "$PWD/skills/webwright/commands" .claude/commands/webwright # User-scoped (all projects) mkdir -p ~/.claude/skills ~/.claude/commands ln -s "$PWD/skills/webwright" ~/.claude/skills/webwright ln -s "$PWD/skills/webwright/commands" ~/.claude/commands/webwright
Restart Claude Code after installation, and run the slash commands:
# One-shot task /webwright:run search Google Flights SEA to JFK 2026-05-15 # Reusable parameterized CLI tool /webwright:craft search a ticket from LAX to SFO depart June 7
Source: github.com/microsoft/Webwright
Key Takeaways
- Webwright uses a terminal loop where the agent writes and executes Playwright code instead of predicting one browser action at a time.
- GPT-5.4 achieved 86.7% on Online-Mind2Web (100-step budget) and 60.1% on Odysseys — 26.6 points above GPT-5.4's base score of 33.5%.
- The harness is ~1,000 lines across three modules with no multi-agent orchestration.
- Qwen3.5-9B achieved 66.2% in hard classification of Online-Mind2Web when supplemented with pre-built tool scripts.
- Work scripts are packaged as executable CLIs, which can be shared across Code Claude, Codex, and OpenClaw.



