OpenMOSS Releases MOSS-Audio: An Open Source Base Model for Speech, Sound, Music, and Time-Aware Audio Communication

Understanding what's going on in an audio clip is a tricky problem. Writing spoken words is the easy part. A really capable system also needs to recognize who is speaking, recognize their emotional state, interpret background sounds, analyze musical content, and answer time-based questions like 'what is the speaker saying at the 2 minute mark?'. Dealing with all that required the stitching together of many specialized systems.
Tthe OpenMOSS team, MOSI.AI, and Shanghai Innovation Institute released MOSS-Sound: an open source audio perceptual model designed to integrate all those capabilities within a single base model.
What MOSS-Audio actually does
MOSS-Audio supports speech understanding, spatial sound understanding, music understanding, audio snippets, QA for timing, and complex reasoning with real world sound. Its skill set is divided into several different areas. Speech and Content Comprehension accurately recognizes and transcribes spoken content, supporting both word-level and sentence-level timestamp alignment. Speaker, Sentiment Analysis and Event it identifies speaker characteristics, analyzes emotional states based on tone, timbre, and context, and detects important acoustic events within audio. Scene & Audio Extraction it extracts auditory signals from background sounds, natural sounds, and non-speech signals to understand spatial and spatial context. Understanding Music analyzes musical style, emotional progression, and instrumentation. Audio Quiz & Summary handles questions and summaries throughout lectures, podcasts, meetings, and interviews. Finally, Complex Reasoning perform multi-hop reasoning with audio content, supported by both chain training and reinforcement learning.
Practically speaking, one MOSS-Audio model can do all of the above without having to switch between different specialized systems.
Four types of models
The team released four models at launch: MOSS-Audio-4B-Order, MOSS-Audio-4B-Thinking, MOSS-Audio-8B-Orderagain MOSS-Audio-8B-Thinking. The naming convention must be understood when deciding what to use. I Order exceptions are made for direct subsequent instruction, making them well-suited for production pipelines when you want predictable, orderly output. I Thinking variants provide strong chain-of-thinking capabilities, better suited for tasks that require multi-hop reasoning. 4B models are used Q3-4B as the core of the LLM, and 8B models are used Qwen3-8Bresulting in model sizes of approximately 4.6B and 8.6B parameters respectively.
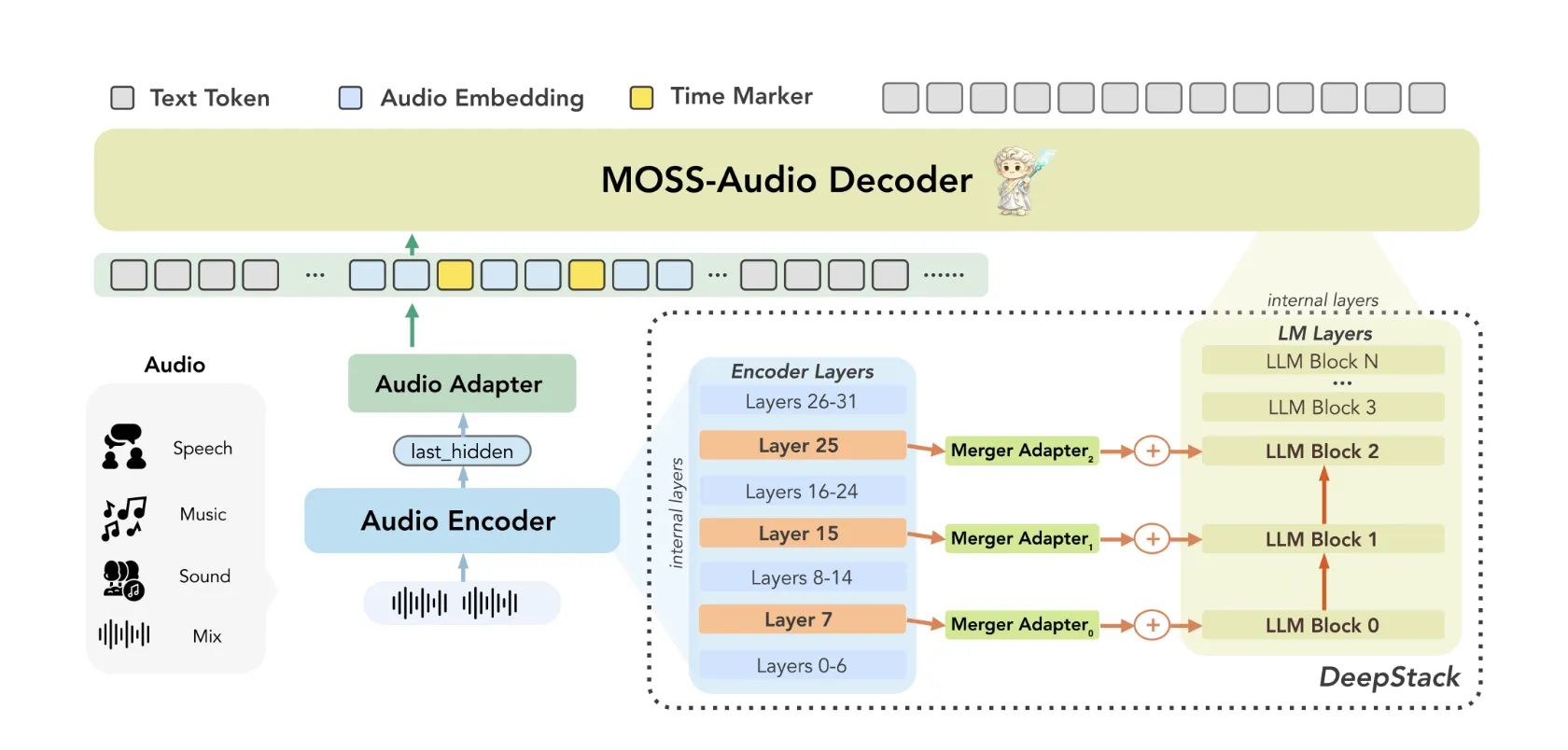
Architecture: Three Components Working Together
MOSS-Audio follows a a module design that includes three components: an audio encoder, a mode adapter, and a main language model.. Raw audio is written first by MOSS-Audio-Encoder be temporary presentations ongoing at 12.5 Hz. Those representations are then exposed to the embedding space of the language model via an adapter, and finally used by the LLM to perform automatic reverse transcription.
The research team trained the encoder from scratch rather than relying on off-the-shelf audio frontends. Their thinking: a dedicated encoder delivers more robust speech representations, tighter temporal alignment, and better amplification across acoustic domains.
Two architectures within MOSS-Audio are worth understanding in detail.
DeepStack Cross-Layer Feature Injection: A common weakness in audio models is that relying only on high-layer features of the encoder tends to lose low-level acoustic information, things like prosody, temporal events, and local time-frequency structure. MOSS-Audio talks about this with DeepStack-an inspired cross-layer injection module between the encoder and the language model: in addition to the output of the last layer of the encoder, features from the previous and intermediate layers are selected, expressed independently, and injected into the first layers of the language model. This preserves multi-granular information from low-level acoustic details to high-level semantic abstractions, helping the model preserve rhythm, timbre, tempo, and background structure that a single high-level representation cannot fully capture.
Time-Aware Representation: Time is an important factor in audio that text models are not naturally equipped to handle. MOSS-Audio talks about this with a to enter a time stamp strategy during pre-training: time tokens are inserted graphically between representations of audio frames at fixed intervals to indicate temporal locations. This allows the model to learn 'what's going on there' within an integrated framework for text generation, timestamping that natively supports ASR, event localization, time-based QA, and long audio replay – without requiring a separate localization head or post-processing pipeline.
Benchmark Performance
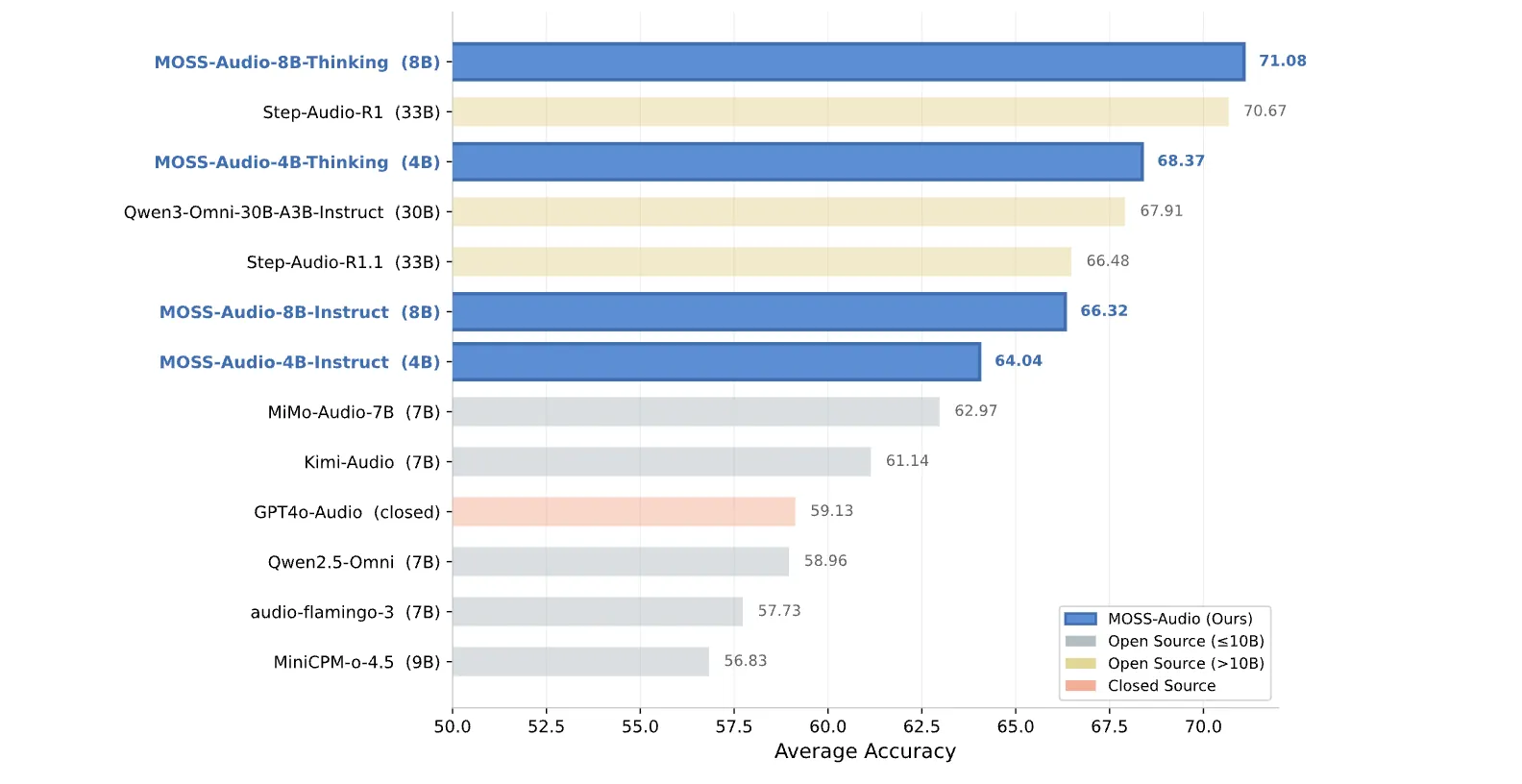
Numbers are powerful. In general audio understanding, MOSS-Audio-8B-Thinking achieves an average accuracy of 71.08 in all four dimensions – 77.33 in MMAU, 64.92 in MMAU-Pro, 66.53 in MMARagain 75.52 in MMSUwhich works better than most open source models. That includes the main models: Step-Sound-R1 at 33B scores 70.67, and Qwen3-Omni-30B-A3B-Instruct at 30B scores 67.91. Further, Kimi-Audio (7B) gets 61.14 and MiMo-Audio-7B gets 62.97 on the same scale. The difference of 4B Thinking is 68.37 points, which means that the small model with a series of thought training beats all the major competitors of open source teaching only.
Opened a summary of the speechevaluated by the LLM-as-a-Judge's 13-dimensional approach including gender, age, diction, pitch, volume, speed, texture, clarity, fluency, emotion, tone, personality, and brevity, the MOSS-Audio-Instruct variety leads in all 11 of the 13 MOSSBe-Level ratings the highest average score 3.7252.
Opened automatic speech recognition (ASR) consisting of 12 test measures – including health condition, code switching, dialect, singing, and non-verbal conditions – MOSS-Audio-8B-Instruct achieves Very low CER (Character Error Rate) of 11.30 for all models tested.
Key Takeaways
- One Model, Full Sound Stack: MOSS-Audio combines speech transcription, speaker and emotion analysis, spatial audio understanding, music analysis, audio annotation, time-sensitive QA, and complex reasoning into an open source model, eliminating the need to integrate multiple specialized systems together.
- Two Architectural Innovations Drive Performance: DeepStack Cross-Layer Feature Injection preserves multi-granularity acoustic information by injecting features from intermediate encoder layers directly into early LLM layers, while time-stamping during pre-training gives the model a clear temporal awareness of time-stamp-based activities.
- Best-in-Class Performance Benchmark Results: MOSS-Audio-8B-Thinking achieves an average accuracy of 71.08 in general audio comprehension benchmarks, outperforming all open source models including 30B+ systems, while the 4B Thinking variant alone beats every major open source competitor for teaching only.
- Outstanding ASR Timestamp Accuracy: MOSS-Audio-8B-Instruct scores 35.77 AAS on AISHELL-1 and 131.61 AAS on LibriSpeech, significantly outperforming both Qwen3-Omni-30B-A3B-Instruct (833.66) and closed-source Gemini-2mark (40) the same Gemini-71 mark.
Check it out Model weights again Repo. Also, feel free to follow us Twitter and don't forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



: A Three-Class Model Family with a Tool for Calling the Response API")