RAG-Check: A Novel AI Framework for Hallucination Detection in Multi-Modal Retrieval-Augmented Generation Systems

Large-scale Language Models (LLMs) have revolutionized generative AI, showing remarkable capabilities in generating human-like responses. However, these models face an important challenge known as hallucination, the tendency to produce incorrect or irrelevant information. This problem poses a significant risk to high-end applications such as medical evaluation, insurance claim processing, and automated decision-making systems where accuracy is critical. The problem of visual hallucinations goes beyond text-based models to visual language models (VLMs) that process images and text queries. Despite developing robust VLMs such as LLaVA, InstructBLIP, and VILA, these programs struggle to generate accurate responses based on image input and user queries.
In the present study we have presented several methods to deal with the missing objects in language models. For text-based systems, FactScore has improved accuracy by breaking long statements into atomic units for better verification. Lockback Lens developed a method of analyzing attention points to detect contextual manipulation, while MARS used a weighted system that focused on key parts of the statement. In RAG programs specifically, RAGAS and LlamaIndex have emerged as assessment tools, RAGAS focuses on response accuracy and consistency using human raters, while LlamaIndex uses the GPT-4 to assess reliability. However, there are no existing works that provide visualization points directly for multimodal RAG systems, where the content includes multiple pieces of multimodal data.
Researchers from the University of Maryland, College Park, MD, and NEC Laboratories America, Princeton, NJ have proposed RAG-check, a comprehensive method for testing RAG systems with multiple conditions. It consists of three main components designed to assess both consistency and accuracy. The first part involves a neural network that evaluates the relevance of each returned piece of data to the user's query. The second part uses a segmentation algorithm and separates the RAG output into blanks (object) and blanks (subject). The third part uses another neural network to test the accuracy of the target range against raw content, which can include both text and images converted to a text-based format by VLMs.
The RAG check architecture uses two main evaluation metrics: the Suitability Score (RS) and the Suitability Score (CS) to evaluate different aspects of the RAG system's performance. To test the selection methods, the system analyzes the relevance scores of the top 5 images retrieved from a test set of 1,000 queries, providing insights into the performance of different retrieval methods. In terms of context generation, the architecture allows flexible integration of combinations of different models either separate VLMs (such as LLaVA or GPT4) and LLMs (such as LLAMA or GPT-3.5), or combined MLLMs such as -GPT-4. This flexibility allows for a comprehensive assessment of the properties of different models and their impact on the quality of the response.
Test results show significant performance differences across RAG system types. When using CLIP models as perception encoders with cosine similarity in image selection, the average score ranges from 30% to 41%. However, using the RS model to evaluate the image pair significantly improves the compatibility score to between 71% and 89.5%, although at the cost of a 35-fold increase in computing requirements when using the A100 GPU. GPT-4o emerges as the highest configuration for content production and error rates, outperforming other setups by 20%. The remaining RAG configurations show similar performance, with an accuracy rate between 60% and 68%.
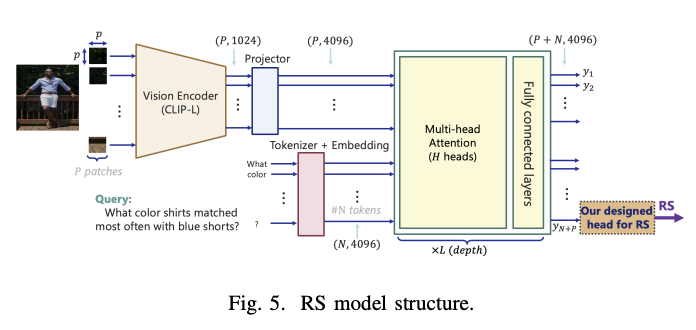
In conclusion, the researchers RAG-check, a novel evaluation framework for many RAG systems to address the important challenge of detection of anomalies in multiple images and textual input. The three-part structure of the framework, including relevance scores, time segmentation, and accuracy testing shows a significant improvement in performance evaluation. The results reveal that although the RS model significantly improves the relative scores from 41% to 89.5%, it comes with an increased computational cost. Among the various configurations tested, GPT-4o emerged as the most efficient context generation model, highlighting the power of integrated multi-language models in improving the accuracy and reliability of the RAG system.
Check out Paper. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.

Sajjad Ansari is a final year graduate of IIT Kharagpur. As a Tech Enthusiast, he examines the applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to convey complex AI concepts in a clear and accessible manner.
✅ [Recommended Read] Nebius AI Studio expands with vision models, new language models, embedded and LoRA (Enhanced)

: A Three-Class Model Family with a Tool for Calling the Response API")
