Deepseek AI Releases DeepseekMath-V2: Open Weight Maths Model Scores 118/20 at Putnam 2024

How can an AI program present complex Olympiad Level math problems in clear natural language while checking that its reasoning is actually correct? Deepseek AI released Deepseekmath-v2a large model of an open language optimized for natural language Therorem is self-validating. The model is built Deepseek-V3.2-Exp-Baseworks as Parameter 685b It's a professional mix, and it's available for free under the Apache 2.0 license.
In testing, DeepseekMath-V2 achieves Gold scores for IMO 2025 and CMO 2024and gain 118 of 120 points in Putnam 2024 when used with a suitable test scale.
Why are the final rewards for answering not enough?
The most recent statistical models use dynamic models only Final Answer on benches like aime and hmmt. This method forced models from weak animals that were close to satulation in short response competitions of about one year. (face binding)
However, the intensive research team shows two structural problems:
- A correct number answer does not guarantee correct reasoning. The model can reach the correct number with algebraic errors that cancel out.
- Many tasks, such as Olympiad proofs and theorem provers, require a complete argument in natural language. These tasks do not have a single final number answer, so the usual base-based rewards do not apply.
DeepseekMath-V2 is therefore cold quality of evidence rather than pure response accuracy. The system evaluates whether evidence is complete and logical, and uses that evaluation as a leading learning indicator.
Training confirmation before the generator
Important design Verifier first. A deep research group is training a validation-based LLM that can study the problem and the candidate's evidence, then the output of the natural language analysis and the quality score are enclosed in the set {0, 0.5, 1}.
Information on reinforcement learning is emerging The art of problem solving competitions. The research team is crawling 17,503 proof style problems From the Olympics, team selection tests, and 2010 problems that clearly require evidence. These problems form the basis set Cold Start RL. The evidence of the person facing the election comes from the deep reasoning model-v3.2 drawn by the Interactive relictive relictive itself its solutions, which increases the information but also creates many incomplete evidences. Human experts label this personality using a 0, 0.5, 1 rubric, based on rigor and completeness.
The guarantee is qualified Policy related group (GrPO). The reward has two elements:
- A Format rewardwhich checks that the Verifier's output follows a set template, including the analysis section and the final score in the box.
- A Reward Pointswhich penalizes the absolute difference between the predicted score and the expert score.
This section produces a guarantee that can reach the Gransyliad Style Proquefly in a consistent way.
Meta validation to control Cliques is clear
The guarantee can still play a reward. It can exclude relevant endpoints while establishing unrealistic constraints in the analysis. This will satisfy the purpose of the numbers but make the interpretations unreliable.
To address this, the research group presents a Meta Guarantee. Meta verification studies the original problem, the evidence, and the verifier's analysis, and then checks that the analysis is reliable. It finds features such as the renewal of measures, the identification of real errors, and the consistency between the narrative and the end.
The meta guarantee is also trained for grpo, with its format and score rewards. Its derivative, the meta quality score, is then used as an additional reward term for the base guarantee. Analyzing that good Hallucaline problems get low meta scores, even if the final test scores are good. In the test, this suggests a moderate quality of the meta-analysis evaluated from all sides 0.85 to 0.96 In terms of validation, while maintaining the accuracy of the Broad Stable score in the stable.
Self-verification of evidence and subsequent refinement
When the confirmation is strong, a deep research team trains Verification of evidence. The generator takes the problem and the point Both the solution and a Self-analysis That follows the same rubric as the ventifier.
The reward generator consists of three signals:
- Verifier scores on generated evidence.
- Agreement between the self-score and the Verifier's score.
- A meta-analysis validation score.
Officially, the biggest reward is using the instruments α = 0.76 to get proof points again β = 0.24 To get the self-analysis part, it is repeated with a format word that emphasizes the output structure. This forces the generator to write proof that the ventifier accepts, and is reliable with the remaining problems. If it says the flawed evidence is complete, it loses the reward for disagreeing with the low meta scores.
Deepseek is also exploitative 128k token limit of the basic model. For difficult problems, the generator often does not solve all the problems in one pass, because the refined evidence and analytical analysis can pass the context. In that case, the program runs Sequential refinement. It creates evidence for self-analysis, feeding itself back as context, and asking the model to generate new evidence that corrects previously discovered issues. This loop can repeat several times, depending on the context budget.

Standardization validation and automatic labeling
As the generator improves, it produces complex evidence, which is expensive to label manually. To maintain the new training data, the research group imports i Automatic labeling pipeline based on measured validation.
For each test item, multiple independent program samples were analyzed, testing each analysis using a meta-analysis. If high-quality high-quality analyzes converge on the same major issues, the evidence is labeled as negative. If there are no favorable meta-analysis criteria, the evidence is written as overall. At the end of training This pipeline replaces human labels, with color checks that ensure good agreement with experts.
Competitive and Benchmark results
The research team tested DeepseekMath-V2 on several solutions:
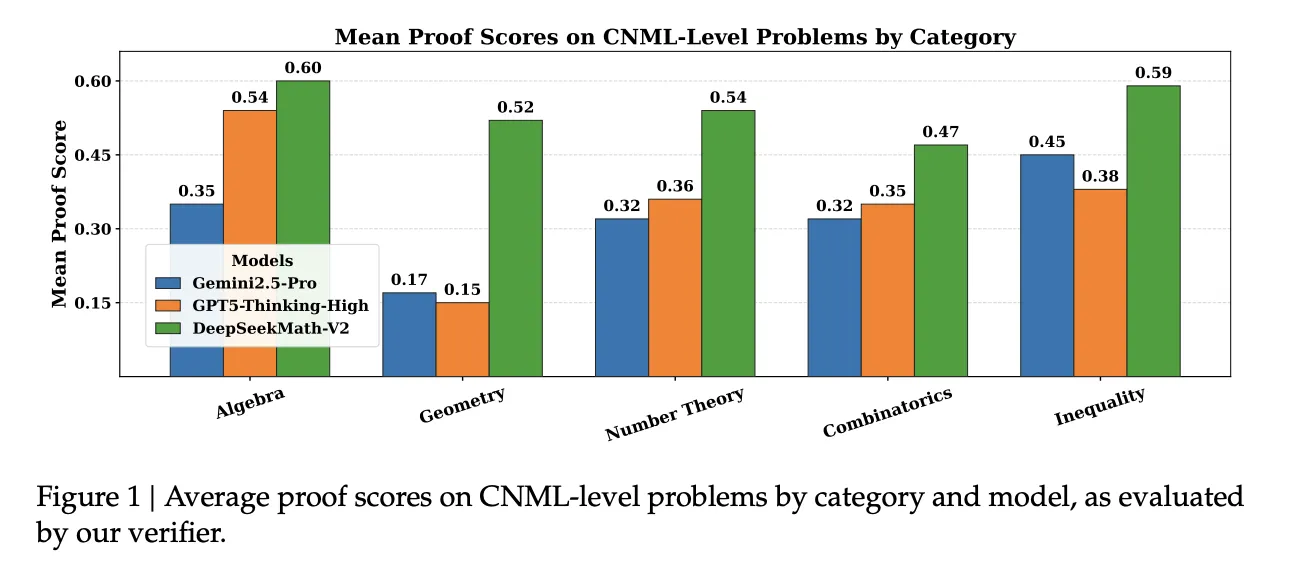
In the inner set of 91 CNML Level Problems covering algebra, geometry, number theory, combinatorics, and inequalities, shows that DeepseekMath-V2 achieves a high degree of provability Gemini 2.5 Pro, GPT 5 thinking highand DeepseekMath-V2 in all categories, as measured by their guarantee.
Despite of- IMO Shortlist 2024successive refinements with self-validation improve both pass 1 and the best of the 32 top metrics as the maximum number of places increases.

Despite of- IMO Provenexpert evaluation Examining the above figure shows that DeepseekMath-V2 Outperforms Deepmind Deepnink imo gold In the basic subset, it continues to compete in the advanced subset, while clearly outshining other major models.

For complete competitions, report:
- IMO 2025: 5 out of 6 problems solved, Gold Medal level.
- CMO 2024: 4 issues fully resolved
- Putnam 2024: 11 out of 12 problems are completely solved with the remaining problem with minor errors, because 118 out of 120 pointsabove a personal best figure of 90.
Key acquisition
- DeepseekMath v2 is a 685b parametric model built on the Deentiseek v3.2 Exp base, developed for natural language proof-of-concept, and released as open source under the Apache 2.0 license.
- Main Innovation is the first training pipeline for the first time with a trained grpo venifier and meta venifier that confirms evidence with hard evidence, not only the final answers, which directly addresses the gap between the right answers and the right thinking.
- The evidence generator is then trained against this ndifier and meta ventifier, using rewards that include evidence quality, agreement and self-evaluation, and truth analysis under the context of 128k to iteratively adjust.
- With scaled test time compute and large verification budgets, DeepSeekMath V2 reaches gold level performance on IMO 2025 and CMO 2024 and scores 118 of 120 on Putnam 2024, surpassing the best human score that year.
Editorial notes
DeepseekMath-V2 is an important step in the validation of mathematical calculations, because it directly addresses the gap between finding the final answers and the applifier, CMO 2024 and the Performal Generator trained for the performance of IMO 2025, CMO 2024 and Putfered 118 Score in Putnam 2024. Overall, this release shows that the mathematical validation of open instruments is now it has become accessible to the problems of the level of competition.
Look Full paper, model instruments in hf and It's a waste. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



