Polaris-4B and Polaris-7b: After post-statistical reinforce and reasonable consultation

Growing Need for Formal Reference Models In a machine intelligence
Advanced consultation models are on the machine of the machine, especially in the medicines to solve problems and impression. These types are designed to make count of many measures and rational reductions, which often produces solutions that reflect human format. Strengthened learning strategies are used to improve accuracy after pretense; However, measuring these methods while keeping efficiency remains complicated. As demands increases in small models, they work with resources showing high-score indications, researchers now turn to techniques that face data, test methods, and common of context.
The Challenges of Teaching Free Board Learning
Contributable problem by learning the strengthening of high models with mimsmatch between model's ability to train information. When the model is expressed in the simplest job, its reading curve is strong. On the other hand, extreme data can add model and allow it to sign a learning signal. This is equal to the difficulties, especially when the recipients of cooking methods are used to major to major. Another issue is a lack of proper synchronization methods and money laundering during the continuous training and acquisition of compulsory models in the stable benches.
The limitations of existing training methods after training in developed models
The front paths, such as DeepsCaler and GRPO, show that strengthening the verification can improve the performance of models with smaller measurements with 1.5 billion parameters. However, using these same methods in the more skillful models, such as QWEN3-4B or Deepseek-R1-QWen-7b, resulting in marginal or even working drops. One key limit is a type of data distribution and limited sample variation. Most of these methods sort out data based on power models, and solve the sampling temperatures or length of reply. As a result, they often fail to achieve successfully when they are used to build more.
Presented Polaris: Combined Scalable RL recipe in consultation activities
Investigators from the University of Hong Kong, the Fudan Seeds introduced Polaris, a post-trainee training recipe designed to enhance the strengthening of advanced consultation activities. Polaris includes two view models: Polaris-4b-Preview and polaris-7b-View. Polaris-4b-Preview is well organized from qwen3-4b, while polaris-7b-Preview is based on Deepseek-R1-Qwen-QWen-7b. Investigators focus on building a Model-Agnogic Framework that transforms data problems, promotes a variety of assessment using sampling levels, and expansion skills. These strategies are enhanced using open datasets and training pipes, and both models are designed to operate in production units (GPUS).
New polaris: Measurement, controlled sample, and a long inclination
Polaris uses more new. First, training information is deducted by very simple or unsafe problems, creating the distribution of J-Hamms. This ensures that training data comes from the growing model skills. Second, researchers change the sampled temperatures in all 1.4, 1.45, and 1.5 Polaris-4b and 1.1 of Polaris-7b-7b diversity. In addition, the method uses the Ovrapolation process that is based on the O-Yorn Process of Infence to 96k tokens without seeking additional training. This deals with the unemployment of the following training by enabling the brief “train, long” way. The model also uses strategies such as Rollout Short and replacement in intra-batch to protect zero-reward.
Benchmark results: Polaris Experforms Large Commercial Models
Polaris models achieves state-of-ART results in every multiple of mathematical benches. Polaris-4b-viepful recorded 81.2% accurate records in AIED24 and 79.4% on AIED25, out of the same QWen3 qwen3-3b snow It includes 44.0% of the Minvanva, 69.1% of the Olympic bench, and 94.8% in AMC23. Polaris-7b-Preview and act firmly, 72% goals in AIs24 and 52.6% in AIs25. These effects indicate consistent-4-points and grok-3-opus, establishing polaris as a competitive model, has been modified in the Models of the Less Options and 30b business models.
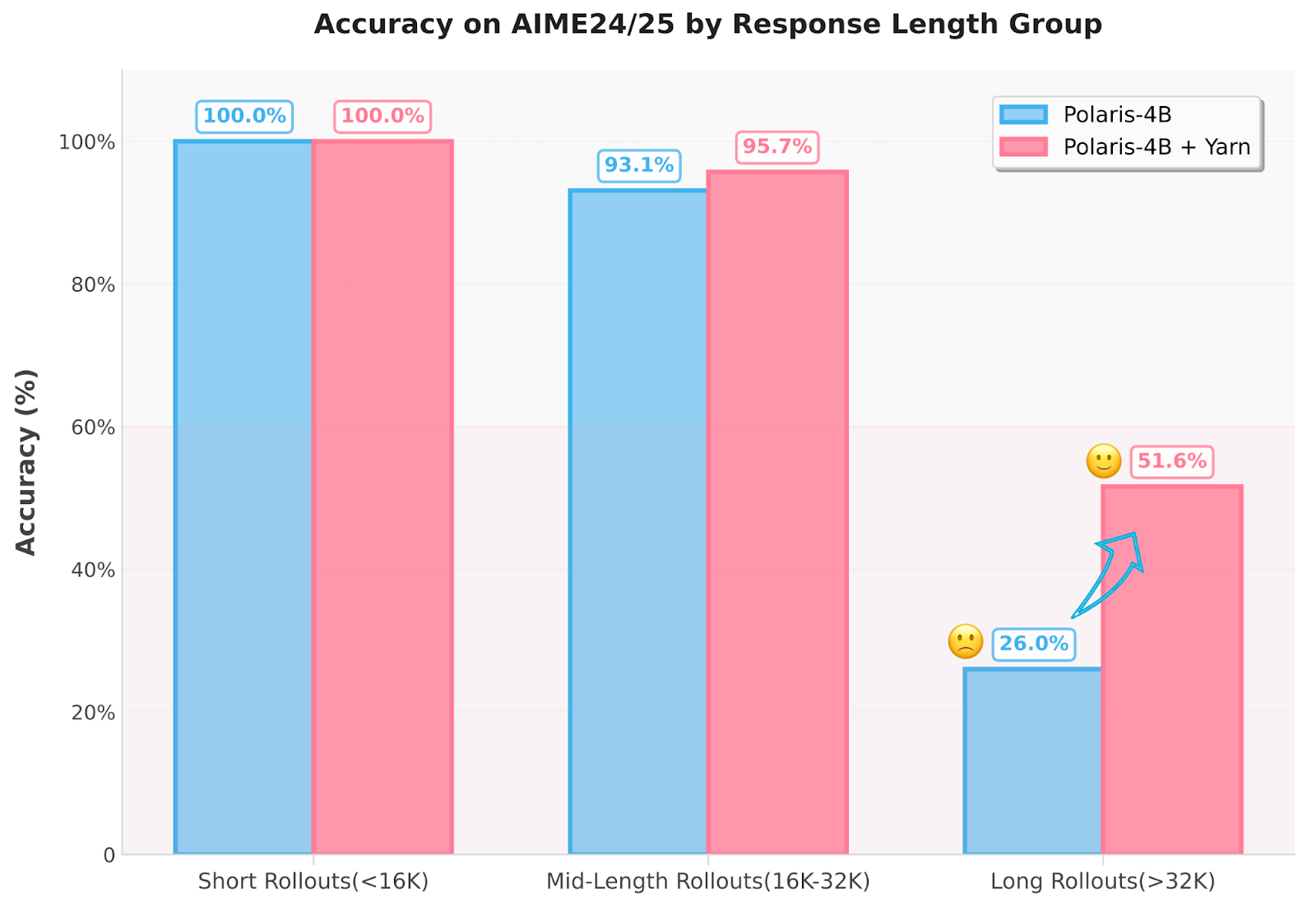
Conclusion: Practical active validity with Smart Post Training Strategies
Investigators show that key measurement models are not just a large model size but control over data for data, sampling and incident length, sampling and infsequence length. Polaris offers a recycled recipe with effective, which allows small models to include the thinking ability of large commercial programs.
Look Model and code. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.




