
As organizations plan their defenses for the immediate future, 51% of businesses rank cybersecurity attacks and breaches as the top risk to their performance in 2026.
At the same time, the ratio of cybersecurity spending to financial losses is staggering; while global spending was $185 billion in 2024 against $9.22 trillion in losses, this gap is projected to increase to 68 times by 2030, with $262 billion in spending versus $18 trillion in losses.
This stark financial reality shows that traditional defense mechanisms are no longer sufficient. In this blog, we will focus on AI for Cybersecurity, defensive strategies, risk management, and workforce adaptation that must structurally change to address the evolution of automated and intelligent threats.
Summarize this article with ChatGPT
Get key takeaways & ask questions
The Emerging Dynamics of AI-Driven Threats
The traditional model of cybersecurity relied on identifying known patterns of malicious code, but the introduction of machine learning has allowed attackers to move beyond these predictable methods.
Modern threats are now characterized by their ability to learn from the environments they infect, making them harder to track and neutralize using standard software.
Attackers are using artificial intelligence in cybersecurity not just to move faster, but to create highly personalized campaigns that exploit human psychology and system vulnerabilities simultaneously.
The evolution of these tactics is defined by several critical developments in how malicious actors utilize automated intelligence:
- Autonomous and Self-Evolving Malware: Malicious software no longer requires constant instructions from a central server to execute its mission. Instead, it can enter a network and independently analyze the environment to find the most valuable data or the weakest security points, often changing its own code to avoid being detected by antivirus scanners.
- Hyper-Personalized Social Engineering: By processing vast amounts of public data, attackers can generate phishing emails or messages that perfectly mimic the tone and style of a trusted colleague or executive. This removes the common warning signs of fraud, such as poor grammar or generic greetings, making these attacks highly successful.
- Adversarial Manipulation of Defense Systems: Because many security tools now use artificial intelligence to detect threats, attackers have begun targeting the logic of these tools. By introducing “poisoned” data into a system’s learning process, they can trick the security software into ignoring specific types of malicious activity.
- Large-Scale Vulnerability Discovery: Automated tools can scan millions of lines of code in seconds to find “zero-day” vulnerabilities that have not yet been discovered by software developers. This allows attackers to exploit weaknesses in common applications before a patch can be created or deployed.
These advancements mean that the window of time available to respond to an attack has shrunk from days to seconds.
When threats can think and adapt on their own, a manual response from a human security team is often too slow to prevent data theft or system lockdowns.
Organizations must therefore recognize that they are no longer just fighting human hackers, but highly efficient, automated software agents.
Strengthening the Core Security Structures for Better Protection
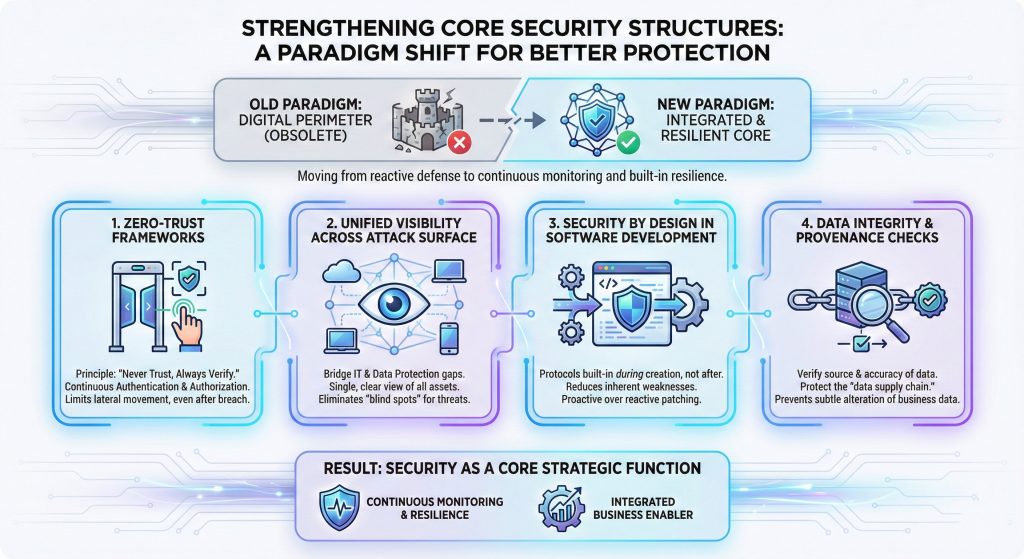
Protecting an organization in this environment requires more than just buying new software; it requires a complete change in how a network is built and managed.
The old idea of a “digital perimeter” where everyone inside a building is trusted, and everyone outside is blocked, is no longer relevant in a world of remote work and cloud computing.
Security must now be integrated into every single device, application, and user interaction within the business ecosystem.
To address these vulnerabilities, organizations are moving toward a more integrated and disciplined structural model:
- Implementation of Zero-Trust Frameworks: This strategy operates on the principle of “never trust, always verify.” Every user and device must be continuously authenticated and authorized to access specific data, ensuring that even if an attacker gains entry, they cannot move freely across the entire network.
- Unified Visibility Across the Attack Surface: Security teams must bridge the gap between IT operations and data protection to gain a single, clear view of all connected assets. This includes identifying every laptop, cloud server, and mobile device to ensure that no “blind spots” exist where an automated threat could hide.
- Security by Design in Software Development: Rather than checking for security flaws after a product is finished, security protocols are now built into the very beginning of the software creation process. This reduces the number of inherent weaknesses that can be exploited later by intelligent scanning tools.
- Data Integrity and Provenance Checks: Organizations must implement strict controls to verify the source and accuracy of the data they use to train their own internal systems. Protecting the “data supply chain” ensures that the information used for business decisions has not been subtly altered by an outside party.
By adopting these structural changes, businesses move from reactive defense to continuous monitoring and built-in resilience, making security a core strategic function rather than a separate department.
This shift is also creating strong talent demand, with government projections estimating nearly 140,100 job openings annually for software and security testing professionals through 2033, highlighting how critical advanced security expertise has become to sustained digital growth.
For those looking to confidently lead in this evolving digital environment, the Certificate Program in Generative AI & Agents Fundamentals from Johns Hopkins University provides a highly relevant, 8-week online learning path.
This program requires no programming experience and equips technical leaders and business professionals with a reliable foundation in AI, including crucial modules on responsible AI practices and security.
How does this program empower your career?
This executive education program is specifically designed to help professionals leverage artificial intelligence in cybersecurity while understanding the critical guardrails required for secure business deployment. Here is how it directly benefits you:
- Tackle AI Security Risks Head-On: The curriculum dedicates specific focus to Responsible AI, teaching you how to identify major Large Language Model (LLM) security risks such as prompt injection, data poisoning, and jailbreaking.
- Apply Security Frameworks to AI: You will learn how to actively apply the CIA Triad (Confidentiality, Integrity, Availability) to assess and mitigate security risks within LLM deployments.
- Understand Supply Chain Vulnerabilities: Aligning perfectly with the need for data provenance, the program explains how supply chain vulnerabilities and service denial can compromise AI reliability and accountability.
- Build Practical AI Skills Without Coding: You will learn to design agentic workflows, understand Prompt Engineering, and apply AI agents to business operations, all without needing any prior programming knowledge.
In an era where cybersecurity and AI are becoming deeply interconnected, programs like this enable professionals to not only understand emerging technologies but also deploy them responsibly and securely.
As attacks become smarter, defensive tools must also gain the ability to reason and act without waiting for human intervention.
The goal of a modern defense system is to achieve “predictive security,” where the software can anticipate an attacker’s next move based on subtle changes in network behavior.
This requires a transition from reactive tools that fire alerts after an incident to proactive systems that actively hunt for threats. The effectiveness of these proactive strategies relies on several key technical capabilities:
- Behavioral Anomaly Detection: Instead of looking for a specific virus, these systems learn what “normal” looks like for every employee and server. If a quiet accountant suddenly starts downloading thousands of encrypted files at midnight, the system recognizes this as an anomaly and immediately restricts their access.
- Automated Incident Triage and Response: Advanced security platforms can now handle the first stages of an attack automatically. They can isolate infected computers, block suspicious web traffic, and reset compromised passwords in real-time, allowing human analysts to focus on investigating the root cause.
- Continuous Threat Hunting: Specialized software agents constantly crawl through an organization’s internal logs and external threat databases to find signs of hidden intruders. This active searching helps find “low and slow” attacks that try to stay under the radar for months.
- Intelligent Content Filtering: Communication tools now use context-aware analysis to stop deepfake audio or video and phishing attempts before they reach an employee’s inbox, effectively neutralizing the attacker’s most potent tool.
Using these advanced methodologies allows a security team to manage a much higher volume of threats than was previously possible.
To effectively implement these advanced, automated defense mechanisms, from behavioral anomaly detection to continuous threat hunting, security professionals need specialized, up-to-date training.
Building the capability to transition an organization from a reactive posture to a predictive security model requires hands-on experience with modern tools and defensive frameworks.
For those ready to master these proactive methodologies and stay ahead of automated threats, exploring industry-aligned Cyber Security Courses provides the essential practical skills and strategic knowledge required to confidently fortify any digital infrastructure.
The Role of Agentic Systems in Security Operations
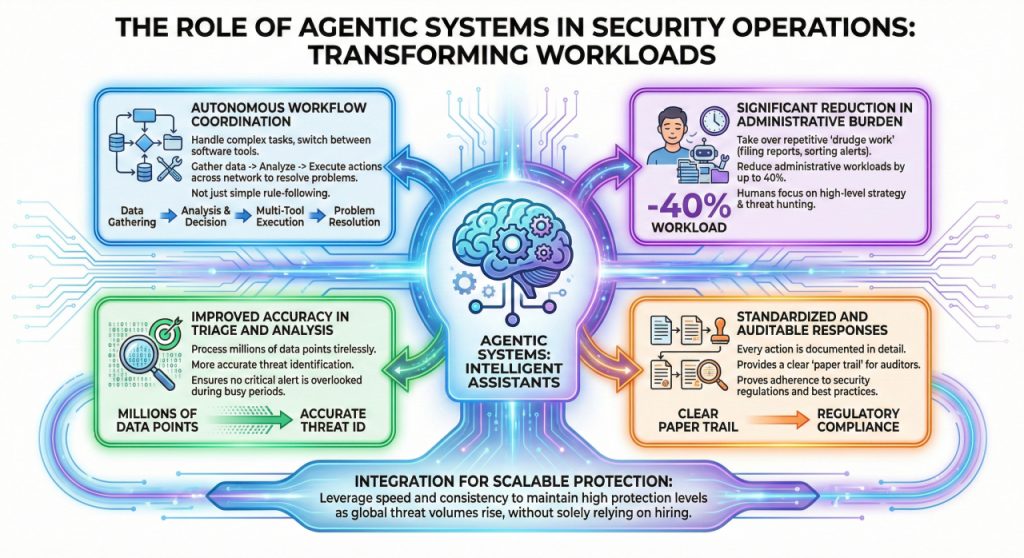
A significant breakthrough in managing security workloads is the use of “agent” systems that can think through a problem and execute multiple steps to solve it. These tools are transforming the day-to-day operations of security departments by acting as intelligent assistants:
- Autonomous Workflow Coordination: Unlike simple automation that follows one rule, agentic systems can handle complex tasks that require switching between different software tools. They can gather data, analyze it, and then execute a series of actions across the network to resolve a problem.
- Significant Reduction in Administrative Burden: By taking over the repetitive “drudge work” of security, such as filing reports and sorting through low-level alerts, these systems can reduce administrative workloads by up to 40%. This allows human teams to spend their time on high-level strategy and threat hunting.
- Improved Accuracy in Triage and Analysis: Automated agents can process millions of data points without getting tired or distracted. This leads to more accurate identification of threats and ensures that no critical alert is overlooked during a busy period.
- Standardized and Auditable Responses: When an agent handles a security task, every action they take is documented in detail. This provides a clear “paper trail” for auditors and helps the organization prove it is following all necessary security regulations and best practices.
The integration of these systems allows security departments to scale their efforts without necessarily hiring hundreds of new staff members.
By leveraging the speed and consistency of agentic systems, organizations can maintain a high level of protection even as the volume of global threats continues to rise.
Ensuring Compliance Through Effective Risk and Governance Practices
Managing risk in an AI for Cybersecurity requires new rules and clear accountability. Governance must bridge the gap between technical capabilities and ethical responsibilities to ensure that security tools are used effectively and safely:
- Adherence to Standardized Risk Frameworks: Organizations should align their operations with globally recognized standards, such as the NIST AI Risk Management Framework. These guidelines provide a structured way to identify, measure, and manage the specific risks associated with using intelligent systems in a corporate environment.
- Establishment of Ethical Use Policies: Companies must create clear rules for how automated tools are used, particularly regarding employee privacy and data usage. This prevents “shadow AI,” where employees use unauthorized tools that might accidentally leak sensitive company information into public databases.
- Rigorous Third-Party and Supply Chain Audits: As businesses rely more on outside vendors for software and data services, they must verify that these partners maintain high security standards. A vulnerability in a single supplier can provide a “backdoor” into dozens of other companies, making supply chain security a top priority.
- Emphasis on Human-in-the-Loop Oversight: While automation provides speed, human judgment remains essential for complex decision-making and ethical considerations. Governance models must define exactly when a human must intervene, especially in high-stakes situations like shutting down critical business systems during a suspected attack.
Strong governance ensures that, as an organization adopts more powerful technology, it does so with a full understanding of the potential consequences.
This creates a balance where the benefits of automation are maximized while the legal and operational risks are kept under strict control.
However, establishing these robust frameworks and maintaining a strong organizational security posture requires specialized technical expertise.
With an IBM study revealing that 95% of cybersecurity breaches result from human error, cultivating a highly trained workforce is the most critical defense an organization can deploy.
To meet the surging demand for talent, professionals must systematically upgrade their skill set,s and that is where programs like The Post Graduate Program in Cybersecurity, presented by the McCombs School of Business at The University of Texas at Austin in collaboration with Great Learning, are known to be a one-stop solution.
Designed by leading faculty, this curriculum gives you the tools to investigate attacks, build robust cybersecurity systems, and gain a competitive edge in the job market. Here is how the program directly translates to career growth:
- Master Governance, Risk, and Compliance (GRC): You will gain a deep understanding of vital standards and frameworks to build a strong organizational security posture. The curriculum develops your technical expertise in navigating data protection laws like GDPR and DPDP, applying ISO 27001:2022, and managing third-party supply chain risks.
- Understand and Combat Modern Cyber Attacks: You will learn to view threats from an adversary’s lens, utilizing frameworks like MITRE ATT&CK and the Cyber Kill Chain. This prepares you to recognize and defend against threats such as Advanced Persistent Threats (APTs) and Ransomware.
- Design and Implement Security Controls: You will discover effective methods for applying security strategies, diving deeply into Endpoint Detection and Response (EDR), Identity and Access Management (IDAM), Data Loss Prevention (DLP), and continuous monitoring using SIEM.
- Gain Practical, Hands-On Experience: The program goes beyond theory by offering extensive lab sessions. You will practice capturing network traffic with Wireshark, configuring Next Generation Firewalls (NGFW), executing web application penetration tests, and securing data on Microsoft Azure.
By building expertise across GRC, threat intelligence, security architecture, and hands-on defense practices, this program equips you to reduce organizational risk, strengthen resilience, and position yourself as a trusted cybersecurity leader in an increasingly high-stakes digital risks.
Conclusion
Adapting cybersecurity thinking for the age of AI requires a move away from the “protect and react” mindset of the past. It is no longer enough to wait for an attack to happen and then try to fix it; instead, security must be an active, intelligent, and foundational part of every business process.
This transformation involves deploying autonomous defenses that can match the speed of attackers, restructuring networks to remove unearned trust, and building a workforce that is deeply skilled in the nuances of modern technology.
By focusing on resilience, governance, and continuous adaptation, organizations can navigate this new era with confidence, ensuring they stay ahead of the curve in a rapidly changing threat environment.



