This AI from Tsinghua University paper lifts T1 to measure the validity of learning by promoting assessment and understanding measuring measurement measuring measurement

Large Model Models (LLMS) They are designed specifically, program, and warm warm agents and need to improve in the consultation time. Various methods include expressing steps to consult with a prompt response or use of the Sample and Training models to produce the same step. Emphasisement is likely to provide assessment and learning skills; However, their impact on the complex thinking and keep the limit. Style Car In the test period it is still a problem because the increase in the efforts to integrate computational does not mean that translation into better models. Deep thinking and long answers can improve performance, but it is a challenge to achieve this effectively.
Current ways to improve the modeling model languages of imitation learning, where models repeat the factors that consult produces using samples or rejection. Making the data related to the consultation and proper planning with the help of the learning to improve understanding, but are not equal with complex thoughts. Training strategies such as boosting PERSTING-PEARY in pairs and adding tests Improve accuracy but rely on external dealings. Measuring Language Models by using more data and large models that improve performance, but to strengthen the stability based on learning and testing time period remaining unemployment. The repetition of a repetal sample increases computational costs without improving the ability to consult, making existing strategies for the deeper thought of the deepest answers and long responses.
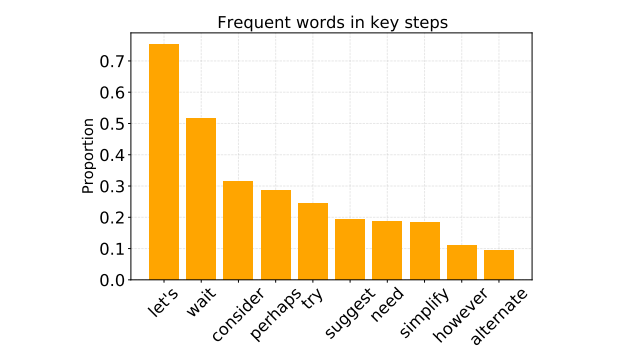
Dealing with these problems, Tsinghua University investigators including Zumsu ai proposed T1 the way. It promotes the validity of learning by increasing the amount of assessment and improving measurement measurement. T1 Starts by training a language model based on Chain-Eles and Self-confidence. This is usually refused during the existing way training. Therefore, the model finds the correct answers and understand the steps taken to get to them. Unlike previous methods that focus on the findings of the right solutions, T1 promotes various thinking methods by producing many responses to learning errors and analyzing errors before decisions. This framework improves the training of RLs in two ways: First, by overindulgence, which increases the diversity of responding, second, by controlling the final stability of the entropy based on entropy. Instead of maintaining a fixed reference model, T1 revives the capacity of the reference model using visual delivery ratings to make training not difficult. T1 is unnecessary, long-term, or low-level responses with negative reward, to keep the model followed to logical thinking.
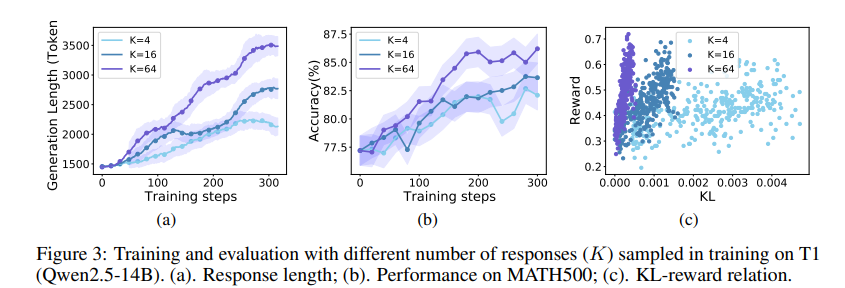
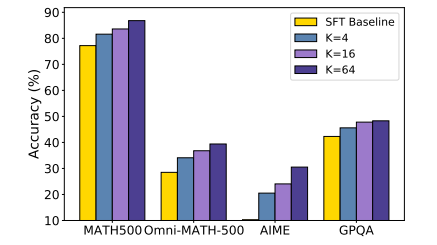
Investigators make up T1 using open models like GLM-4-9B including QWEN2.5-14B / 32Bfocusing on mathematical thinking by strengthening the verification (RL). They receive training data on train train and Nominamaths, which is a Grass 30,000 Conditions by issuing the answers and filing noisy data. This page To direct the beauty of directive (sft) Cosity Cooyy of Deliveration, and RL Training involved in the appearance of policy staff by rewards accurate. When he examines, T1 past its base models in Matt Benchmarks, with QWEN2.5-32B showing a 10-20% Development over the Soup the version. Increases the amount of sample reply (k) enhanced and normal and usual assessment, especially GPQA. Sample temperature levels 1.2 Stable training, while the highest or lower prices led to the issues. The penalties were used during the RL training to control the length of response and improve the consensus. The results showed significant performance benefits on measurement measuring, where the resources of the procedures have led better results.
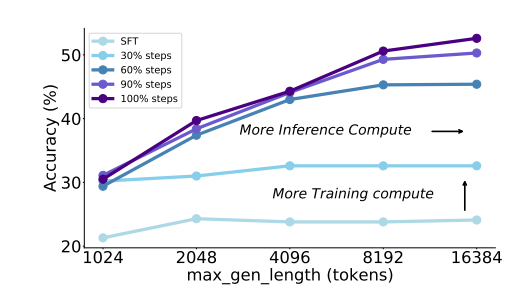
In conclusion, the proposed method T1 Developed large-language models by learning higher with assessment and stability. Penalties and excessive speculation can reduce the influence of the sectors with indicators. Indicate the strong functioning and promise moderate behavior. Coming to measuring measurement measurement measuring measurement indicates that further RL training developed the accuracy of the thinking and tendency to measure. T1 It passes the natural models of sensitive models on the challenging benches, overcoming weaknesses on current consultation rays. This work can be the first research area of further research, providing a framework for consulting and balancing major language models.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 Meet the Work: an open source opened with multiple sources to check the difficult program AI (Updated)
Divyesh is a contact in MarkteachPost. Pursuing BTech for agricultural and food engineers in the Indian Institute of Technology, Kharagpur. He is a scientific and typical scientific lover who wants to combine this leading technology in the agricultural background and resolve challenges.
✅ [Recommended] Join Our Telegraph Channel



