OpenAI releases research preview of 'GPT-OSS-Safe Guard': Two top open thinking models for security classification tasks

Openai has released a GPT-OSS-Sferictuard research proposal, a high-level security thinking model that allows developers to implement security policies during security. The models come in two sizes, GPT-OSS-SafeGuard-120B and GPT-OSS-SafeGuard-20BBoth of them are compiled from GPT-OSS, both are licensed under Apache 2.0, and both are available for local use.
WHY THE ANSWERS TO THE QUESTIONS?
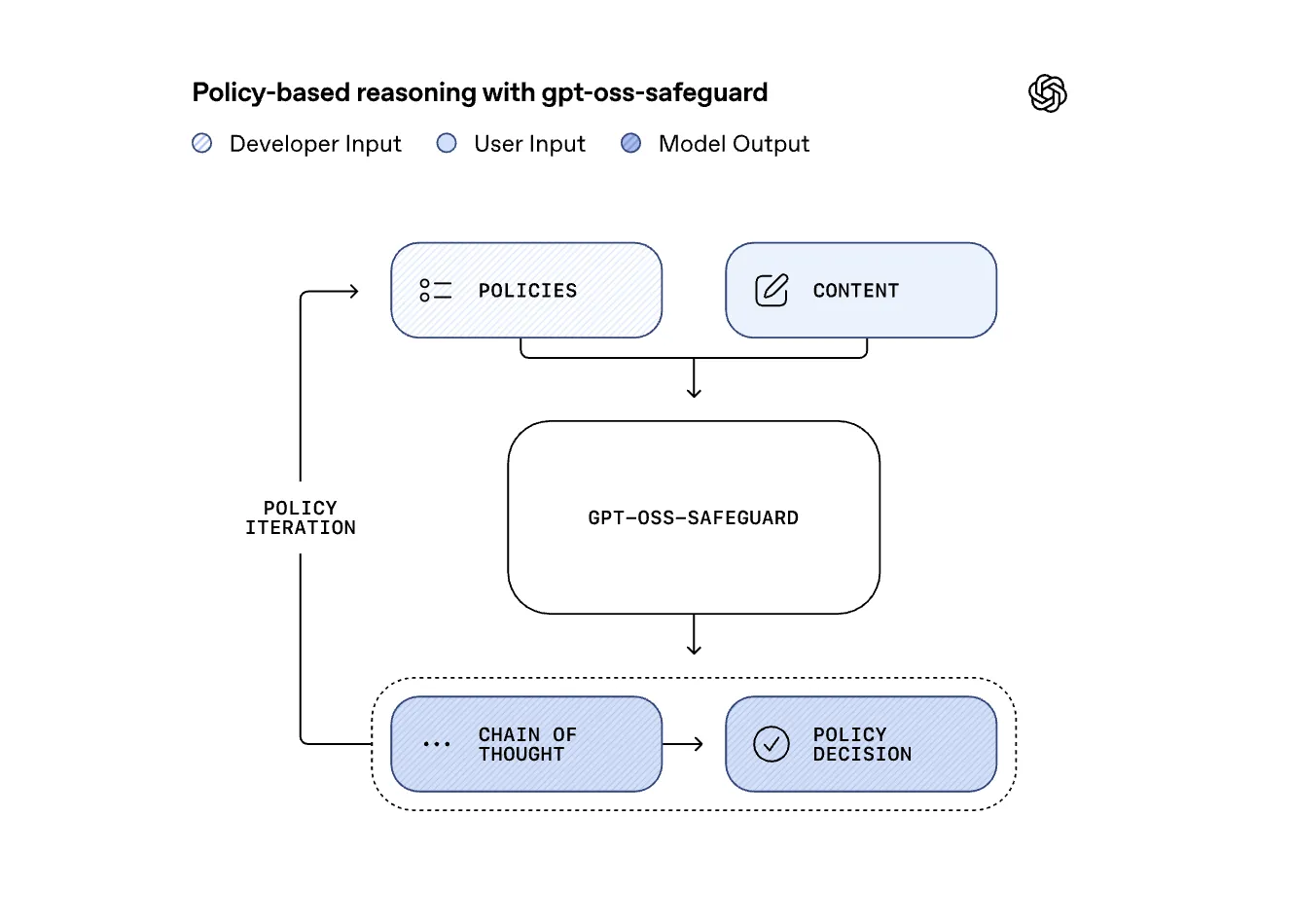
Common types of measurement are trained on one set policy. When that policy changes, the model must be retested or replaced. GPT-OSS-Safe Guard reverses this relationship. It takes the approved developer as the policy and the user content, then the step-by-step reasons to determine whether the content violates the policy. This turns safety into a quick and experimental task, which is better suited to changing dynamics or domains such as fraud, biology, self-harm or some harm or some abuse or some harm or some abuse.
Same pattern as OpenAi's Internal Security
Opelai says that the GPT-OSS-Safe Guard is the use of the open weight of the security reason used within programs such as GPT 5, then about 16 objects of Open Constering, and about 16 months of computation have been used for the complete thinking. An open release allows third parties to re-expose this deep defense pattern instead of guessing how the OpenAi stack works.
Model sizes and hardware fit
The largest model, GPT-OSS-Safeguard-120B, has 117b parameters with 5.1B active parameters and is sized to fit a single 80GB H100 Class GPU. Getr-OSS-eSfec-Safeguard-20B has 21b parameters with 3.6B active parameters and low shoulders or small gpus, including 16GB setup. Both of these models are trained in a consensus response format, so it must follow that structure or the results will be biased. The license is Apache 2.0, the same as the Parent GPT-OSS model, so commercial distribution is allowed.

Test results
Opena tested the models in Multical policy evaluation and Data. With multiple policy accuracy, where the model must correctly use several policies at the same time, GPT-OSS-Safe Gunder Protecform GPTS-5-Chingful and GPT-OSS open bases. In the Dataset of 2022 for measuring new models gradually come out GPT-5-Considering and the internal reason of security, but Opelai specifies that this gap is not statistically significant, so it should not be considered. At Toxicchat, internal security reasons are still alive, with GPT-OSS-Viseguard close behind. This puts open models in a competitive position with real measurement tasks.
It is recommended to send a pattern
Opelai is clear that pure thinking in all applications is expensive. The recommended setup is to run small, fast, high-memory Classifiers on all traffic, then send uncertain or sensitive content to GPT-OSS-Safe Guard, and when the user experience requires fast responses, to work with fast reasons, to work with fast reasons. This mirror of Opelai's own leadership and shows the fact that works dedicated to dedication can win when there is great quality assigned to the label.
Key acquisition
- GPT-OSS-SafeGuard is a research preview of the high-level security models for security, 120b and 20B, which separates content using developer-supplied policies, so policy changes do not need to be rolled back.
- The models use the same experied templovity aupelai that uses inside all GPT 5, Chatgpt Agent and SORA 2, where the first quick content that is dangerous or strange in the slow consultation model or strange in the slow consultation model.
- Both beautiful models are programmed from GPT-OSS, last to respond with Harmony Respont, and are separated by 120B Model on one GPU of H100, target Apache 2.0 in face kissing.
- In the internal evaluation of Multis policy and benchmark data, ExePerform models GPT-5-Conform and perp-OSS Basheline, but Opelai notes that the minimum margin of safety is not statistically significant.
- OpenAI recommends using these models in Pipelines, as well as public resources such as ROOST, platforms such as taxomonties, and renewing policies without touching the instruments.
Opena takes the internal security pattern and makes it part reproductive, which is the most important part of the system. The models are open weight, included with policy and apache 2.0, so platforms can end up using their taxis instead of accepting fixed labels. The fact that the consistency of GPT-OSS-Viefeluard and sometimes exceeds the Safer Internal Security in the 2022 benchmark database, while the accuracy of the GPTS-5 policy appears, shows that the method is very important, it shows the method that is already usable. The basic transmission included is the actual production.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.
 Method That Reduces Doom Loops in Consulting Models")

 Open Model with 21B Functional Parameters and 256K Content")
