Cohere Releases Command A+: 218B Sparse MoE Model for Agentic Workflow Running on Two H100 GPUs

Cohere recently released Command A+, as an open source model that streamlines enterprise agent workflows. Available under the Apache 2.0 license, Command A+ is a mixed-expert (MoE) model designed for high-performance agent tasks with minimal compute overhead. The model is designed for logic, agent workflow, RAG, multi-language, and heterogeneous document processing. It combines capabilities from four previous models – Command A, Command A Consult, Command A Vision, and Command A Translate – into one scalable model.
Buildings
Command A+ is a decoder-only Sparse Mixture-of-Experts Transformer with 218B total parameters and 25B active parameters. It has 128 experts, of which 8 are active per token, and one shared expert is used for all tokens. In the MoE model, each token is submitted to only a small set of expert sub-networks rather than the full parameter set, which keeps the computation efficient at the 25B parameter scale during decision-making.
Attention layers include sliding window attention layers with Rotating Area Embedding and global attention layers without vertical embedding at a ratio of 3:1. The MoE thin layer is trained in a completely non-dropwise manner and uses a token router, with a normal sigmoid over the top-k expert logs per token.
Ways to insert text, images, and tools. Text output methods, reasoning, and tool use. The model supports an input core length of 128K and a maximum generation length of 64K.
Hardware Requirements and Quantization
Three benchmarks are available with minimal GPU requirements: BF16 (16-bit) requires 4× B200 or 8× H100 GPUs; FP8 (8-bit) requires 2× B200 or 4× H100 GPUs; W4A4 (4-bit) uses one B200 or 2× H100 GPUs. All three measurements show negligible differences in benchmark quality. Cohere recommends W4A4 for most applications.
W4A4 Quantization Methodology
Cohere uses NVFP4 W4A4 calibration, 4-bit weights and advanced scaling activation, for MoE professionals only. The attention mechanism, which includes Q/K/V/O prediction, KV memory, and attention computer, is maintained with perfect accuracy.
To cover residual quality gaps, Cohere uses Quantization-Aware Distillation (QAD) in the post-training phase: a quantized learner model is trained to match the distribution of the teacher's output with full accuracy, using false approximation operators in the forward approximation and exact approximations in the backward approximation.
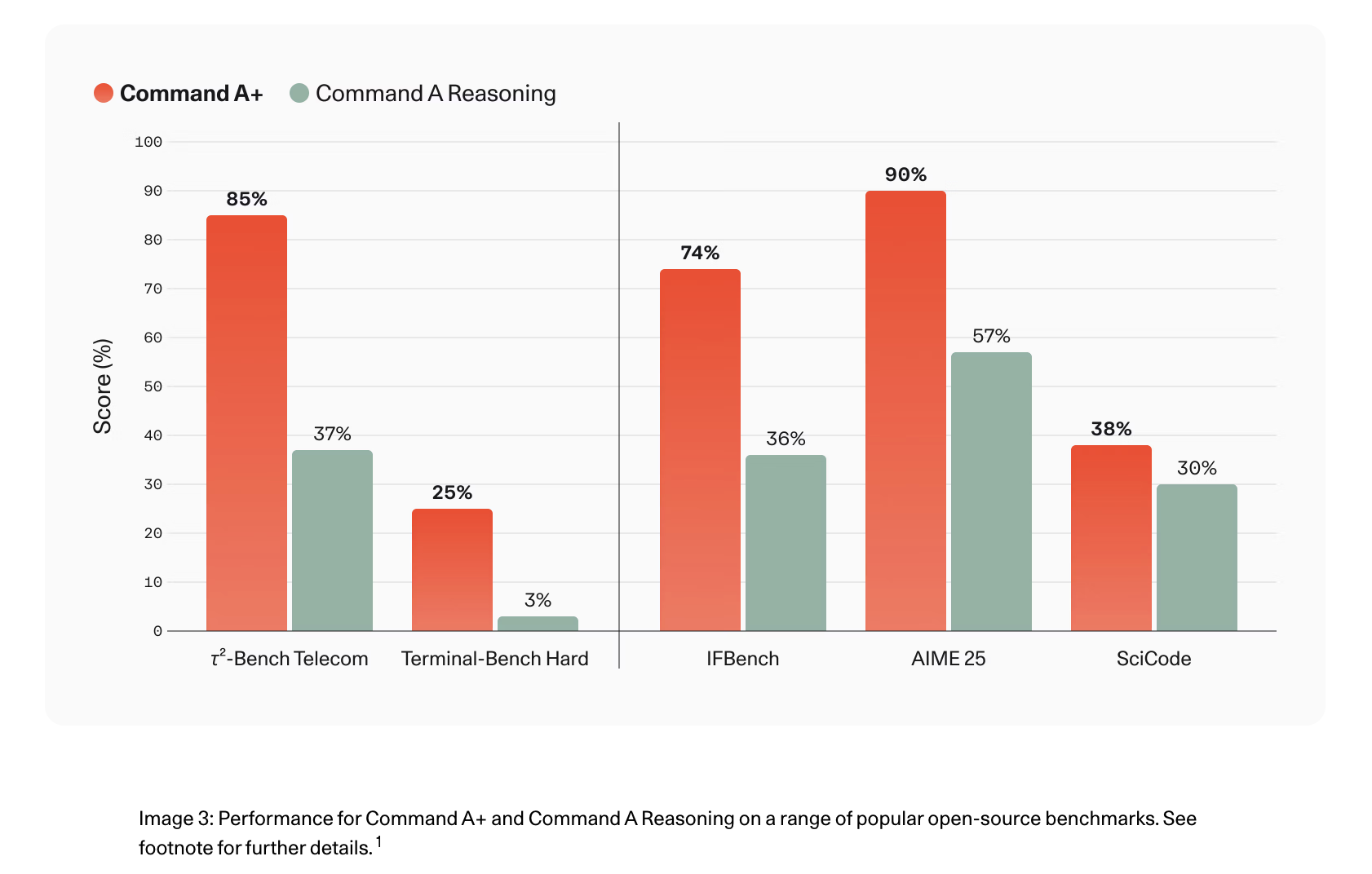
Performance vs. Front of Command A Models
In τ²-Bench Telecom, the score improved from 37% to 85% over Command A Consultation, and Terminal-Bench Hard agent code performance reached 25% from 3%.
In an internal analysis of the North field, all scored using LLM-as-a-judge techniques, Agentic's query response accuracy improved by 20% over Command A Consulting. Agentic QA measures how well the model answers business questions using cloud file systems connected to the MCP. The quality of the spreadsheet analysis improved by 32%, and the Quality of Memory Use — measuring how well the agent uses information from the previous session to answer questions in the next session — scored 54% with Command A+ compared to 39% with Command A Reasoning.
Command A+ is Cohere's first multi-modal consulting model. It scored 63% in MMMU Pro and 75.1% in MMMU, compared to 65.3% for Command A Vision in the latter. MathVista's score improved from 73.5% to 80.6%, and CharXiv's reasoning improved from 46.9% to 52.7%.
Command A+ extends multilingual coverage from 23 to 48 languages, with benefits in machine translation and multilingual thinking.
Command A+ scored 37 on the Artificial Analysis Intelligence Index, outperforming other leading open source models.


Speed and latency
At the same scalability and concurrency levels, Command A+ delivers up to 63% higher Tokens Per Second (TOPS) and lowers Time To First Token (TTFT) by up to 17% compared to Command A Reasoning. W4A4 benchmarking contributes to an additional 47% increase in speed and a 13% reduction in latency. Predictive coding, specially optimized for MoE architecture, delivers an additional 1.5–1.6× speedup for both textual and multimodal input.
The Tokenizer
Command A+ is the first model to use the latest Cohere token, reducing the number of tokens needed to generate the same response. Token efficiency improved by 20% for Arabic, 16% for Korean, and 18% for Japanese.
Getting started
The model is supported by vLLM and Transformers. Tool usage is handled by dialog templates in Transformers using the JSON schema for tool definitions. When inference is enabled, the model generates inference clues <|START_THINKING|> again <|END_THINKING|> tags before generating the final response.
The W4A4 variant requires vLLM ≥0.21.0 and cohere_melody>=0.9.0 to get an accurate answer. Cohere recommends the following sampling parameters: temperature=0.9, top_p=0.95again repetition_penalty=1.04.
Key Takeaways
- Command A+ has a total of 218B/ 25B valid parameters in the Sparse MoE structure, released under Apache 2.0.
- W4A4 uses NVFP4 calibration for MoE experts only with QAD post-training, working with 2× H100s.
- τ²-Bench Telecom improved from 37% to 85%; Terminal-Bench Hard from 3% to 25% vs. Command A Consultation.
- TOPS increased up to 63% and TTFT decreased up to 17% compared to Command A Consulting in the same benchmark.
- Command A+ is Cohere's first multi-platform consulting model, expanding language support from 23 to 48 languages.
Check it out Model weights again Technical details. Also, feel free to follow us Twitter and don't forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



