Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): An Audiovisual Encoder Enables SAM Audio and Large-Scale Multimodal Retrieval
: An Audiovisual Encoder Enables SAM Audio and Large-Scale Multimodal Retrieval")
Meta researchers have introduced the Perception Encoder Audiovisual, PEAVas a new family of encoders for the joint understanding of audio and video. The model learns a coherent representation of audio, video, and text in a single embedding using large-scale disparity training on 100M audio-video pairs with text captions.
From Perception Encoder to PEAV
The Perception Encoder, PE, is the core perception stack in Meta's Perception Models project. It is a family of image, video, and audio encoders that achieve state-of-the-art performance on multiple visual and audio benchmarks using an integrated pre-training recipe. The PE core outperforms SigLIP2 for image tasks and InternVideo2 for video tasks. PE lang powers Perception Language Model for multimodal thinking. The PE area is open for dense projection tasks such as detection and depth measurement.
PEAV builds on this core and extends it to full audio video text alignment. In the Perception Models database, PE audio visualization is listed as a branch that embeds audio, video, audio-video, and text into a single shared embedding to understand the various methods.
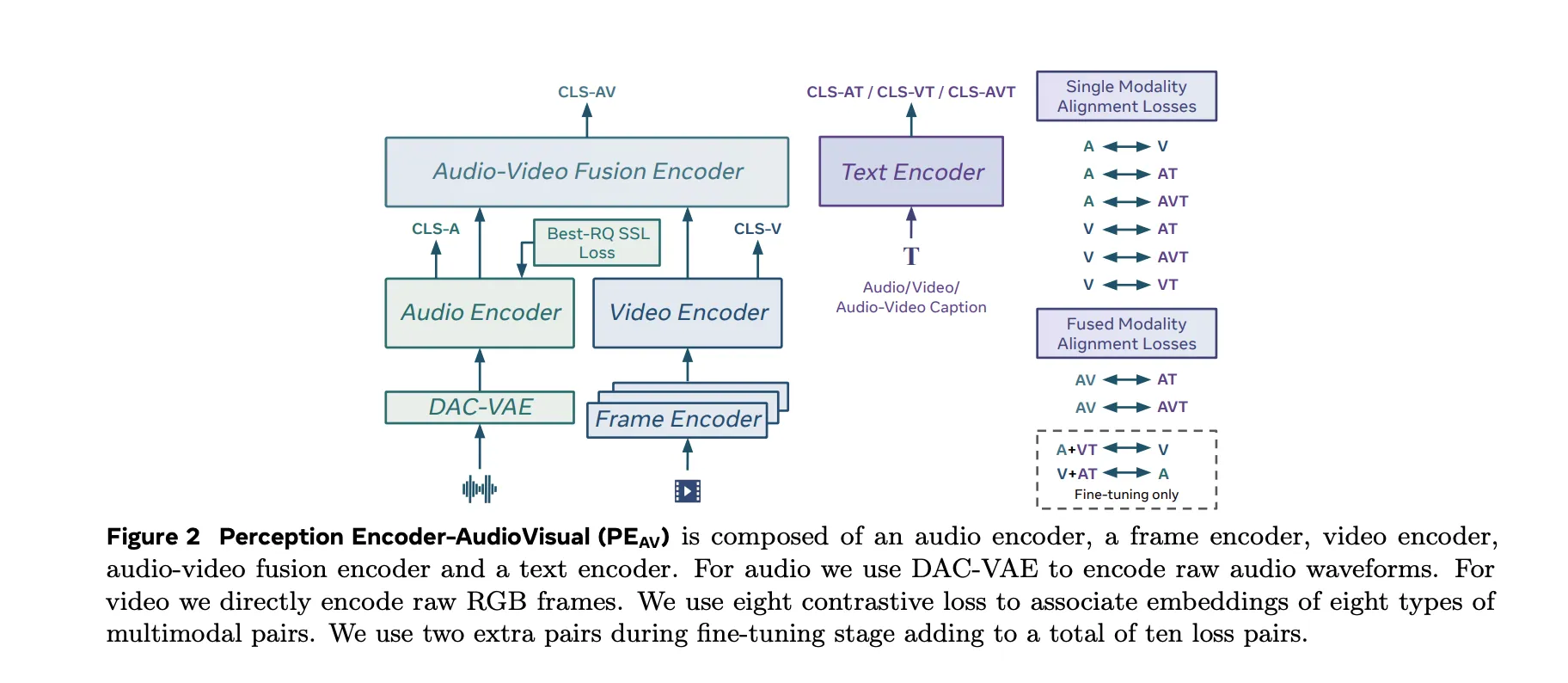
Architecture, Separate Towers and Fusion
PEAV the architecture is composed of a frame encoder, a video encoder, an audio encoder, an audio video composite encoder, and a text encoder.
- The video router uses the existing PE frame encoder for RGB frames, and then uses a temporal video encoder on top of the frame level features.
- The audio path uses a DAC VAE as a codec to convert the raw waveforms into discrete audio tokens at a constant frame rate, approximately one embed every 40 milliseconds.
These towers feed an integrated video encoder that reads the shared representation of both streams. A text encoder projects text queries in certain specialized areas. Doing this gives you a single backbone that can be questioned in many ways. You can get video to text, audio from text, audio from video, or retrieve text descriptions placed in any combination of ways without retraining specific job heads.
Data Engine, Captions for Audio-Visual Processing at Scale
The research team proposed a two-stage audio-visual data engine that produces high-quality artificial captions for unlabeled clips. The team describes a pipeline that first uses several models of weak audio captions, their confidence scores, and different video captions as input to a larger language model. This LLM generates three types of captions for each clip, one for audio content, one for visual content, and one for combined audio visual content. The first PE AV model is trained on this passive monitoring.
In the second phase, this is the first PEAV paired with a Perception Language Model decoder. Together they refined captions to better exploit audio-visual books. The two-stage engine generates reliable captions for about 100M audio-video pairs and uses up to 92M unique clips for stage 1 pre-training and an additional 32M unique clips for stage 2 fine-tuning.
Compared to previous work that often focuses on speech or small sound domains, this corpus is designed to measure across speech, general sounds, music, and various video domains, which is important for normal sound retrieval and understanding.
Opposite Objective in Ten Way Pairs
PEAV applies a different sigmoid-based loss to all audio, video, text, and composite representations. The research team explains that the model uses eight different loss pairs during training. These cover combinations such as audio text, video text, audio video text, and related pairings. During fine tuning, two more pairs were added, bringing the total to ten pairs of losses between different types of mode and subtitles.
This objective is similar in form to the conflicting objectives used in recent vision language processors but is designed for three-dimensional training of audio-video text. By aligning all these views in one place, the same encoder can support sorting, retrieval, and book operations with simple dot product matching.
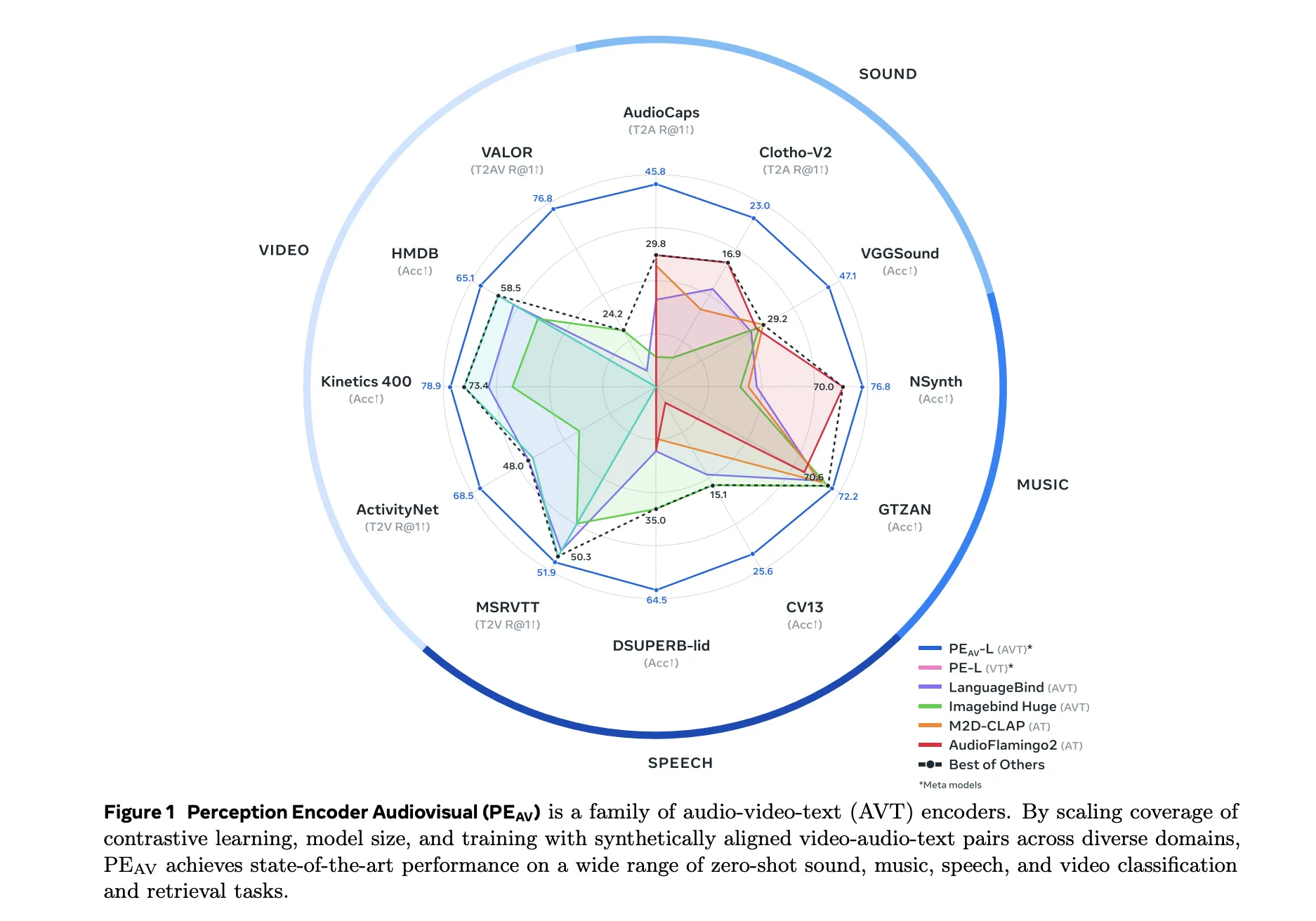
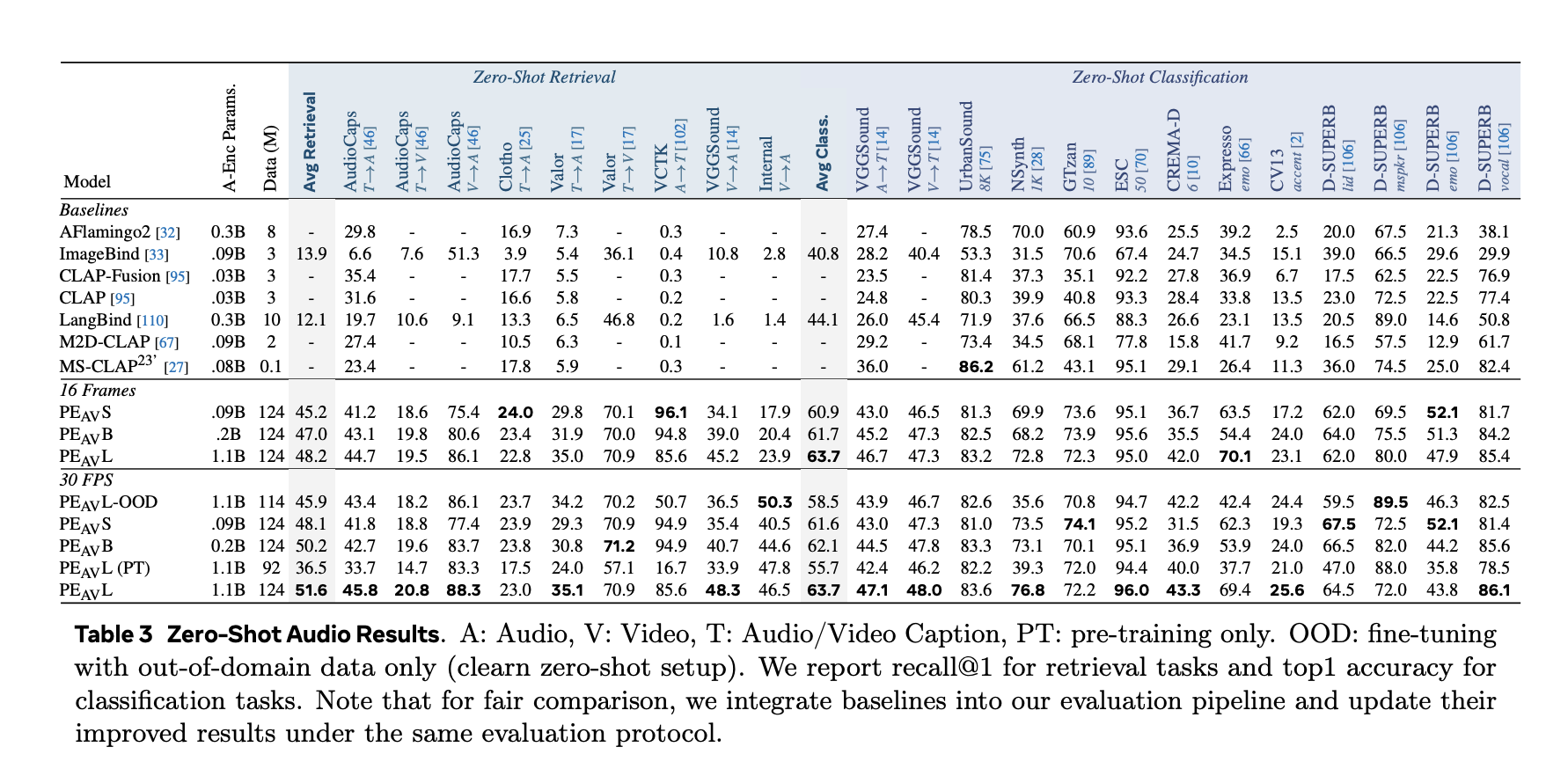
Performance in All Audio, Speech, Music and Video
In benchmarks, PEAV directs zero shot retrieval and multiple domain separation. PE AV achieves state-of-the-art performance in several audio and video metrics compared to the latest audio text and audio video text models from services such as CLAP, Audio Flamingo, ImageBind, and LanguageBind.
Advantages of concrete include:
- For AudioCaps, text-to-audio conversion improves from 35.4 R in 1 to 45.8 R in 1.
- In VGGSound, the clip classification accuracy improves from 36.0 to 47.1.
- For speech detection in VCTK-style tasks, PE AV achieves an accuracy of 85.6 while previous models are close to 0.
- In ActivityNet, text-to-video retrieval improves from 60.4 R in 1 to 66.5 R in 1.
- In Kinetics 400, the zero video separation improves from 76.9 to 78.9, beating the models 2 to 4 times larger.
PEThe FrameFrame Level Audio Text Editing
About PEAVMeta releases Perception Encoder Audio Frame, PEThe Framefor sound localization. PE A Frame is an audio embedding model that outputs one audio embed per 40 millisecond frame and one text embed per query. The model can return time intervals that mark where in the noise each defined event is.
PEThe Frame uses frame-level asynchronous reading to match audio frames to text. This enables precise localization of events such as specific speakers, instruments, or sounds passing through a long audio sequence.
Contribution to Visual Models and the SAM Audio Ecosystem
PEAV and PEThe Frame stay within the comprehensive Perception Models stack, which includes PE encoders and the Perception Language Model for multimodal processing and reasoning.
PEAV and is the main insight engine behind SAM Audio's new Meta model and its Judge tester. SAM Audio uses PEAV embedding to connect visual and textual information to audio sources in complex mixes and to obtain the quality of separated audio tracks.
Key Takeaways
- PEAV is an integrated audio, video, and text embedder, trained by inverse learning on more than 100M videos, and embeds audio, video, audio video, and text into a single shared platform for multimodal retrieval and understanding.
- The architecture uses separate video and audio towers, with PE-based encoding and DAC VAE audio token, followed by an integrated audio encoder and special text heads aligned with different channel pairs.
- A stage 2 data engine generates visual, audio, and audio captions using weak captioning and stage 1 LLM and PEAV and the Perception Language Model in phase 2, which allows multimodal monitoring without portable labels.
- PEAV establishes a new state of the art in various audio and video benchmarks by using a different sigmoid objective over multi-path pairs, with six public test areas from a small frame of 16 to a large frame variety, where the average recovery improves from about 45 to 51.6.
- PEAVand PE framework levelThe Frame separately, it forms the optical core of SAM's Meta audio system, providing embedding used for fast-based audio classification and blue-tone localization of all speech, music, and general sounds.
Check it out Paper, Repo and Model Weights. Also, feel free to follow us Twitter and don't forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among the audience.



