Jina Ai releases Jina-VLM: A virtual token-oriented multi-language model for QA

Jina AI has released jina-VLM, a 2.4B visual language model for multi-language visual response and scripting on compressed hardware. The model couples the Siglip2 Vision Encoder with the Qwen3 backend language and uses a visual attention connector to reduce vision tokens while preserving spatial structure. Among open 2B VLMS, it achieves state of the art effects in many benchmarks such as MMMB and MMBERILY MMBEZ.
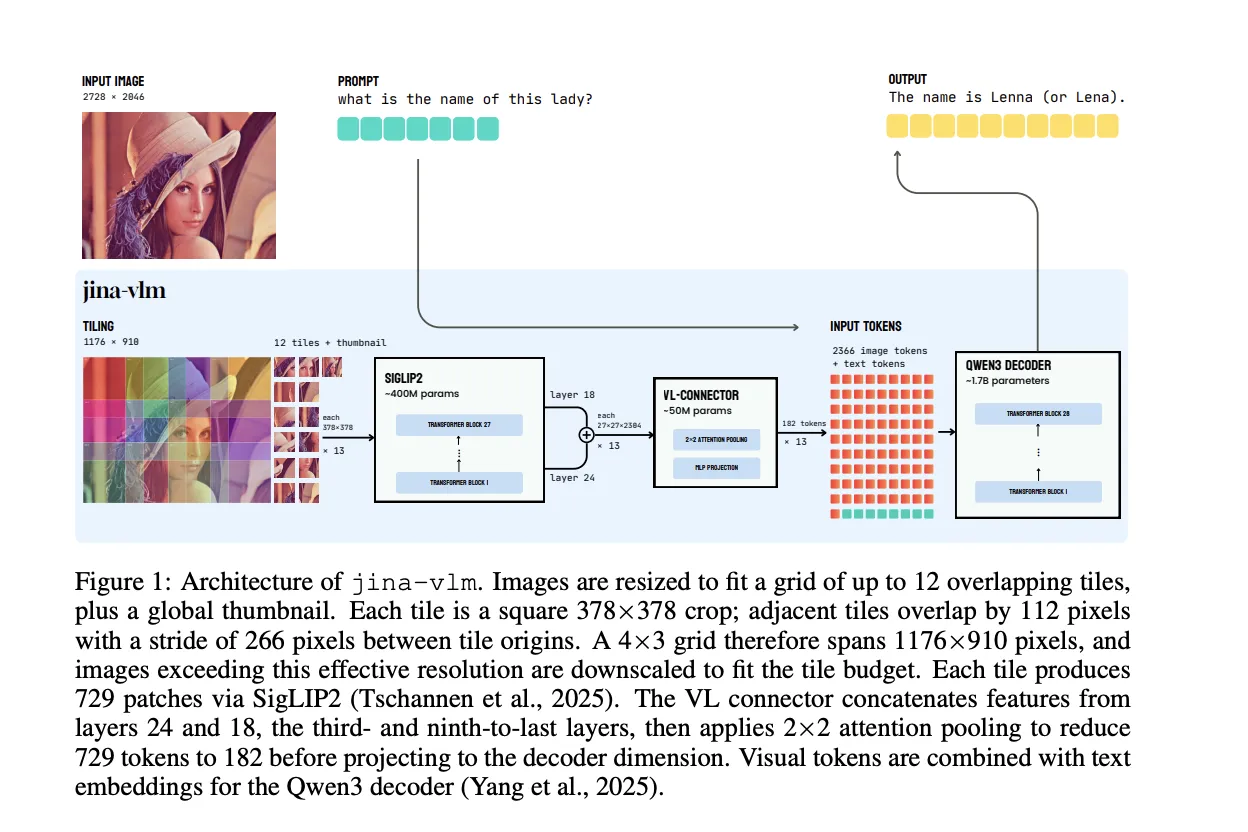
Buildings, tiles overflow with attention connector
Jina-VLM maintains the standard architecture of VLM, but optimizes the Vision side of the argument resolution and low token count. Vision Encoder is Siglip2 So400m / 14 384, 27 Layer Lom Transformer with parameters about 400m. It processes 378 × 378 Pixel objects in a 27 × 27 grid of 14 × 14 patches, so each tile generates 729 tokens.
To handle high resolution images, the model does not increase the power of full coverage in one scene. Instead, create a grid of up to 12 full tiles and a global icon. Each tile is a 378 × 378 crop, adjacent tiles stack at 112 pixels, and a line between Tile Origins is 266 pixels. A 4 × 3 grid that includes a working resolution of 1176 × 910 pixels before shrinking larger images to fit within the tile budget.
The basic design is the State Language connector. Instead of using the last vit layer, Jina-VLM Conc the features from the two middle parts, the third from the last and the ninth from the last, which correspond to layers that are high semantics and details of the mail. The linker then uses Pooling over a 2 × 2 patch of neighbors. It compiles a combined query for each 2 × 2 region, to the full feature map, and outputs one combined token for each region. This reduces the 729 view tokens per tile to 182 tokens, which is a fourfold compression. The Swiglu Projection places the composite features on Qwen3 that extract the dimensions.
With a default configuration of 12 tiles and an icon, the innocent connector will feed 9,477 virtual tokens into the language model. A closer look narrows this down to 2,366 visible tokens. The vit accoute doesn't change, but in reverse language this opening is about 3.9 times 3 times If including the shared cost of VIT, the total flops fall about 2.3 times of the default setting.
The language decoder is Qwen3-1.7b-base. The model introduces special image tokens, with
Pipeline training and integration of multilingual data
The training proceeds in 2 phases. All elements, encoder, connector and decoder, are updated together, without freezing. The complete corpus contains approximately 5M samples of multimodal and 12b tokens in more than 30 languages. About half of the text is in English, while the remainder includes high and medium languages and resources such as Chinese, Arabic, German, Spanish, French, Italian, Japanese and Korean.
Phase 1 is alignment training. The goal is to mark the view language, not the following commands. The team uses PixMocap's fast word and disaster, which captures nature photos, documents, diagrams and infographics. They added only 15% data from the Pleias Commuus Corpus to control for corruption in pure language tasks. The connector uses a higher readout rate and shorter warm-up than the encoder and decoder to speed up adaptation without compromising the backbone.
Section 2 is good teaching. Here Gina VLM learns to follow the impulse to answer a visual question and reason. The mix includes LLava Onvi, cauldron, cambike, cambrian and disaster, as well as aya-style multilingual commands only. The jina Research Team trains 30,000 steps with single source batteries, then another 30,000 steps with combined source batteries. This program reinforces learning in the presence of Heterogeneion Gausevision.
Crazy good and beautiful visuals, the model sees about 10b tokens in the first phase and 37b tokens in the second phase, with almost 1,300 GPU hours reported by advanced tests.
Benchmark profile, 2.4B model with various capabilities
For typical English VQA tasks involving drawings, charts, documents, OCR and mixed scenes, jina-VLM achieves an average score of 72.3 out of 8 benchmarks. These are ai2d, chartqa, textvqa, docvqa, infovqa, ocrberch, benchmark 2 plus and charxiv. This is the best comparison between the 2b scale models in this research paper from Jina AI.
In multimoral cognitive tasks and real world cognitive tasks, the model scores 67.4 in the multimodal group, which includes MME, MMB V1.1 and MMSTAR. It gets 61.9 from the real world group, which includes realworldqa, MME Realworld and REBCH, and reaches realworldQA itself, which is the best result among the considered bases.
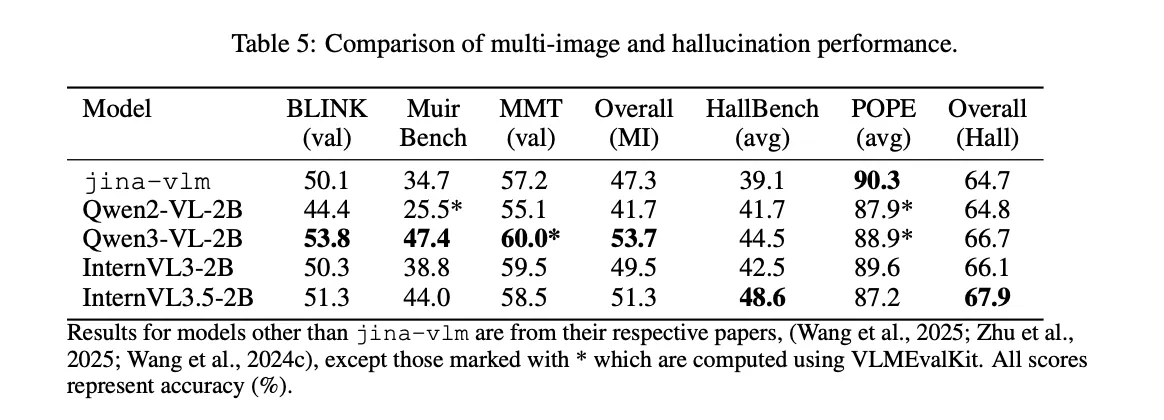
Multiple image consultations are a weak point. In Blink, Muirbench and MMT, Jina-VLM achieves an average of 47.3. The research team points to multi-image training data as the reason. In contrast, hallucination control is tight. In Benny Benchmark, which measures by physical object, the model scores 90.3, the best score in the comparison table.
For mathematical and systematic thinking, the model uses the same construction, except for the thinking mode. It reaches 59.5 in MMMU and 33.3 in mathvista across Mathvista, Mathvision, Mathverse, HeMATH and Logicvista. Jina-VLM is compared to intervl3-2b in this set and clearly ahead of Qwen2-VL-2B, while internvl3.5-bb remains strong due to its large statistical training and special statistical training.
For pure text bangers, the picture is mixed. The Research Team reports that Jina-VLM maintains the performance of Qwen3-1.7B in MMLU, GSM 8K, Arc C and Hellaswag. However, MMLU-Pro dropped from 46.4 for the basic model to 30.3 after multimodal adjustment. The Research Team says that this is the instructional orientation that forces the model into a very short response, which is contrary to the long exciting step suggested by Mmlu Pro.
The most prominent feature of multimodal understanding is limital multimodal. In MMMB Beyond Arabic, Chinese, English, Portuguese, Russian and Turkish, Jina-VLM achieves an average of 78.8. EMMBERENT MMBAULT MMBALIZWONI IN STUDY WEEK, MUST BE 74.3. The research team reports these as ART APPRAGE conditions within the Open 2b Scale VLMS.
Comparison table
| Template | Parallax | VQA AVG | MMMB | Multi. MMB | Docvqa | Ocrbelch |
|---|---|---|---|---|---|---|
| Jina-VLM | 2.4B | 72.3 | 78.8 | 74.3 | 90.6 | 778 |
| Qwen2-VL-2B | 2.1B | 66.4 | 71.3 | 69.4 | 89.2 | The 809 |
| Qwen3-VL-2B | 2.8b | 71.6 | 75.0 | 72.3 | 92.3 | 858 |
| IntervLL3-2B | 2.2B | 69.2 | 73.6 | 71.9 | 87.4 | 835 |
| Internvl3.5-b | 2.2B | 71.6 | 74.6 | 70.9 | 88.5 | 836 |
Key acquisition
- Jina-VLM is a 2.4B parameter vlm that couples siglip2 so400m as a Vision Encoder with Qwen3-1.7b as a reversed language with an interface limited to 4-times tokens while maintaining local structure.
- The model uses 378 × 378 378 tiles, 12 tiles and a global icon, to handle visual images of up to 4K resolution, and consumes a visual size of llm that reduces flops and 4 times.
- The training uses about 5M Multimodal samples and 12b tokens in all 30 languages for a phase 2 pipeline, matching the description style, then good teaching with LLAVA, fangealians, fangevisions and multilingual message sets.
- In English VQA, Jina-VLM reaches 72.3 average across all 8 VQA benchmarks, and in multimodal multi-language scores it leads to an open class of 28.8 in MMB.
Look Paper, detailed HF model and technical specifications. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



