Google Deepmind investigators opens the power of restoration based on Tabar and Decision

Functions of postponing, involving proof of sustainable numbers, traditionally depends on the heads of the number such as Gaussian Parametzations or Tensors Tensor. These traditional ways have strong distribution requirements, require more installed data, and they often break down when it can be seducing advanced numbers. New research on large language models launches different forms – representing numbers as discrete tokens conflict and using automatic deterioration of predetermination. This change, however, comes with several critical challenges, including the requirement of the form of good things, the right to losing limited accuracy, the need to maintain stable training, and the need to overcome the lack of simplicity. Overcoming these challenges will lead to more powerful, efficient and unchanging framework, thus using the use of deep learning models exceeding traditional ways than traditional ways exceed traditional ways.
Traditional models depend on the number of numbers or heads Afrika Ham'thitulith, like a Gaussian model. While these common ways are full, they also have a number of problems. Gaussian-based models have drawback to take the most commonly distributed results, limiting the ability to display the most advanced distribution, multimodals. Heads of Restoration points are fighting non-line or uncomprehensive relationships, which prohibits their general powers in different datasets. Higher models have higher circumstances, such as the Histogram-based histogram distribution and Data-broad and, therefore, are not working. In addition, many indigenous methods require clear clarification or output, add an additional layer of difficulty and ungodliness. While the general work has tried to recruit the text-to-reset using large language models, performed a formal small work in “any text of the text” to be introduced to the new paradegam of prices.
Investigators from Google Deepmind suggests another way of reinstatement, redirecting the numbers as a chronological order of default order. Instead of producing scalcar prices directly, this method includes numbers as Token sequence and uses compulsory constipation to produce output. Installing the amounts of the amounts as follows the consecutive of the token makes this approach fit and sound when symbolizing real-time information. Unlike Gaussian-based methods, this method does not include solid consideration of distribution about data, thus making it a perfect factor in real world activities with heterogene patterns. The model uses accurate models of multimodal models, complex distribution, thus developing its operation in the estimation of the DENDIs and restoration functions. By installing the Benefits of Autoregroune Concher, it benefits the latest language progress while storing competitive operations that are related to normal number. This construction produces a strong and variable framework that can indicate a variety of numbers in the number of numbers, provides effective illegal opportunities for ordinary procrastination.
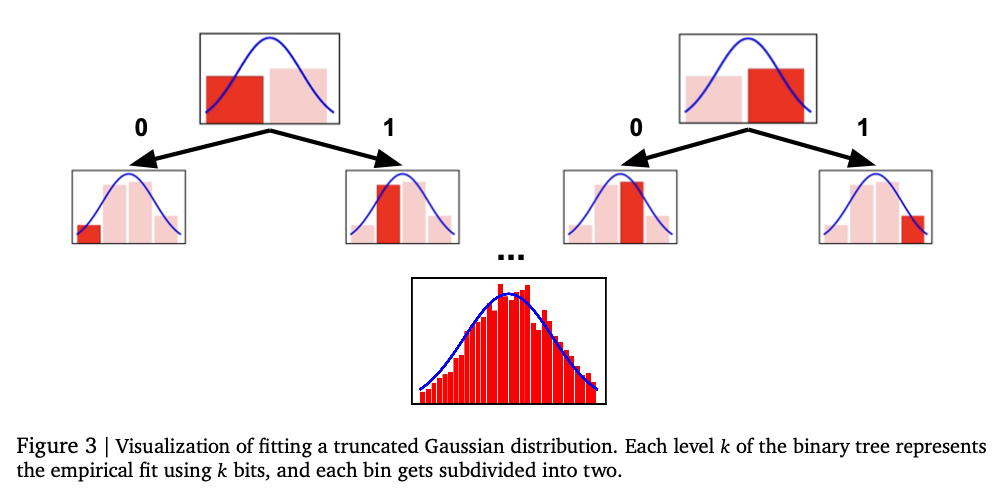
This method uses two types of numbers for numbers: Normal Tokokouday and unique ancestors. Normal Tokenzation numbers include moderate-level numbers with base-B to expand for providing accuracy with the subordinate length. Cothenzation unique transmits the same idea of extensive numbers with the best coins of IEEEEE-754 without a clear clarification requirement. TransformMER auto-regressive model produces a number token in terms of issues to provide valid sequence. The model is trained using a cross-entropy loss over the order of the token to provide accurate representation of numbers. Instead of predicting a scalar disposition directly, the Token system of the token and uses mathematical measurements, such as profanity or final integration, final predictions. The analysis is made to the Tabular Regressional Database of OpenML-CTR23 benchmarks and Amlb Benchmarks and compared to the Gaussian mixture, Histogram Restore, and standard postgraders. Hyperparameter Tuning is made in all various decoder settings, such as variations at the price of layers, hidden units, and the names of convention, providing well performed performance.
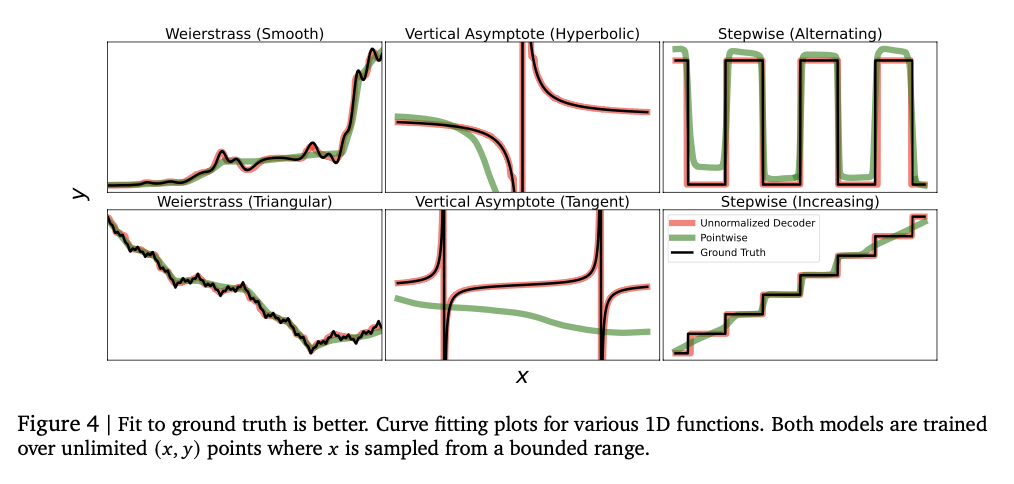
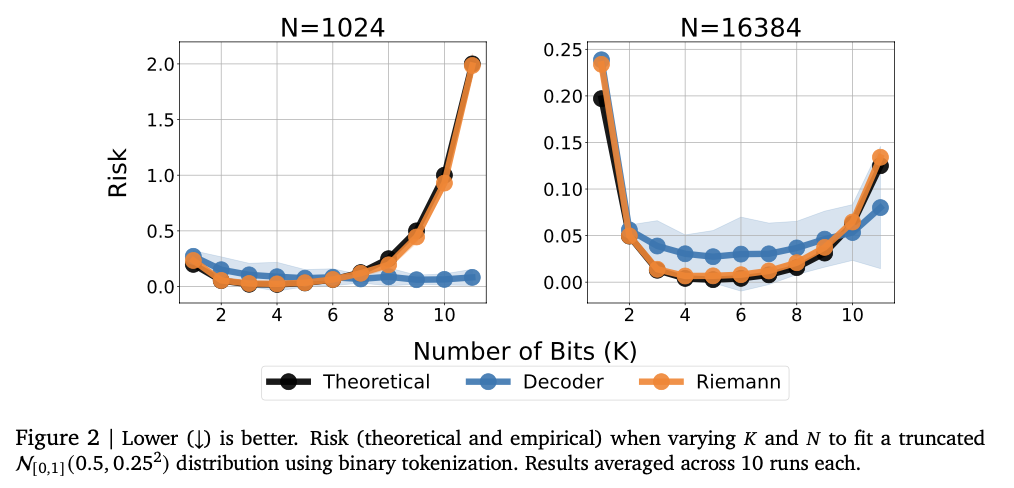
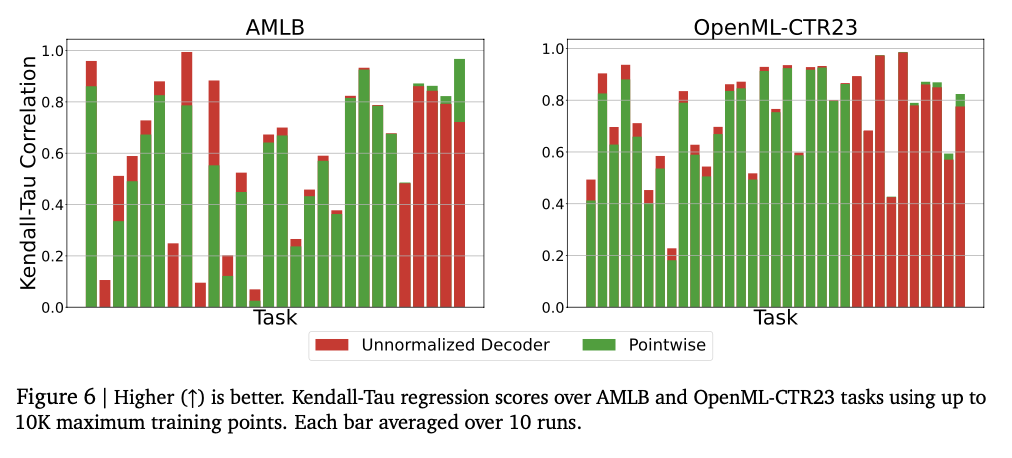
The test shows that the model is successfully inclusive of complex numerical relationships, achieving strong performance in various recycling activities. Finds the KendaLall-Tau high school scores, usually the basic models are high, especially in low data settings where numerical intensity is important. This approach is also better in difficulties, successfully capturing complex distribution and mixture of gaussian gierunn-based mixture in unpleasant test tests. The model size arrangement originally improves the operation, highlighting the cause of excessive overcrowding. The numerical intensity is highly developed by repairing errors such as reinforcement and voting, reducing the risk to the sellers. These effects make this framework of a repression framework into a solid and variable in traditional ways, reflects its powers that effectively effectively for all various information and modeling activities.
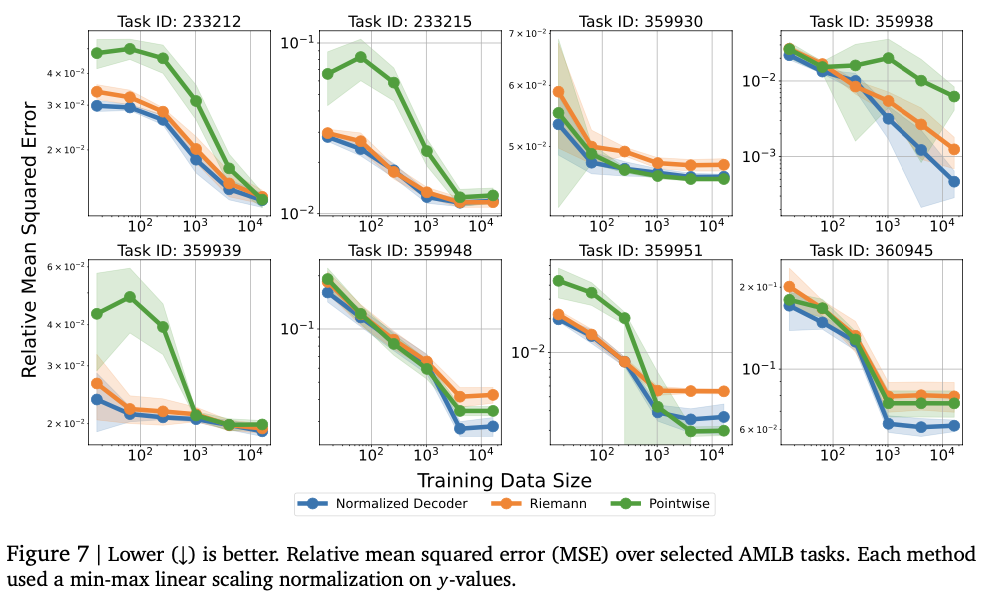
This work introduces the number of novels for the predetermined with funny independent and default. By replacing the native heads to postpone the headset based on Token, the framework improves the variability in the manufacturer of the actual permissible information. It achieves competitive performance in various returns of return, especially in difficulty measuring the tabar, while providing theory of the Syrian Suggestion. It issuates traditional ways to compromise significant conflicts, especially in the string of complex distribution and sparse data. Future work includes better stadiums for better accuracy and streams, expenses of exit and higher predictions, and investigates applications for learning and balances. These results use the restoration of numbers based on the Refland Regringsional other traditional methods, increase the number of functions in which language models can effectively be resolved.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 MarktechPost is shouting for companies / initializing / groups to cooperate with the coming magazines of AI the following 'Source Ai in production' and 'and' Agentic Ai '.
Aswin AK is a consultant in MarktechPost. He pursues his two titles in the Indian Institute of Technology, Kharagpur. You are interested in scientific scientific and machine reading, which brings a strong educational background and experiences to resolve the actual background development challenges.
✅ [Recommended] Join Our Telegraph Channel
 ngo-2026: I-WER, Izilimi, Ukubambezeleka, kanye Nelayisensi Kuqhathaniswa")


