
That Genai is just a hype pilot or outer sound. I thought that this was the hype, and I was able to stay in this until the dust would remain. Oh, boy, I was wrong. Genai has the actual world applications. It also makes funds available from companies, so we expect companies to invest more in the study. Each time technology is affecting something, the process usually moves in the following categories: Depreciation, Anger and approval. The same thing happens when computers are presented. If we work on a software or hardware field, we may need to use the Gunai at a particular time.
In this article, I cover how to use your application for large languages of languages (Car) And discuss the challenges that I face while I'm on llms. Let's get started.
1. Start by explaining your charge to use clearly
Before jumping to llm, we should ask ourselves some questions
a. What problem is my llm to resolve?
b. Does my plan do without the llm
c. Do I have sufficient resources and integrated power to develop and send this app?
Reduce your case to use and write down. In my story, I worked on a data platform as a service. We had tons of information about Wikis, Slack, Group Stations, etc. We wanted Chatbot and read this knowledge and answer the questions on our behalf. Chatbot will answer customer questions and personal requests, and if customers are no longer sunny, they may be defeated by the engineer.
2. Choose your model
You have two choices: Train your model from scratch or use the previously trained model and build on it. This eventually would work in many cases unless you are responsible for some case. Training your model from the beginning will require a large computer power, important efforts of engineering, costs, among other things. Now, the next question says, which model is a previously trained model to choose? You can choose the model based on your use case. 1B parameter model has basic information and pattern. Use cases can be a restaurant review. The 10B parameter model has the best information and can follow the instructions such as Chatbot food chatbot. The 100b parameter model has the rich worldwide experience and complex consultation. This can be used as a thoughtful partner. There are many models available, such as Llama and ChatGPT. Once you have a position in a place, you can grow in the model.
3. Develop a model according to your data
Once you have a position in a place, you can grow in the model. The llm model is trained for data commonly available. We want to train it in our data. Our model requires an additional context to give answers. Let's think we want to create a Chatbot restaurant that answers customer questions. The model does not know the specified information in your restaurant. Therefore, we want to provide some model volume. There are many ways we can achieve this. Let's get into some of them.
Quick Advancement
Quick engineering involves adding progress in the improvement of more in the form of sight. It gives the context on your installation rating. This is very easy to do and no enhancements. But this comes with their difficulties. You cannot give a great context within hurry. There is a limit in a quick situation. Also, you cannot expect a user to always provide a complete context. The context can be very. This quick and simple solution, but we have many limitations. Here is a sample engineer immediately.
“Sort this review
I love the movie
Review: GoodFilter this review
I hated a movie.
Highlight: BadSort the movie
The end was pleasant “
Strengthened reading about the response of the people (RLHF)

RLHF is one of the most commonly used methods of the llm in the application. You give some data for the learning model content. Here is the following flow: The model takes action from the tail of action and looks at Kingdom change in nature because of that action. Reward model produced a reward position based on output. The model updates its weight correctly to increase the reward and learn about Iteratively. For example, the action is the next producing the llm, and the action area is the dictionary of all words and vocabulary. The nature is the state of the text; The situation is the current text in the Mode window.
The above description is like a book book. Let's look at the real example. Looking for your Chatbot answer questions about your Wiki documents. Now, you choose the previously trained model such as ChatGPT. Your Wikis will be your Mongo Data. You can withstand Langchain library to make the rag. Here is a sample code in Python Code
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "your-openai-key-here"
# Step 1: Load Wikipedia documents
query = "Alan Turing"
wiki_loader = WikipediaLoader(query=query, load_max_docs=3)
wiki_docs = wiki_loader.load()
# Step 2: Split the text into manageable chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
split_docs = splitter.split_documents(wiki_docs)
# Step 3: Embed the chunks into vectors
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(split_docs, embeddings)
# Step 4: Create a retriever
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Step 5: Create a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # You can also try "map_reduce" or "refine"
retriever=retriever,
return_source_documents=True,
)
# Step 6: Ask a question
question = "What did Alan Turing contribute to computer science?"
response = qa_chain(question)
# Print the answer
print("Answer:", response["result"])
print("n--- Sources ---")
for doc in response["source_documents"]:
print(doc.metadata)4. Analyze your model
Now, add RAG to your model. How do you check that your model is treating well? This is not the code where you give some installation parameters and find outgoing, which you can check. As this is a conversation based on the language, either right The answers. But what you don't know exactly whether the answer is wrong. There are many metrics that can test your model.
Analyze
You can regularly check your model by hand. For example, we had covered the Slack Chatbot chatbot that improved in Rag uses our Wikis and Jira. As soon as I added Chatbot to a slack level in Slack, we initially softened answers. Customers could not view the answers. Once we have received confidence, we make Chatbot evident in the community to customers. We examined its response by hand. But this quick and clear way. You can't find confidence in such examination. Therefore, the solution is to test against some bench, such as the Rouge.
Analyze with Rouge Score.
Rouge metrics are used for text summarizing. Metric Reage compares a reproductive summary and reference abbreviations using different rouge metrics. The Metric Rouge tests the model using memory, accuracy, and F1 scores. Rouge metrics come to different types, and negative elimination can lead to good school; Therefore, we refer to different roads of the Rouge. In a particular context, the Unigram is one word; BIGGRAM Two words; And in-gram it is a word n.
Rouge-1 Remember = Unigram Matches / Ungram in Reference
To specify Rouge-1 = Unigram Matches / Ungram at the production of produced
Rouge-1 F1 = 2 * (Remember * accuracy / (Remember + to specify))
Rouge-2 REMPLAL = BIGGRAM / BIGGRAM index
To specify Rouge-2 BIGGRAM MATCH / BIGGRAM IN FROM DEATH
Rouge-2 F1 = 2 * (Remember * accuracy / (Remember + to specify)
Rouge-L Remember = several common / unigram referred to
The accuracy of the rouge-l = several of the most common unigram at exit
Rouge-l F1 = 2 * (Remember * accuracy / (Remember + to specify))
For example,
Clue: “It's cold out.”
Release produced: “It's very cold out.”
Rouge-1 Remember = 4/4 = 1.0
To specify Rouge-1 = 4/5 = 0.8
Rouge-1 F1 = 2 * 0.8 / 1.8 = 0.89
Rouge-2 Remember = 2/3 = 0.67
Rouge-2 Corrections = 2/4 = 0.5
Rouge-2 F1 = 2 * 0.335 / 1.17 = 0.57
Rouge-l Remember = 2/4 = 0.5
ROUGHT-L = 2/5 = 0.4
Rouge-l F1 = 2 * 0.335 / 1.17 = 0.44
Reduce the problem with external bench
The rouge score is used to understand how to work the test model. Some benchmarks, such as bleu score. However, we cannot build a dataset to check our model. We can find tolerate foreign libraries to write down our models. Most usage is the glue benchmark and Supergrunge Benchmark.
5. Do well and send your model
This step may not be tactic, but we reduce computer costs and we get quick results all the time. When your model is ready, you can increase how to improve the performance and reduce memory requirements. We will affect a few concepts that require many engineering, information, time and costs. These concepts will help you get used to certain strategies.
Quantity
The models have parameters, internal variables within the model learned from the data during training and their prices decide how the model makes prediction. 1 parameter usually requires 24 of the Processor memory memory. Therefore, if you select 1B, parameters will require 24 GB memory for processor memory. The size changes model instruments from the high number of templevent Heart-Point to clarify the minimum number of numbers. Changing storage clarification can affect the number of bytes needed to store one weight. The table below shows the opposite of the storage of metals.
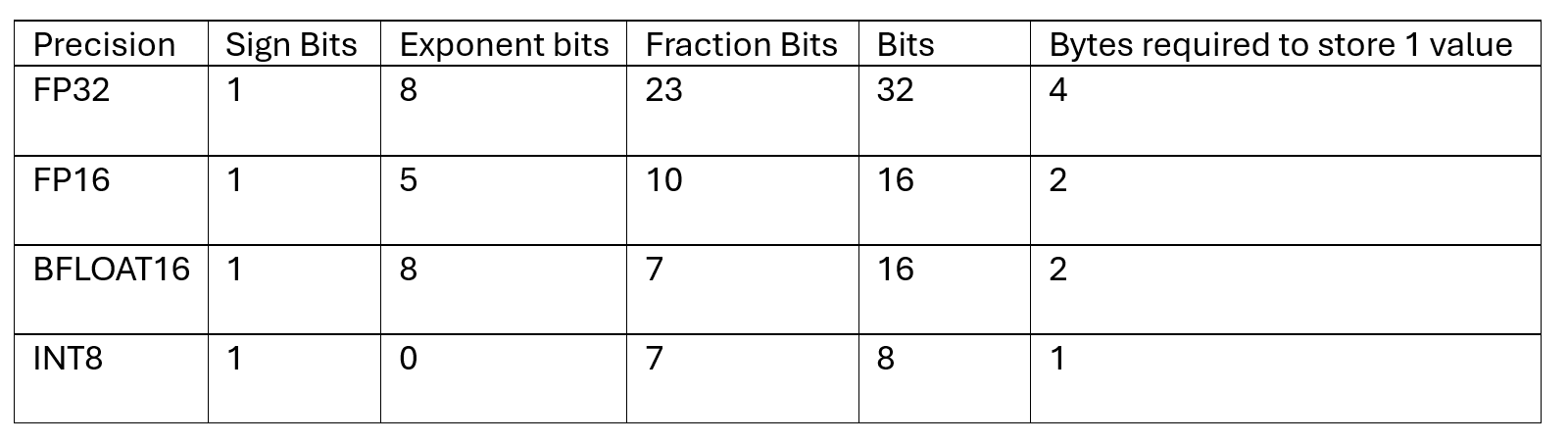
Wall
Trees include deleting metals in a very important model and has little effect, such as metals equal to or close to zero. Other plans to exist
a. Full Reward of Model
b. Peft Like Lora
c. Training in the back.
Store
To carry, you can choose the previously trained model, such as ChatGPT or Flan-T5, and build on it. Creating your pre-training model requires technology, resources, time, and budget. You can correctly fix your use of your use. Then, you can use your llm to use power apps and accompany the charge to use your application using the strategies similar to the RAG. You can check your model against some benches to see if you behave well. You can send your model.



