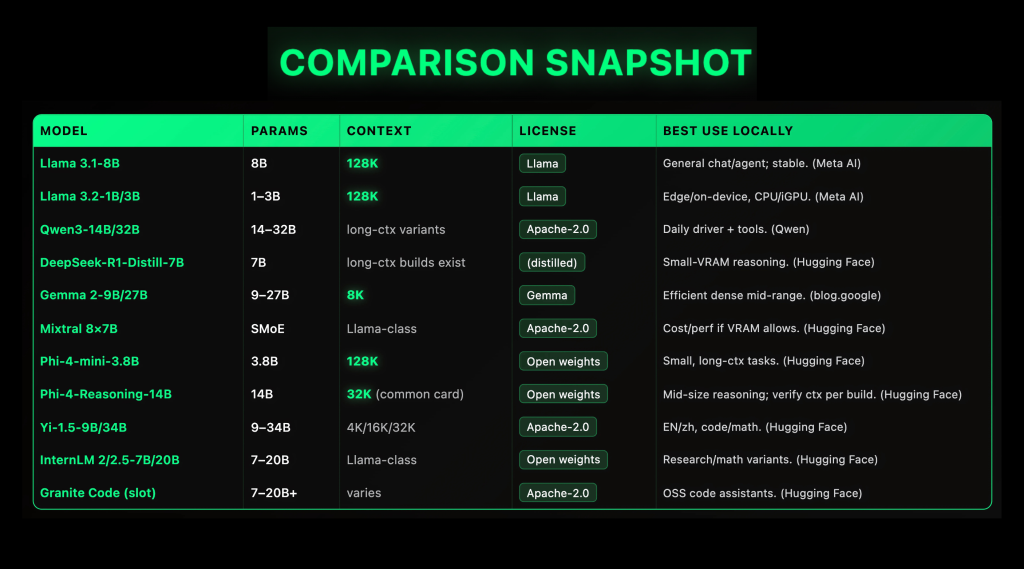
Top 10 (2025) LLMS (2025): Windows Content windows, targets of Vram, and licensed
 LLMS (2025): Windows Content windows, targets of Vram, and licensed")
Location llms is taken immediately by 2025: open families such as LLAMA 3.1 (Length of 128k (CTX)), QWEN3 (Apache-2.0, Moe + Moe), Gemma 2 (9B / 27B, 8K CTX), Mixtral 8 × 7B (Apache-2.0 SMOE)beside Pho-4-mini (3.8B, 128K CTX) Now send reliable Specs and the first level of local (GGUF /llama.cppLM Studio, Ollama), to do PrEP and active laptop display if you match the psychiatric and the quantity of the Vram. This guide lists ten usable options for the clarification of the license, the availability of GGufs, and recycled work signs (CTX), SPRets).
Top 10 llms (2025)
1) Meta Llama 3.1-8b – the “Daily Day Driver,” 128K the context
Why is important. The stable foundation, with many long languages of context and first support from local tools.
Specs. Dense 8b decoder; official 123k core; -Read-planned and variable variations. LLAMA's license (open weights). Normal GGUF and OLLAMAs are available. Typical Setting: Q4_K_m / Q5_K of ≤12-16 GB VRAM, Q6_K for ≥24 GB.
2) Meta Llama 3.2-1B / 3B – Edge-Class Category, 128k Context, In-Device
Why is important. Small models still take 123k tokens and run in an acceptable way in CPUS / ILPUS where heightened up; Ready for laptops and mini-pcs.
Specs. 1B / 3B models are organized; The 128k context is confirmed by the meta. Works well with llama.cpp GGUF and LM Studio's Runtime Cruntime CRUDIME (CPU / Cuda / Cuda / Vulkan / Metal / Rocm).
3) QWEN3-14B / 32B – Open Apache-2.0, Use of Strengthen Tools & Multiple Languages
Why is important. Wide family (Mente + Moe) under Apache-2.0 With applicable ports in GGUF; It is very reported as the General General / Agentic driver “every day”.
Specs. 14B / 32B Checkpoints have a long ax to be. Modern Tokenzer; Update of the quick Ecosystem. Start in Q4_K_m of 14b in 12 GB; Move to Q5 / Q6 if you have 24 GB +. (Qwenen)
4) Deepseek-R1-DISTILL-QWEN-7B – CONTRACT RELATIONS
Why is important. Reduced from R1-style to consult with traces; It moves the action quality by step by 7b with more accessible gguffs. Very good for statistics / install codes in the modest vram.
Specs. 7b alinking; The longest contexts exist in some transformation; The best ggufs cover F32 → Q4_K_m. On the 8-12 GB Vram Try Q4_K_m; For 16-24 GB Use Q5 / Q6.
5) Google Gemma 2-9B / 27B – decorative; 8K context (clear)
Why is important. A strong quality of moral and quantity; 9B is a major model of the center area.
Specs. Heritage 9B / 27B; 8When the context (not over-use); open metals under gemma conditions; is fitted llama.cpp/ Ollama. 9B q4_k_m works on multiple 12 GB cards.
6) Mixtral 8 × 7B (SMOE) – Apache-2.0 Sparse Moe; Cost / Workkhorse Workkhorse
Why is important. Benefits of Decorating the Combinations without compatible: ~ 2 experts / selected token at work; Supporting good when you have ≥244-48 GB vram (or multi-gpu) and you want normal normal performance.
Specs. 8 B professional of each (Act Ringeration Sparse; Apache-2.0; Coming / basic bases; GGUF modification and Ollama recipes.
7) Microsoft pori-4-mini-3.8B – Small model, the context of 128k
Why is important. Realistic thinking “Reasoning according to smaller foundation” with 123k The attention of the context and the attention of the collected tight of the CPU boxes / GPU and the latency sensitive tools.
Specs. 3.8B Meene; The vocab of 200k; Soft / DPO compliance; Model card documents 123k The context and training profile. Use Q4_K_m to ≤8-12 GB Vram.
8) Microsoft Indi-4 – Reasoning-14b – Reasoning in the middle of size
Why is important. 14B of 10B Consultation – Schedulable for the best of the chain-styles styles and general levels of Generic 13-15b.
Specs. Gentle 14b; The context varies by distribution (Model card model of standard issues 32). With 24 GB vram, Q5_k_m / Q6_K comfortable; Mix-Preciention (non-gguf's) runners need more.
9) by 1.5-9B / 34B – Apache-2.0 two languages; 4k / 16k / 32k various
Why is important. Competing of en / ZH to work and a valid license; 9B is one strong way of Gemma-2-9B; 34b steps look at the higher thoughts under Apache-2.0.
Specs. Gentle; Versation 4k / 16k / 32k / 32k; Open the weights under Apache-2.0 with active HF cards / repos. With 9b Use Q4 / Q5 at 12-16 GB.
10) Interllm 2 / 2.5-7b / 20b – Research – Research; Math-Tune branches
Why is important. Open series with a happy religious research; 7B is a place of place of place; 20b impels you of Gemma-2-27B-Class Power (at high viram).
Specs. Tacked 7B / 20B; Many conversations / basics / different statistics; HF performance existence. The conversion of GGUF and Ollama packets.
Summary
Local llms, trading clear: Select dense Latency models are predictable and simple (eg. sparse moe such as Mixtral 8 × 7b where your Vram and the same as your Vram updates each of the top cost, and treatment Minor Reasoning Models (Pho-4-Mini-3.8b, 128k) as a pleasant place for CPU / GPU boxes. Licenses and ecoituisms and ecache-2.0 Apache-2.0 card issuers and Metors / Microsoft cards that provide operational Guardrails. On the side of the start time, measurable in the GGUF / LLAMA.CPP To get carriage, layer Ollama / LM Studio For simplicity and hardware offdressable, and the size of the size (Q4 → Q6) in your memory budget. In short: Choose City + License + License + How to HardwareNot just the front boards.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.
🔥[Recommended Read] NVIDIA AI Open-Spaces Vipe (Video Video Engine): A Powerful and Powerful Tool to Enter the 3D Reference for 3D for Spatial Ai



