Qwen Researchers Release Qwen3-TTS: A Multilingual TTS Suite With Real-Time Latency and Smart Voice Control

Alibaba Cloud's Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three main functions in a single stack, voice clone, voice design, and high-quality speech production.
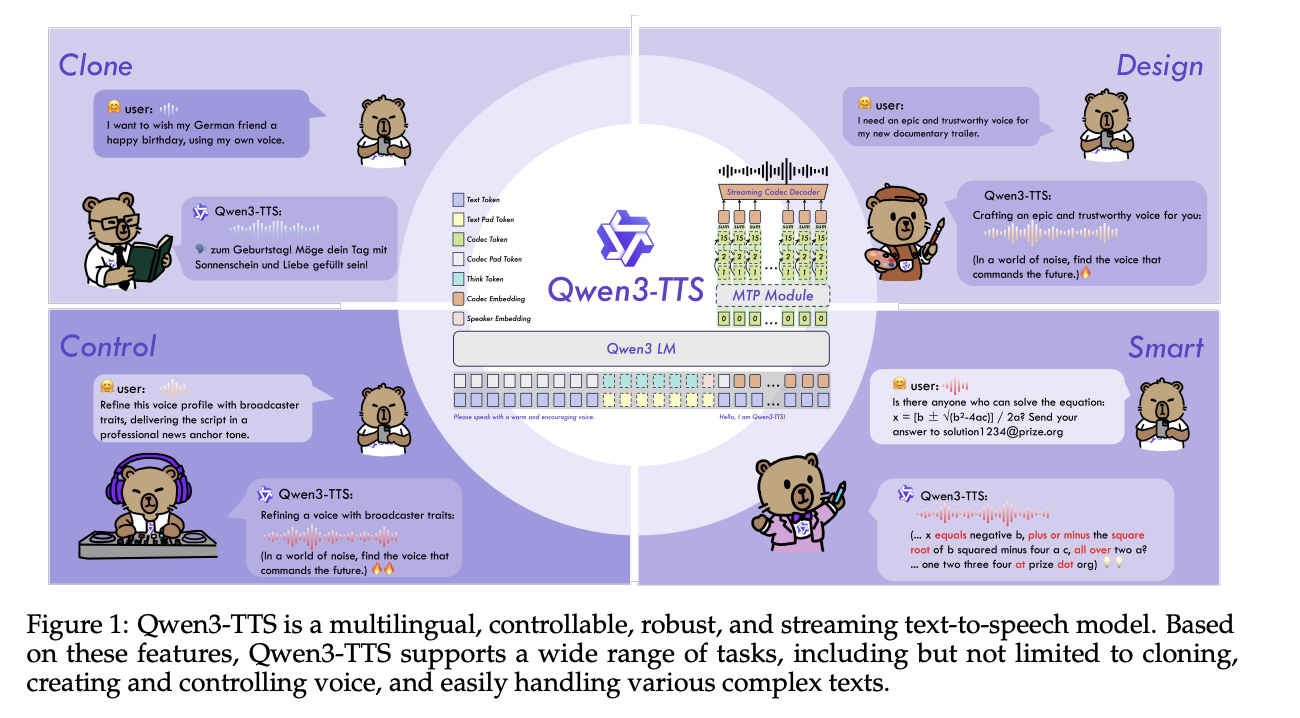
Family model and skills
Qwen3-TTS uses a 12Hz speech token and 2 language model sizes, 0.6B and 1.7B, which are combined into 3 main functions. The open release reveals 5 models, Qwen3-TTS-12Hz-0.6B-Base and Qwen3-TTS-12Hz-1.7B-Base for voice cloning and standard TTS, Qwen3-TTS-12Hz-0.6B-CustomVoice and Qwen3-TTS-. Qwen3-TTS-12Hz-1.7B-VoiceDesign for free form voice generation from natural language descriptions, and Qwen3-TTS-Tokenizer-12Hz codec.
All models support 10 languages, Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish and Italian. The CustomVoice variety is shipped with 9 selected instruments, such as Vivian, a bright young Chinese female voice, Ryan, a dynamic English male voice, and Ono_Anna, a playful Japanese voice, each with a brief description including timbre and speaking style.
The VoiceDesign model maps text commands directly to new words, for example 'speak in a nervous teenage boy's voice with a rising pitch' and can be combined with the Base model by first generating a short reference clip and reusing it create_voice_clone_prompt.
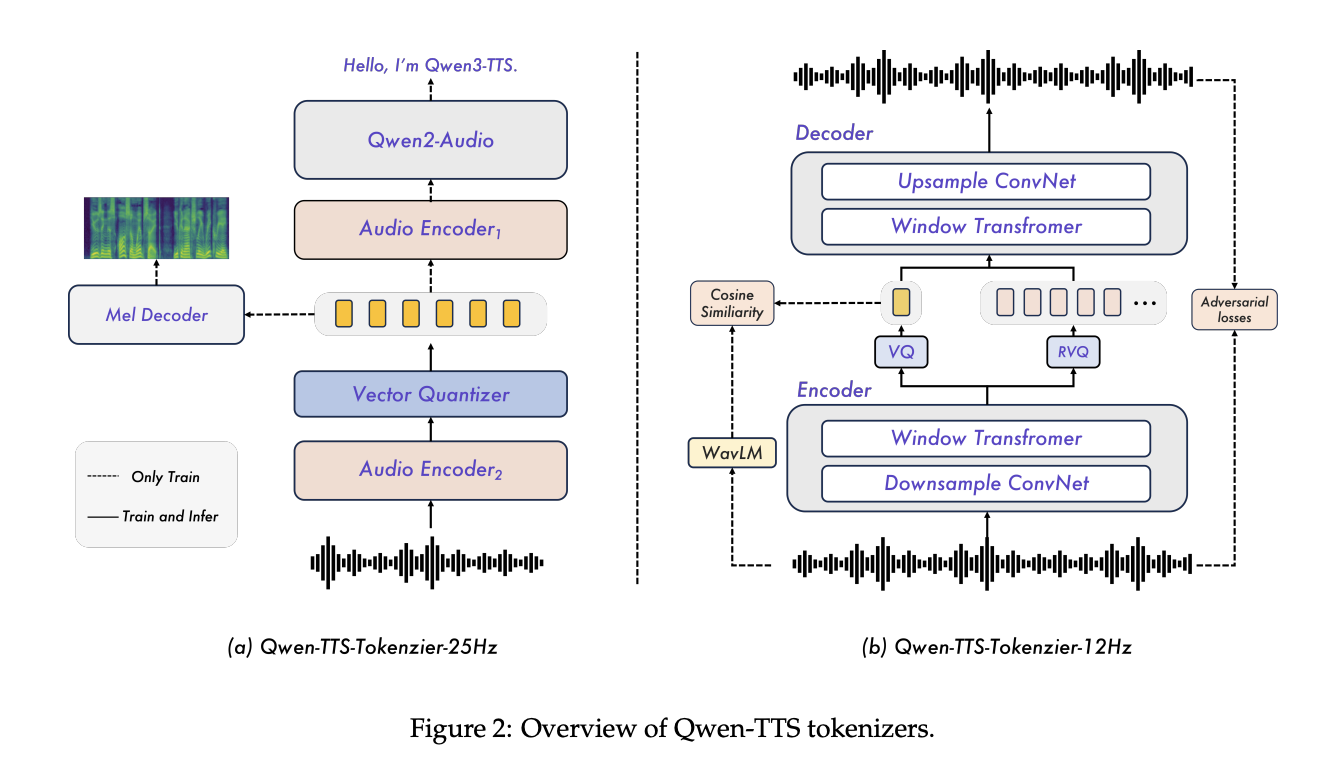
Architecture, tokenizer, and streaming method
Qwen3-TTS is a two-track language model, one track predicts different acoustic tokens in the text, the other handles alignment and control signals. The system is trained on more than 5 million hours of multilingual speech in 3 pre-training stages ranging from standard mapping, to high-quality data, to long context support for up to 32,768 tokens.
The key component is the Qwen3-TTS-Tokenizer-12Hz codec. It runs at 12.5 frames per second, about 80 ms per token, and uses 16 quantizers with a 2048 input codebook. In tests LibriSpeech is clean up to PESQ wideband 3.21, STOI 0.96, and UTMOS 4.16, SpeechTokenizer, XCodec, Mimi, FireredTTS 2 and other recent semantic tokens, while using the same or lower frame rate.
The tokenizer is used as a pure left-stream decoder, so it can output waveforms as soon as enough tokens are available. With 4 tokens per packet, each broadcast packet carries 320 ms of audio. The non-DiT decoder and the free design of BigVGAN lowers recording costs and makes stacking easier.
On the language model side, the research team reports end-to-end streaming scaling in a single vLLM backend with torch.compile and CUDA Graph optimization. For Qwen3-TTS-12Hz-0.6B-Base and Qwen3-TTS-12Hz-1.7B-Base at concurrency 1, the first packet delay is about 97 ms and 101 ms, with real-time factors of 0.288 and 0.313 respectively. Even at concurrency 6, the latency of the first packet remains around 299 ms and 333 ms.
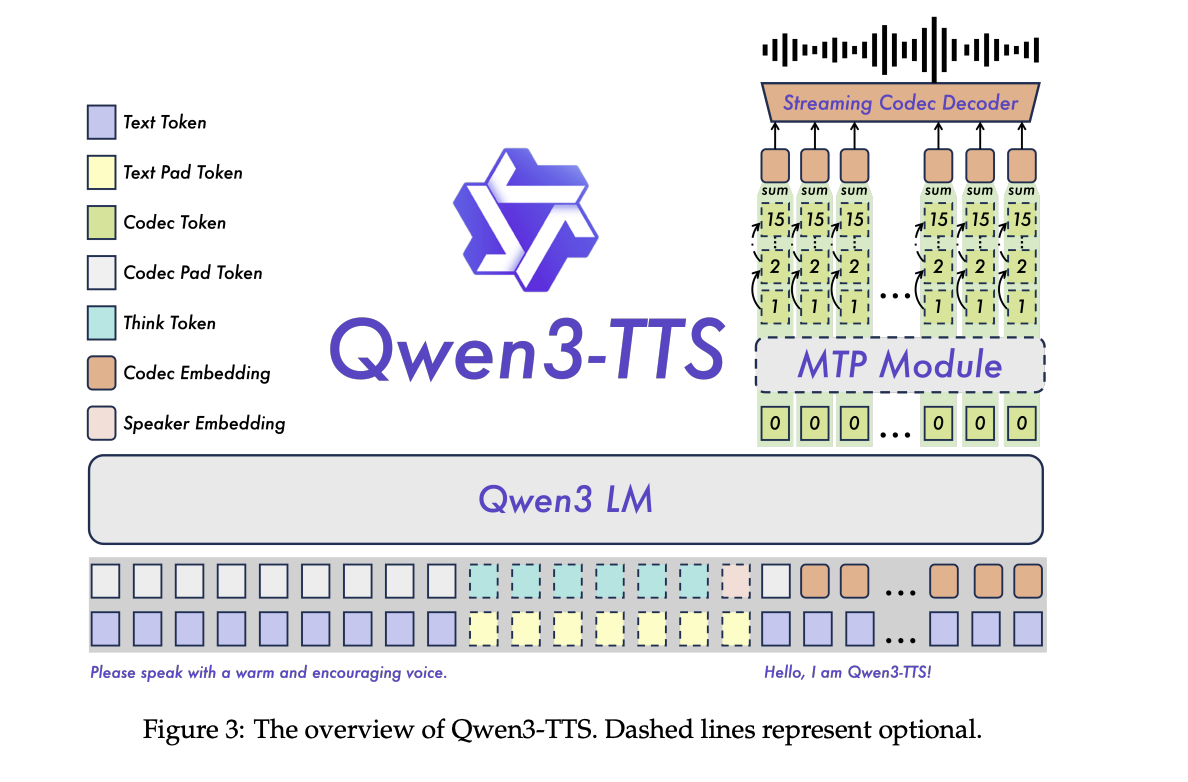
Alignment and control
Post training uses a staged alignment pipeline. First, Direct Preference Optimization matches generated speech to human preferences in multilingual data. Then GSPO with rule-based rewards improves stability and prosody. The final stage of fine-tuning the speaker in the Base model brings out the uniqueness of the target speaker while maintaining the basic capabilities of the standard model.
The following command is used in the ChatML style format, where text instructions about style, mood or tempo are evaluated first in the input. This same interface enables VoiceDesign, CustomVoice style prompts, and fine-tuning of generated speakers.
Benchmarks, zero shot cloning, and multilingual speech
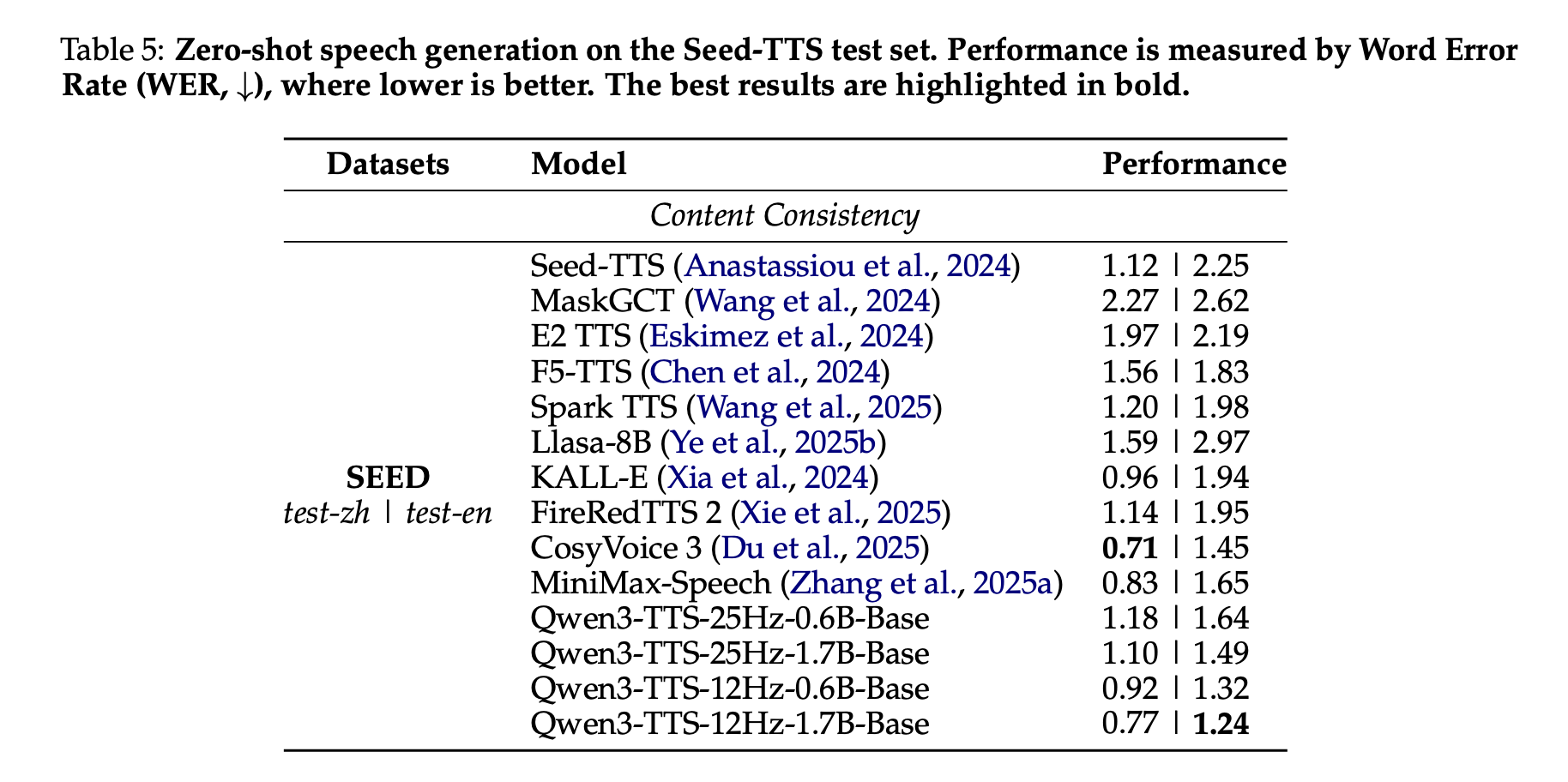
In the Seed-TTS test set, Qwen3-TTS is tested as a speech synthesis system. The Qwen3-TTS-12Hz-1.7B-Base model achieves a Word Error Rate of 0.77 in test-zh and 1.24 in test-en. The research team highlights the 1.24 WER in test-en as state of the art among comparable systems, while the Chinese WER is close, but not lower, than the best result of CozyVoice 3.
In the multilingual TTS test set that includes 10 languages, Qwen3-TTS achieves the lowest WER in 6 languages, Chinese, English, Italian, French, Korean, and Russian, and competitive performance in the remaining 4 languages, while achieving greater speaker similarity in all 10 languages compared to MiniMax-Speech and ElevenLabs Multilingual v2.
Cross-language tests show that Qwen3-TTS-12Hz-1.7B-Base reduces the mixed error rate for several language pairs, such as zh-to-ko, where the error rate drops from 14.4 in CozyVoice3 to 4.82, about a 66 percent relative reduction.
In InstructTTSEval, the Qwen3TTS-12Hz-1.7B-VD VoiceDesign model sets new state-of-the-art scores among open source models in Interpretation-Speech Consistency and Response Accuracy in both Chinese and English, and competes with commercial systems such as Hume and Gemini in several metrics.
Key Takeaways
- A full open source TTS stack: Qwen3-TTS is an Apache 2.0 licensed suite that combines 3 functions in one stack, high-quality TTS, 3-second voice cloning, and command-based voice design for all 10 languages using the 12Hz token family.
- High-performance private codec and real-time streaming: Qwen3-TTS-Tokenizer-12Hz uses 16 codebooks at 12.5 frames per second, achieves strong PESQ, STOI and UTMOS scores, and supports packetized streams with up to 320 ms noise per packet and sub 120 ms initial packet delay of 0.6B in 1 reported models.
- Various functions for certain models: The release offers Base models for cloning and standard TTS, CustomVoice models with 9 predefined speakers and style information, and a VoiceDesign model that generates new voices directly from natural language descriptions that can be reused by the Base model.
- Strong alignment and multilingual quality: A multi-stage alignment pipeline with DPO, GSPO and good speaker configuration gives Qwen3-TTS low word error rates and high speaker similarity, with the lowest WER in 6 out of 10 languages and the best speaker similarity in all 10 languages among the systems tested, and the state of the art means English cloning in Seed TTS.
Check it out Model weights, Repo again The playground. Also, feel free to follow us Twitter and don't forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


