Labs prefer releasing Tabpfn-2.5: The latest version of Tabpfn that unlocks the rate and speed of Tabular base models

The details of the table are still there when most of the important models are working in production. Financial, health, energy and industrial groups work with tables of rows and columns, not images or long text. Previous Labs now transfer this space with Tabpfn-2.5The new Tabular Foundation Foundation model scales learning to 50,000 samples and 2,000 features while maintaining a free workflow.
From Tabpfn and Tabpfnv2 to Tabpfn-2.5
The first tabpfn showed that the transformer can learn the bayesian process as an inferesian for measuring the artificial functions of the table. Handled up to 1,000 samples with numerical cleaning features. Tabpfnv2 extended this to real-world data. It added support for categorized items, missing values and vendors, and was valid for up to 10,000 samples and 500 features.
Tabpfn-2.5 is the next generation in this line. The front labs state that it is best for datasets of up to 50,000 samples and 2,000 features, which is 5 times the increase in rows and 4 times the increase in columns over Tabpfnv2. That gives about 20 times the data cells in the supported state. The model is expressed by tabpfn A Python package and with an API.
| A feature | Tabpfn (V1) | Tabpfnv2 | Tabpfn-2.5 |
|---|---|---|---|
| Max's Lines (Recommended) | 1,000 | 10,000 | 50,000 |
| MAX Features (Recommended) | 100 | 500 | 2000 |
| Supported data types | Only numbers | – Mixed | – Mixed |
In the case of reading tables
Tabpfn-2.5 follows the same integrated network concept as previous versions. It is a state-based Transformer-based model used in contextual learning to solve tabular prediction problems in forward-passing. During training, the model is meta-trained on a large distribution of tabular functions. In the calculation phase, you pass the training lines and labels and test lines together. The model runs a single pass forward and predictive model, so there is no dataset-specific gradient descent or hyperparameter search.

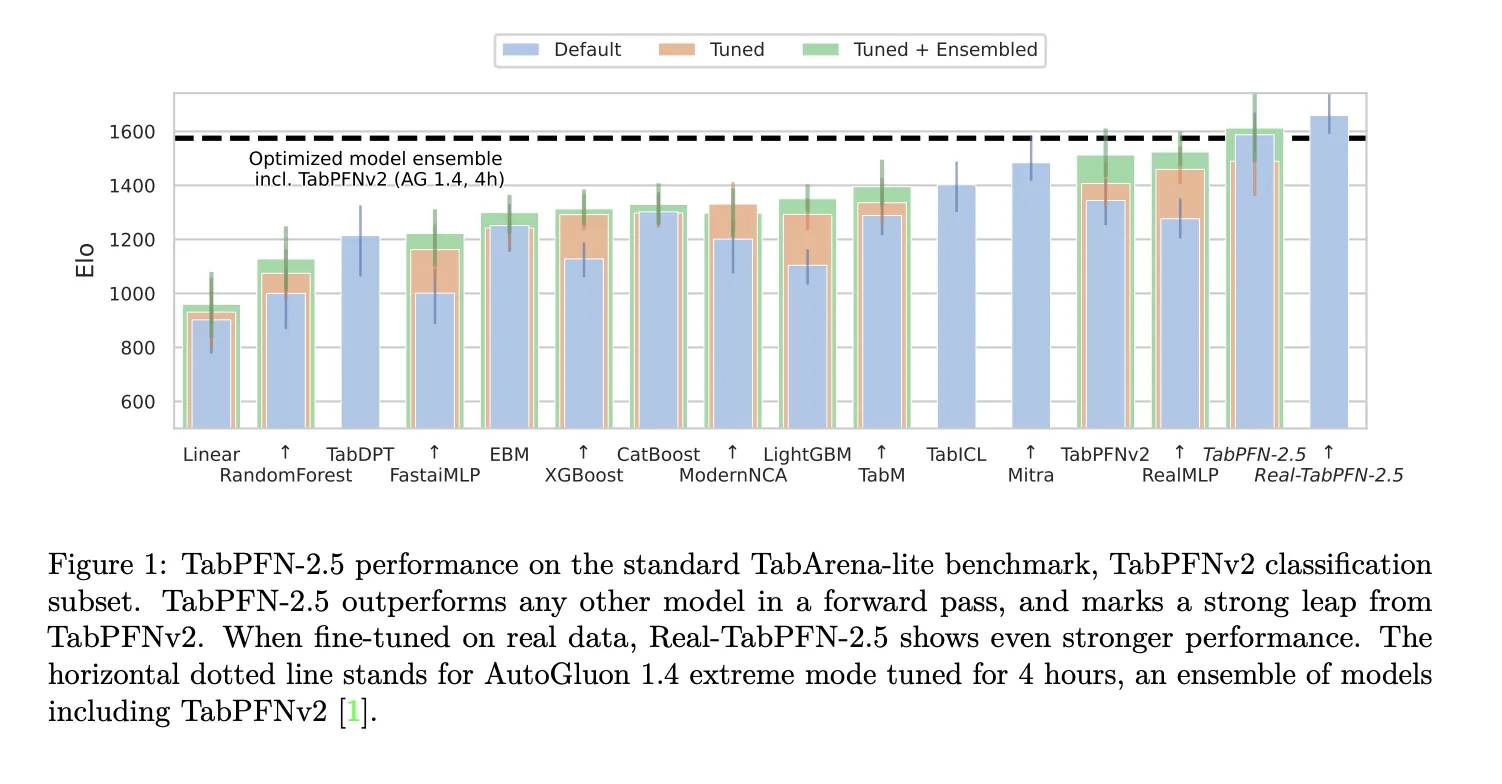
Benchmark results in Tabarena and realcase
The research team uses the Tabarena Lite Benchmark to measure mid-range operations with up to 10,000 samples and 500 features. Tabpfn-2.5 In Forward Offectffs any other model in comparison. When the Tabpfn-2.5 variant was optimized for real datasets, the lead increased significantly. Autogluon 1.4 in Normal Mode is the dominant baseline, scheduled for 4 hours and including TabpfNV2.
At industry standard levels with up to 50,000 data points and 2,000 features, Tabpfn-2.5 warms up to prepackaged drug models such as xgboost and catboost. In the same benchmarks as autogluon 1.4, which runs a complex tunnel organization.
Model building and training setup
The construction of the model follows the TabpfFNV2 with alternating and 18 to 24 layers. Alternating means that the network moves to the axis of the sample and the axis of the feature in different phases, which emphasizes the synchronization of cleaning over rows and columns. This design is important for tabular data where the order of rows and the order of columns do not control the data.
The training set maintains the initial learning view of the data. TabPFN-2.5 uses artificial functions of the table with different manipulation properties and data distribution as its meta-training source. Use Real-Tabpfn-2.5 Continuous use of real tabular data sets from repositories such as OpenML and Kaggle, while the team carefully avoids test benches.
Key acquisition
- Tabpfn 2.5 Scales previous data entered by tabular transformers into approximately 50,000 samples and 2,000 features while maintaining a single pass, no workflow.
- The model has been trained for the artificial tasks of the table and tested in Tabarena, the internal benches of the industry and innovation, where it started, where Outperforms tuned the medicine based and the uniformity of the benches in size.
- Tabpfn 2.5 maintains the style of Tabpfnv2 Transformer exchange for lines and features, which allows the allowed synchronization of tables and reading content without work.
- The decoration engine turns the TabpFN 2.5 into a compact MLP or tree MANSH BANDSEBA students who keep most of the accuracy while providing the lowest area and connecting the deployment to the existing areas of the table.
Tabpfn 2.5 is an important release for tabular machine learning because it transforms the model and hyperparameter selection in a single pass of sampling up to 50,000 samples and up to 2,000 features. It includes artificial meta training, excellent maintenance of Tabpfn-2.5 and a decoration engine for MLP and TreerPrens readers, with a clear non-commercial license and business method. Overall, this release replaces the previous database used for real table problems.
Look Paper, Model tools, repo and Technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of the intelligence media platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



