
In this post, I will present a reinforcement learning (RL) algorithm based on the “Alternative” Paradigm: Divide and conquer. Unlike traditional methods, this algorithm -I It is based on temporal difference (TD) learning (with scalability constraints), and scales well for long tasks.
We can calculate reinforcement (RL) based on division and conquest, instead of temporal difference (TD).
Problem Classification: Off-Polip RL
The Classification of Our Problem Off-Polip RL. Let's briefly review what this means.
There are two categories of algorithms in RL: in RL policy RL and off-coplan rl. On-Police RL means we can -one Use the new data collected by the current policy. In other words, we have to discard the old data each time we update the policy. Algorithms such as PPO and GRPO (and general policy algorithms) belong to this category.
Off-Policy RL means we don't have this restriction: We can use – what? type of data, including past experiences, demographics, internet data, and more. So Off-Policy RL is more general and flexible than Policy RL (and really hard!). IQ-Learning is a well-known RL algorithm. In domains where data collection is expensive (e.g, robotsChat systems, health care, etc.), we usually have no choice but to use RL-Policy RL. That is why it is such an important issue.
As of 2025, I think we have good balanced policy recipes (e.gPPO, GRPO, and their variations). However, we still haven't found “rated” Off-Polip RL Algorithm that efficiently scales complex, long-term tasks. Let me briefly explain why.
Two paradigms for quantitative learning: temporal difference (TD) and Monte Carlo (MC)
In the Off-Poliz RL, we often train the value function using temporal difference (TD) (i.eQ-Learning), with the following Bellman renewal rule:
[begin{aligned} Q(s, a) gets r + gamma max_{a’} Q(s’, a’), end{aligned}]
The problem is: The error in the next value $ Q (s', a') $ is propagated to the current value of $ Q (s, a) $ by using errors accumulate over the whole universe. This is basically what makes TD reading a struggle against long tasks (see this post if you're interested in more details).
To alleviate this problem, people have come across TD and Monte Carlo (MC) learning. For example, we can do $ N $ -Tep TD Learning (TD- $ N $):
[begin{aligned} Q(s_t, a_t) gets sum_{i=0}^{n-1} gamma^i r_{t+i} + gamma^n max_{a’} Q(s_{t+n}, a’). end{aligned}]
Here, we use the real Monte Carlo regression (from the database) with the first $N$ steps, then use the bootstraged value for the at the the the the the the the the the the the the the the the the the the the the the the the the the In this way, we can reduce the number of Bellman iterations by $ n $ Times, so the errors accumulate less. In the worst case of $n =
While this is a reasonable solution (and often works well), it is not very satisfactory. First of all, it's not basically Solve the problem of accumulation error; It only reduces the number of Bellman Represions by a constant factor ($N$). Second, since $ N $ GROWS, we suffer from high and underground diversity. So we can't just set $n$ to a large value, and we need to enter it carefully for each function.
Is there a different alternative way to solve this problem?
“Third” Paradigm: Divide and conquer
My claim is that a – the third paradigm in critical learning, Divide and conquercan provide an ideal off-computer rl solution at scale for long-term operations.
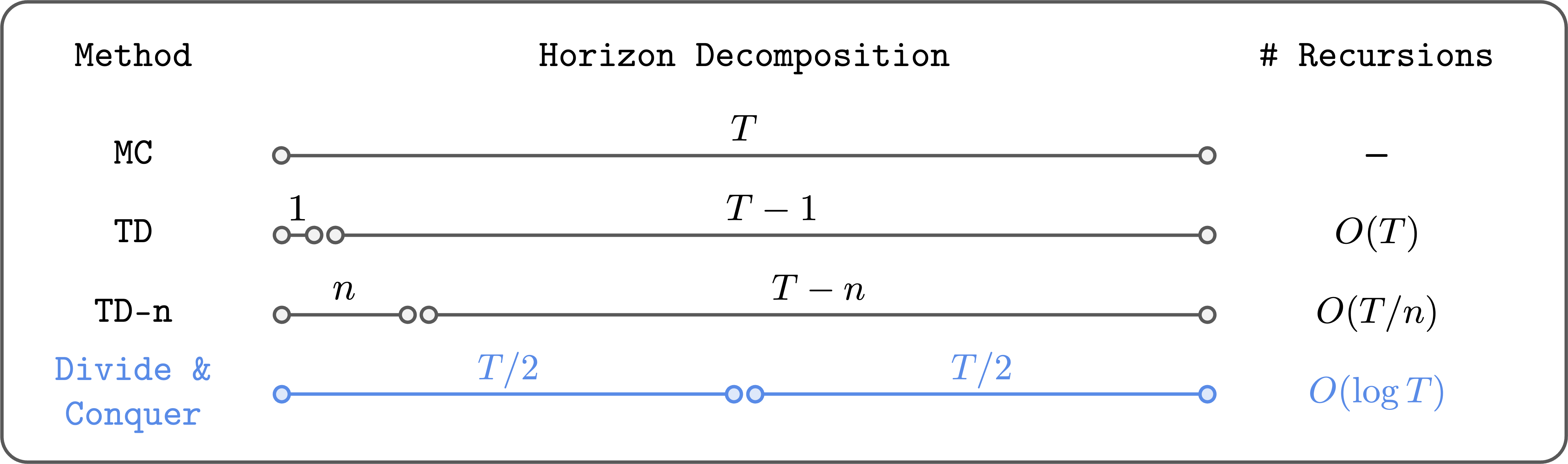
Divide and conquer to reduce the amount of Bellman Revelsyworky.
The main idea of divide and conquer is to divide the trajectory into two parts of equal length, and then add their values to restore the value of the complete trajectory. This way, we can (in theory) reduce the number of Bellman Represions logarithmically (not directly!). In addition, it does not need to choose a hyperparepameter such as $ N $, and it does not have a problem with the top or bottom variations, unlike the $ N $-Tep TD
Psychologically, divide and conquer really has all the good properties we want in a value study. So I am happy with this high quality concept. The problem is that it wasn't clear how to actually make this work… until recently.
A working algorithm
In recent joint work with Aditya, we have made significant progress in realizing and embellishing this vision. In particular, we were able to improve differentiation and interactive learning in very complex tasks (as far as I know, this is the first task!) in at least one important class of RL problems, rl with medicine. RL with counter-conditions to read a policy that can access any condition from any other country. This provides a natural structure for divide-and-conquer. Let me explain this.
The plot is next. Let's start by assuming that the dynamic force determines, and means the shortest distance (“temporal distance”) between $ s $ $ g $ (s, g) $. Then, satisfy the triangle inequality:
[begin{aligned} d^*(s, g) leq d^*(s, w) + d^*(w, g) end{aligned}]
For all s, g, w mathcal{s}$.
Numerically, we can similarly translate this triangle inequality into the following “Transitive” The Belman Revise Rule:
[begin{aligned}
V(s, g) gets begin{cases}
gamma^0 & text{if } s = g, \\
gamma^1 & text{if } (s, g) in mathcal{E}, \\
max_{w in mathcal{S}} V(s, w)V(w, g) & text{otherwise}
end{cases}
end{aligned}]
where $ maths math {e} $ is the set of edges in the natural environment graph, and $ v $ is the value function associated with the sparse Reward $ R (s = g) $. For consultationthis means that we can update the value of $v(s,g)$ using two “small” values.
The problem
However, there is one problem here. The argument is that it is not clear how to choose the appropriate location of $W$ in practice. In the settings of the table, we can simply add all the states to find that $ W $ $ is the most important algorithm)). But in progressive areas with large state gaps, we will not do this. Basically, this is why previous works have been assigned to develop the study of the value of divide and conquer, although this idea has been around for thirty years in Kaelbling (1993) – See our paper for more discussions on related works). The main contribution of our work is a practical solution to this issue.
The solution
Here is our main idea: us the conclusion The search space of $ W $ for states from the dataset, in particular, those that lie between $ s $ and $ g $ in the dataset trajectory. Also, instead of searching for $text{argmax}_w$, we compute “argmax”}$ using expectation regression. That is, we minimize the following losses:
[begin{aligned} mathbb{E}left[ell^2_kappa (V(s_i, s_j) – bar{V}(s_i, s_k) bar{V}(s_k, s_j))right] finally {match} ]
where $bar{v} is the target value network, $ell st. 2_ kappa $ reduction of $ (s_appa taken over $
This has two advantages. First, we don't need to search the entire state space. Second, we prevent the overestimation from the $max $ operator by using instead a “SOFTER” Reveary Regression. We call this algorithm RL (TRL). Check out our paper for more information and more discussions!
Does it work well?
The humanoidmaze
problem
To see if our method scales well on complex tasks, we directly tested TRL on some of the most challenging tasks on Ogbench, a benchmark with offline goal RL. We mainly used the most difficult types of humanoidmaze and puzzle tasks with large symbols, 1b. These tasks are very challenging: they require complex skills that are equally integrated 3,000 natural steps.
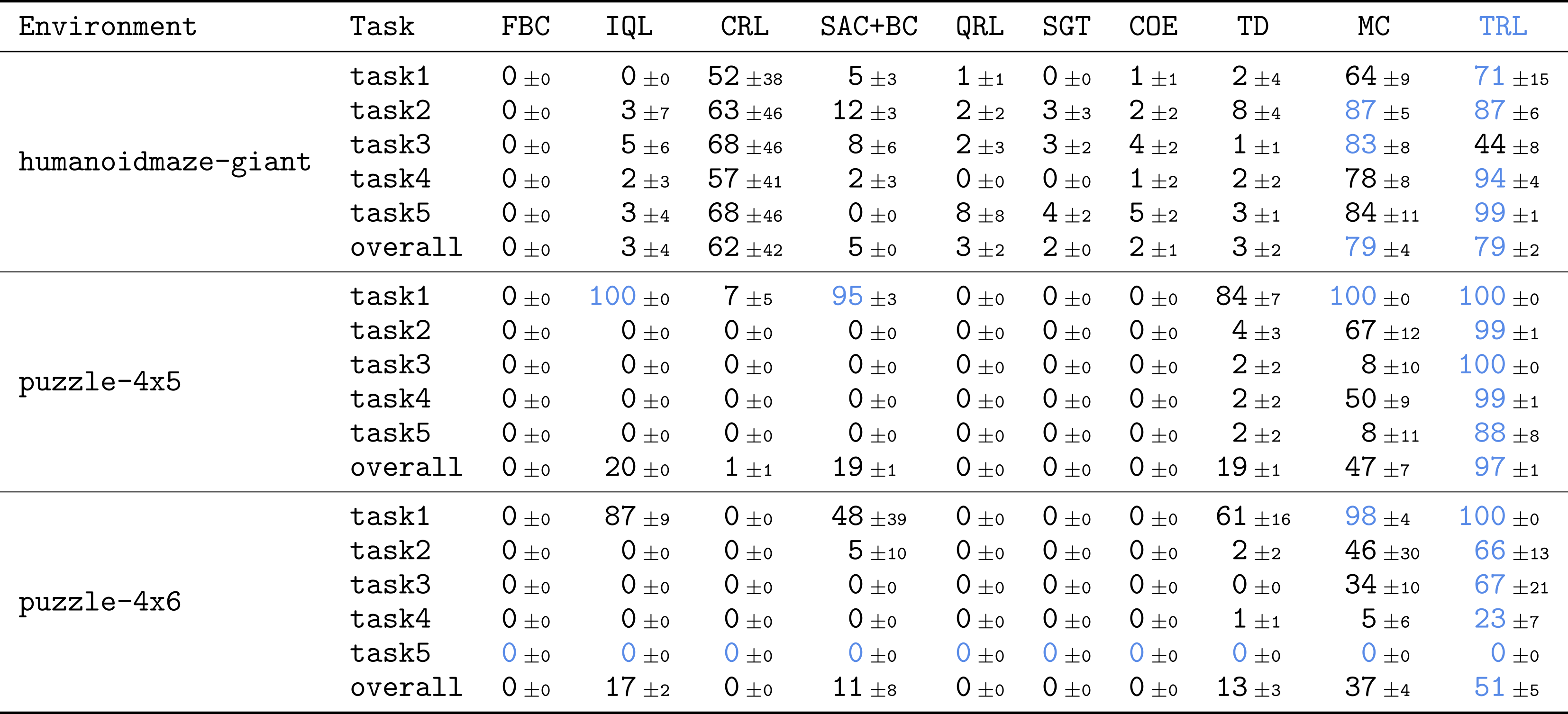
TRL achieves optimal performance in the most challenging, long-elevation tasks.
The results are absolutely delicious! Compared to many strong foundations in different categories (TD, MC, MC, Quasimetric Learning, etc.), TRL achieves excellent performance in many tasks.

TRL is like the Best, organized by TD-$N$, Without needing to set $boldsymbol{n}$.
This is my favorite layout. We compared TRL with $N$-Tep TD readings with different values of $N$, from $1$ (Pure TD) to $MC). The result is really good. TRL is equivalent to TD-$N$ for all functions, Without needing to set $boldsymbol{n}$! This is exactly what we were looking for in the Divide-and-Conquer Paradigm. By redistributing the trajectory into smaller ones, it can traditionally Manage long industries, unless you choose to dictate the length of the trajectory chunks.
This paper has many additional tests, analyses, and deviations. If you are interested, check out our paper!
What's next?
In this post, I shared some promising results from our new Rivide-and Transitive RL algorithm. This is just the beginning of the journey. There are many open questions and interesting clues to explore:
-
Perhaps the most important question is how to extend TRL to general tasks, based on revising RL tasks beyond the objective-RL. Would standard RL have a similar divide-and-conquer structure to exploit? I am very optimistic about this, given that it is possible to convert any RL activity based on reward to one goal at least in the imagination (see page 40 of this book).
-
Another important challenge is dealing with stochastic environments. The current form of TRL assumes deterministic forces, but most real-world environments are Stochastic, mainly due to partial recognition. In this case, the “Stochastic” Triangle Inequality can provide some hints.
-
In reality, I think there is still a lot of room for improvement for TRL. For example, we can find better ways to choose suppoltate subgoals (beyond those from the same trajectory), reduce and hyperparameters, strengthen other training, and simplify the algorithm more.
In general, I am very happy with the capabilities of the Divide-and-Conquer Paradigm. I still think that one of the most important problems in RL (and in machine learning) is to find a – measured Off-Policy RL algorithm. I don't know what the final solution will look like, but I think divide and conquer, either -refreshed re-refreshed To make decisions in general, it is one of the most powerful ways towards this sacred girl (by the way, I think that other strong fighters are (1) model-based RL and (2) TD learning). Indeed, several recent works in other fields have shown the promise of replication and the creation of strategies, such as shortcut models, linguistic return models (also, classic models such as QuickSort, part trees, FFT, etc.). I hope to see exciting progress with Scale Off-Policy RL soon!
Acceptance
I would like to thank Kevin and Sergey for their helpful feedback on this post.
This post originally appeared on Seohong Park's blog.



