
Photo by the Author
# Introduction
Web crawling is the process of automatically visiting web pages, following links, and collecting website content in a systematic way. It is often used to gather large amounts of information from document sites, articles, knowledge bases, and other web resources.
Crawling an entire website and converting that content into a format that an AI agent can use is actually not as easy as it sounds. Document sites often contain nested pages, repetitive navigation links, boilerplate content, and static page layouts. In addition, extracted content needs to be cleaned, organized, and saved in a way that is useful for downstream AI workflows such as retrieval, query answering, or agent-based systems.
In this guide, we will learn why you should use it Olostep instead of Scratching or Seleniumset up everything needed for a web crawling project, write a simple script to rip a script website, and finally create a frontend using Gradio so that anyone can provide a link and other arguments to specify the pages of the website.
# Choosing Olostep Over Scrapy or Selenium
Scrapy is powerful, but it's built like a full-frame scraper. That's useful if you want deep control, but it also means more setup and more engineering work.
Selenium is best known for browser automation. It's useful for interacting with JavaScript-heavy pages, but it's not designed as a workflow for crawling the documents themselves.
With Olostep, the pitch is very straightforward: search, crawl, scrape, and structure web data through a single application programming interface (API), with support for LLM-compliant outputs such as Markdowntext, HTML, and structured JSON. That means you don't need to assemble the pieces manually to find, extract, format, and use the underlying AI in the same way.
With article sites, that can give you a much faster path from URL to actionable content because you spend less time building a clear stack and more time working on the content you actually need.
# Installing packages and setting an API key
First, install the file Python packages used in this project. The official Olostep software development kit (SDK) requires Python 3.11 or later.
pip install olostep python-dotenv tqdmThese packages handle the main components of the workflow:
olostepconnects your script to the Olostep APIpython-dotenvuploads your API key to an .env filetqdmadds a progress bar so you can track saved pages
Next, create a free Olostep account, open the dashboard, and generate an API key from the API keys page. Olostep's official documentation and integration point users to a dashboard to set up an API key.
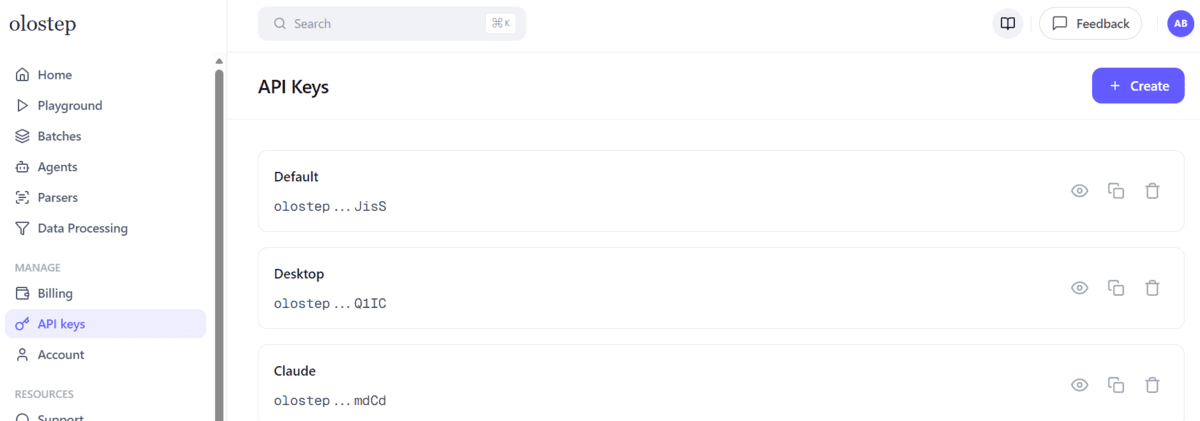
Then create an .env file in your project folder:
OLOSTEP_API_KEY=your_real_api_key_hereThis keeps your API key separate from your Python code, which is a clean and safe way to manage data.
# Creating a Crawler Script
In this part of the project, we will create a Python script that crawls a directory website, extract each page in Markdown format, clean up the content, and save them locally as individual files. We'll create a project folder, add a Python file, and write the code step by step to make it easy to follow and test.
First, create a project folder for your browser. Inside that folder, create a new Python file named crawl_docs_with_olostep.py.
Now we will add code to this file one section at a time. This makes it easy to understand what each part of the script does and how the full browser works together.
// Defining Crawl Settings
Start by importing the required libraries. Then define the main layout settings, such as the starting URL, the layout depth, the page limit, insert and remove rules, and the output folder where the Markdown files will be saved. These values control how much of the document site is displayed and where the results are stored.
import os
import re
from pathlib import Path
from urllib.parse import urlparse
from dotenv import load_dotenv
from tqdm import tqdm
from olostep import Olostep
START_URL = "
MAX_PAGES = 10
MAX_DEPTH = 1
INCLUDE_URLS = [
"/**"
]
EXCLUDE_URLS = []
OUTPUT_DIR = Path("olostep_docs_output")// Creating a Safe Filename Generation Assistant Function
Each transparent page needs to be saved as its own Markdown file. To do that, we need a helper function that converts the URL into a clean and secure file name on the system. This avoids problems with slashes, symbols, and other characters that don't work well in file names.
def slugify_url(url: str) -> str:
parsed = urlparse(url)
path = parsed.path.strip("
if not path:
path = "index"
filename = re.sub(r"[^a-zA-Z0-9/_-]+", "-", path)
filename = filename.replace(" "__").strip("-_")
return f"{filename or 'page'}.md"// Creating a Helper Function for Saving Markdown Files
Next, add helper functions to process the extracted content before saving it.
The first function cleans up Markdown by removing extra user interface text, repeated empty lines, and unwanted page elements like response instructions. This helps to keep the saved files focused on the original content of the documents.
def clean_markdown(markdown: str) -> str:
text = markdown.replace("rn", "n").strip()
text = re.sub(r"[s*u200b?s*](#.*?)", "", text, flags=re.DOTALL)
lines = [line.rstrip() for line in text.splitlines()]
start_index = 0
for index in range(len(lines) - 1):
title = lines[index].strip()
underline = lines[index + 1].strip()
if title and underline and set(underline) == {"="}:
start_index = index
break
else:
for index, line in enumerate(lines):
if line.lstrip().startswith("# "):
start_index = index
break
lines = lines[start_index:]
for index, line in enumerate(lines):
if line.strip() == "Was this page helpful?":
lines = lines[:index]
break
cleaned_lines: list[str] = []
for line in lines:
stripped = line.strip()
if stripped in {"Copy page", "YesNo", "⌘I"}:
continue
if not stripped and cleaned_lines and not cleaned_lines[-1]:
continue
cleaned_lines.append(line)
return "n".join(cleaned_lines).strip()The second function saves the cleaned Markdown to the output folder and adds the source URL to the top of the file. There is also a small utility to delete old Markdown files before saving the new markdown result.
def save_markdown(output_dir: Path, url: str, markdown: str) -> None:
output_dir.mkdir(parents=True, exist_ok=True)
filepath = output_dir / slugify_url(url)
content = f"""---
source_url: {url}
---
{markdown}
"""
filepath.write_text(content, encoding="utf-8")There is also a small utility to delete old Markdown files before saving the new markdown result.
def clear_output_dir(output_dir: Path) -> None:
if not output_dir.exists():
return
for filepath in output_dir.glob("*.md"):
filepath.unlink()// Creating Main Crawler Logic
This is the main part of the text. It loads the API key into an .env file, creates an Olostep client, starts the crawl, waits for it to finish, finds each crawled page as Markdown, cleans the content, and saves it locally.
This section brings everything together and transforms the functions of each assistant into a working document searcher.
def main() -> None:
load_dotenv()
api_key = os.getenv("OLOSTEP_API_KEY")
if not api_key:
raise RuntimeError("Missing OLOSTEP_API_KEY in your .env file.")
client = Olostep(api_key=api_key)
crawl = client.crawls.create(
start_url=START_URL,
max_pages=MAX_PAGES,
max_depth=MAX_DEPTH,
include_urls=INCLUDE_URLS,
exclude_urls=EXCLUDE_URLS,
include_external=False,
include_subdomain=False,
follow_robots_txt=True,
)
print(f"Started crawl: {crawl.id}")
crawl.wait_till_done(check_every_n_secs=5)
pages = list(crawl.pages())
clear_output_dir(OUTPUT_DIR)
for page in tqdm(pages, desc="Saving pages"):
try:
content = page.retrieve(["markdown"])
markdown = getattr(content, "markdown_content", None)
if markdown:
save_markdown(OUTPUT_DIR, page.url, clean_markdown(markdown))
except Exception as exc:
print(f"Failed to retrieve {page.url}: {exc}")
print(f"Done. Files saved in: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
main()Note: The full text is available here: kingabzpro/web-crawl-olostepthe first web browser and web application built with Olostep.
// Testing Web Crawling Script
Once the script is finished, run it in your terminal:
python crawl_docs_with_olostep.pyAs the script runs, you'll see the browser process the pages and save them one by one as Markdown files in your output folder.

After you finish scanning, open the saved files to check the extracted content. You should see clean, readable Markdown versions of the documentation pages.
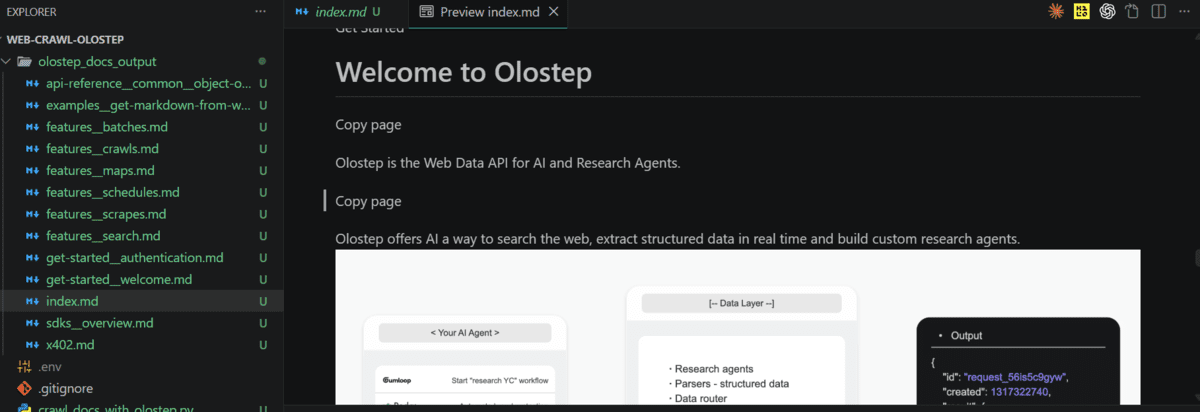
At that point, your document content is ready for use in AI workflows such as search, retrieval, or agent-based systems.
# Creating an Olostep Web Crawling Web Application
In this part of the project, we will build a simple web application on top of a browser script. Instead of editing a Python file every time, this application gives you an easy way to enter the URL of the document, choose the resolution settings, start the resolution, and preview the saved Markdown files in one place.
The front-end code for this application is available at app.py in the last place: web-crawl-olostep/app.py.
This app does several useful things:
- Allows you to enter the first crawl URL
- It allows you to set the maximum number of pages to crawl
- It allows you to control the depth of field
- Allows you to add and exclude URL patterns
- It uses background scanner directly from the interface
- Saves clear pages to a folder based on URL
- Shows all Markdown files saved in the dropdown
- It previews each Markdown file directly within the application
- It allows you to clear previous transparency results with one button
To start the application, use:
After that, Gradio will start the local web server and provide a link like this:
* Running on local URL:
* To create a public link, set `share=True` in `launch()`.Once the program is running, open the site URL in your browser. In our example, we have given request i Claude Code documentation URL and asked it to crawl 50 pages 5 deep.
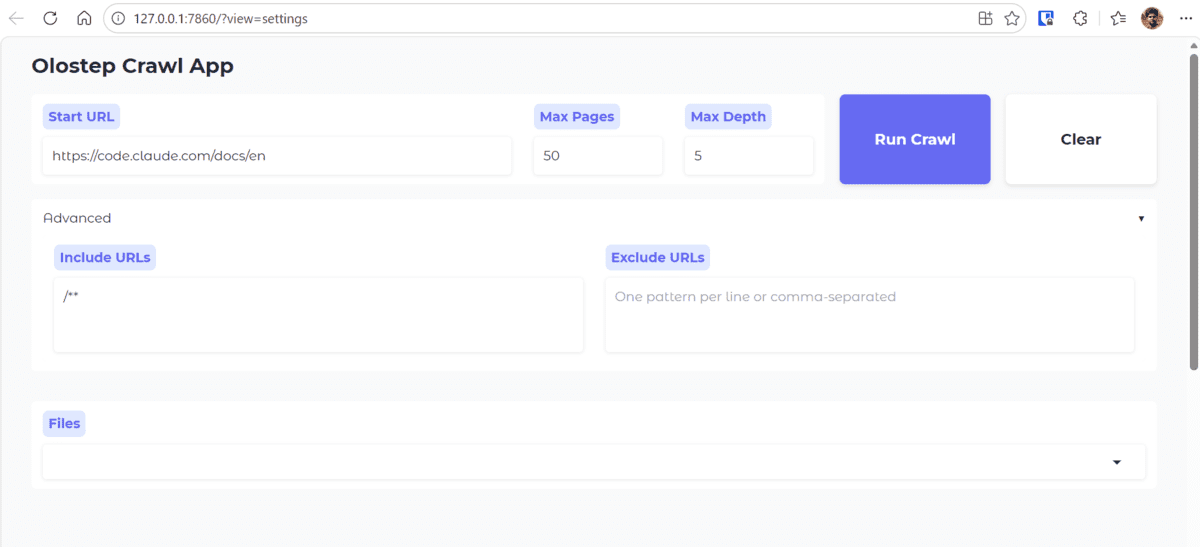
When you click Run Crawlthe app transfers your settings to the background browser and starts scanning. In the terminal, you can watch the progress as the pages are scanned and saved one by one.

After finishing parsing, the output folder will contain the saved Markdown files. In this example, you will see that 50 files have been added.
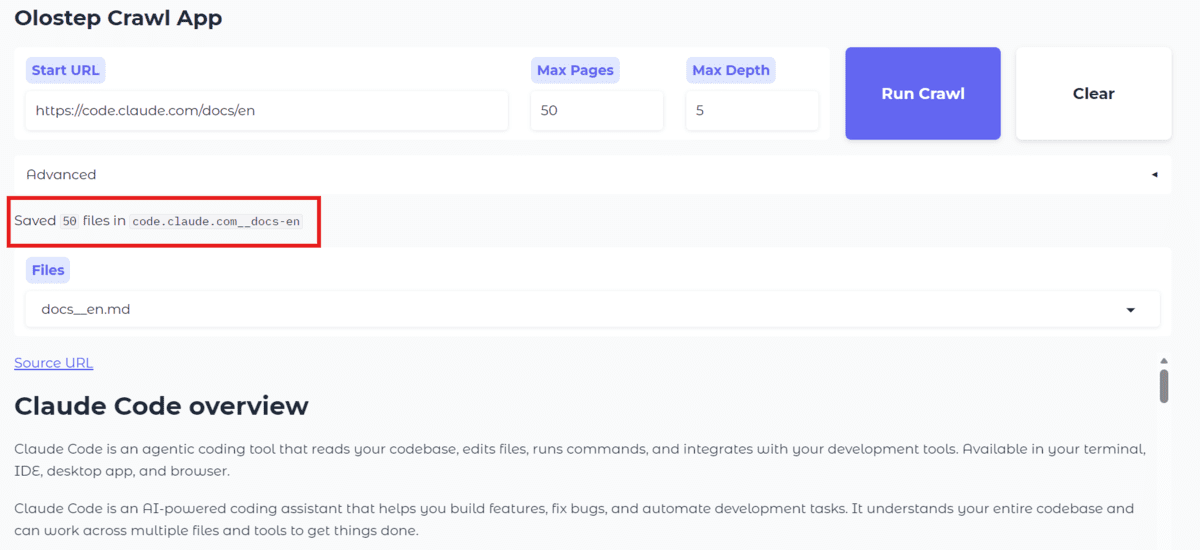
The app's downloads are updated automatically, so you can open any saved file and preview it directly in the web interface as well-formatted Markdown.
This makes the browser very easy to use. Instead of changing the code values every time, you can check different documentation sites and crawl the settings using a simple interface. That also makes the project easier to share with other people who may not want to work directly in Python.
# The final takeaway
Web crawling is not just about collecting pages on a website. The real challenge is turning that content into clean, structured files that can actually be used by an AI program. For this project, we used a simple Python script and Gradio app to make that process much easier.
Most importantly, the workflow is fast enough to actually use. In our example, a 50-page, 5-depth crawl took only about 50 seconds, which shows that you can quickly process document data without building a heavy pipeline.
This setting can go beyond one-time transparency. You can schedule it to run daily with a cron or Task Scheduler, and update only the pages that have changed. That keeps your documents fresh while using only a small number of credits.
For teams that need this kind of workflow to make business sense, Olostep was built with that in mind. It is more affordable than building or maintaining an in-house crawling solution, and is at least 50% cheaper than other comparable solutions on the market.
As your usage grows, the cost per request continues to decrease, making it a viable choice for large document pipelines. That combination of reliability, scalability, and a strong economic unit is why some of the fastest-growing AI-natives rely on Olostep to power their data infrastructure.
Abid Ali Awan (@1abidiawan) is a data science expert with a passion for building machine learning models. Currently, he specializes in content creation and technical blogging on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His idea is to create an AI product using a graph neural network for students with mental illness.



")