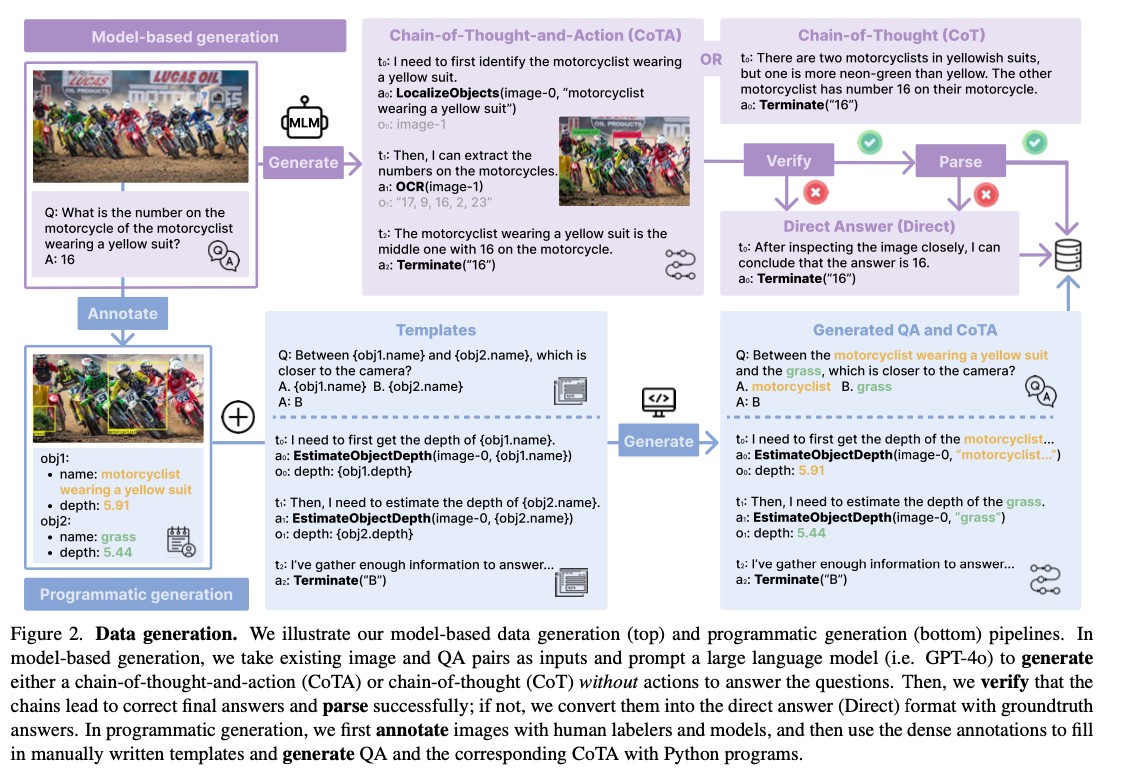
Salesforce AI Introduces TACO: A New Family of Multi-Action Models That Integrate Reasoning with Real-World Actions to Solve Complex Virtual Tasks

Developing multi-dimensional AI systems for real-world applications requires managing a variety of tasks such as fine-grained recognition, visual localization, reasoning, and multi-step problem solving. Existing multilingual open source models are found to be lacking in these areas, especially for tasks involving external tools such as OCR or mathematical calculations. The aforementioned limitations can be attributed mainly to single-step datasets that cannot provide a coherent framework for multi-step reasoning and logical action chains. Overcoming this will be critical to unlocking the true power of using multi-dimensional AI at complex levels.
Current multivariate models often rely on instructional programming with data sets that have specific responses or few feedback mechanisms. Proprietary systems, such as GPT-4, have demonstrated the ability to think about CoTA chains successfully. At the same time, open source models face the challenges of lack of data sets and integration with tools. Previous efforts, such as LLaVa-Plus and Visual Program Distillation, were also limited by small dataset sizes, low-quality training data, and a focus on simple question-answering tasks, limiting the complex multi-modal problems they require. complex thinking and tool use.
Researchers from the University of Washington and Salesforce Research have developed TACO, a new framework for training multipath action models using CoTA performance data sets. This work presents several important improvements to address the limitations of previous methods. First, more than 1.8 million traces were generated using GPT-4 and programming in Python, while a subset of 293K examples were selected to present high quality after rigorous filtering techniques. These examples ensure the inclusion of diverse thinking and action sequences that are important in multimodal learning. Second, TACO includes a robust set of 15 tools, including OCR, object localization, and math solvers, enabling modelers to handle complex tasks effectively. Third, advanced filtering and data integration techniques improve the data set, emphasizing the integration of thought-action and promoting higher learning outcomes. This framework redefines multimodal learning by allowing models to generate coherent multistep reasoning while seamlessly integrating actions, thereby establishing a new benchmark for performance in complex situations.
Development of TACO involves training on a carefully selected CoTA dataset with 293K instances taken from 31 different sources, including the Visual Genome. These data sets contain a wide range of tasks such as mathematical reasoning, visual character recognition, and detailed visual understanding. It is very diverse, with tools provided including object localization and language-based solvers that allow for a wide variety of thought and action tasks. The training structure combined LLaMA3 as the language base with CLIP as the visual input thus creating a strong multi-modal framework. Fine-tuning is established by hyperparameter tuning that focuses on reducing learning rates and increasing the number of training periods to ensure that models can solve complex multi-pathway challenges.
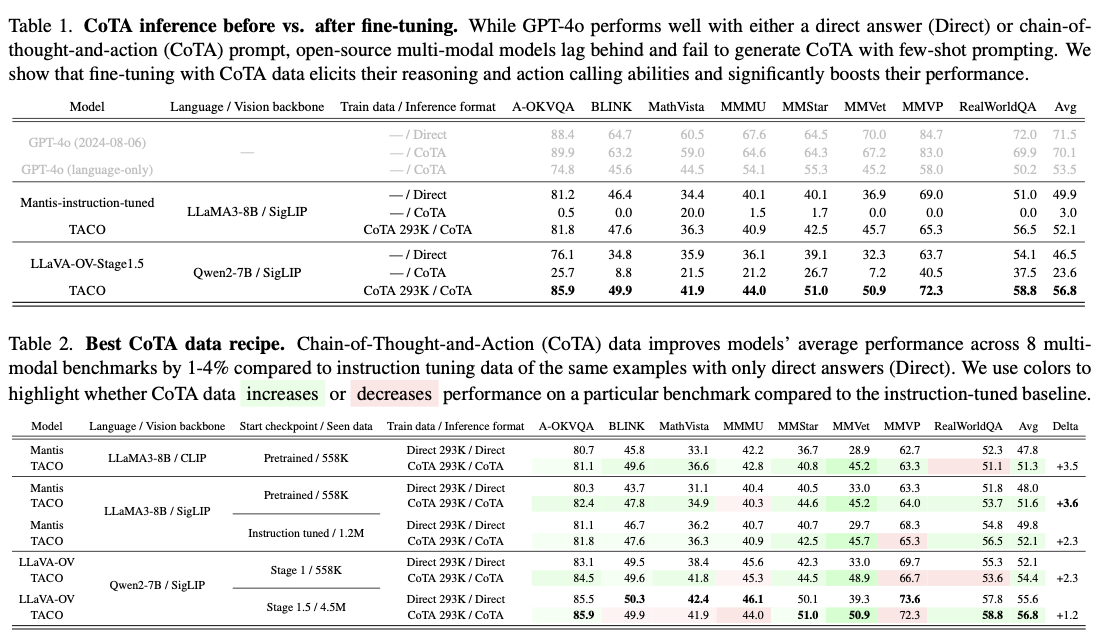
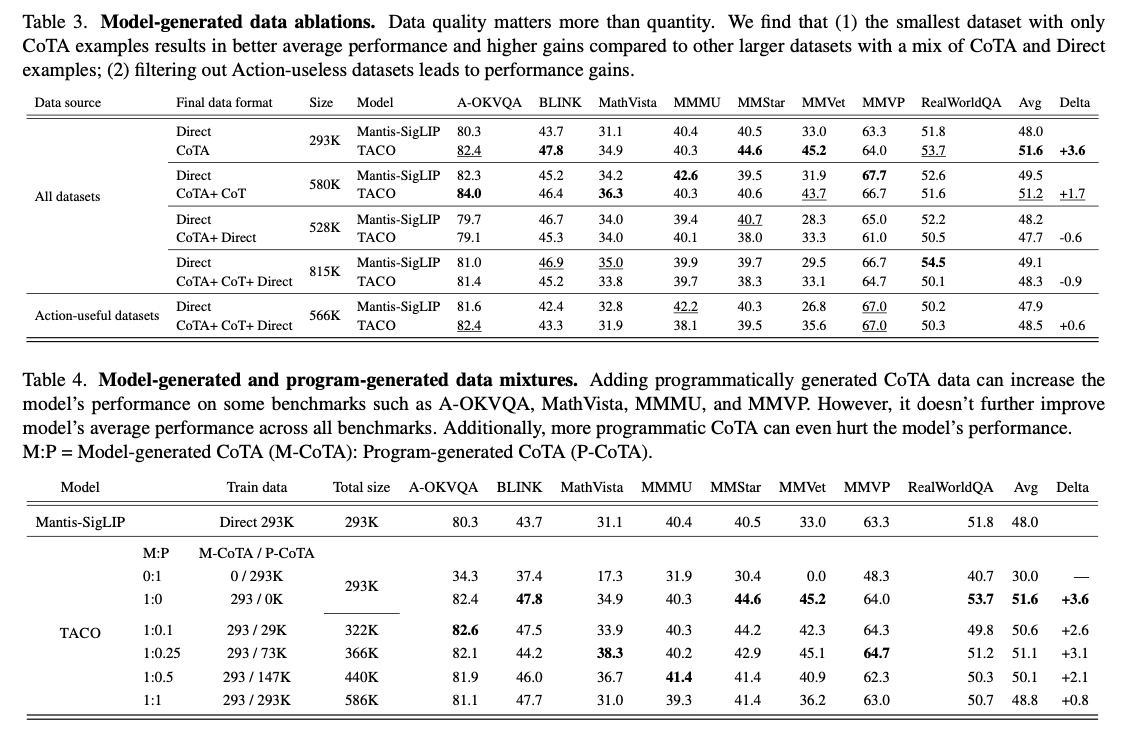
TACO's performance on all eight benchmarks demonstrates its significant impact on developing multimodal thinking skills. The system achieved an average accuracy improvement of 3.6% over instruction-activated baselines, with gains of up to 15% on MMVet tasks involving OCR and mathematical reasoning. Notably, the high-quality 293K CoTA dataset performed significantly better than the larger, less refined datasets, underscoring the importance of targeted data collection. Some performance improvements are achieved through optimization of hyperparameter techniques, including optimization of vision encoders and optimization of learning rates. Table 2: The results show the best performance of TACO compared to the benchmarks, the latter being found to be the best in complex tasks involving the integration of thinking and acting.

TACO presents a new approach to multi-action modeling that effectively addresses the major shortcomings of both reasoning and tool-based actions by using high-quality synthetic data sets and new training methods. The research overcomes the limitations of traditional instruction-activated models, and its development is poised to change the face of real-world applications from visual question-answering to complex multi-step reasoning tasks.
Check it out Paper, GitHub page, and Project Page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.
Aswin AK is a consultant at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, which brings a strong academic background and practical experience in solving real-life domain challenges.
✅ [Recommended Read] Nebius AI Studio expands with vision models, new language models, embedded and LoRA (Enhanced)



