From Transformers to fusion memory, that Titans and Miras bring back a long model of content

What comes after the revolutionaries? Google research suggests a new way to provide models of working time sequences Long-term memory with Titans and Miras, while keeping the training similar to linear refresh.
Titans are concrete structures that add a deep neural memory to the transformer style. MIRAS is a general framework that views today's sequential models as instances of online memory usage through self-contained memory.
Why Titans and Miras?
Standard converters use attention over a value buffer. This provides a solid read context, but the cost clearly increases with the length of the context, so the active context is limited even by flashternantsions and other kernel tricks.
Parallel active neural networks and state space models like mamba-2 compress the history in the case of fixed size, so the costs are linear in length. However, this reduction loses information on very long sequences, which is detrimental to tasks such as genomic modeling and extreme context retrieval.
Titans and miras embody these ideas. Attention acts as short-term memory for the current window. A separate neural module provides long-term memory, learns during testing, and is trained for its ability to benefit from accelerators.
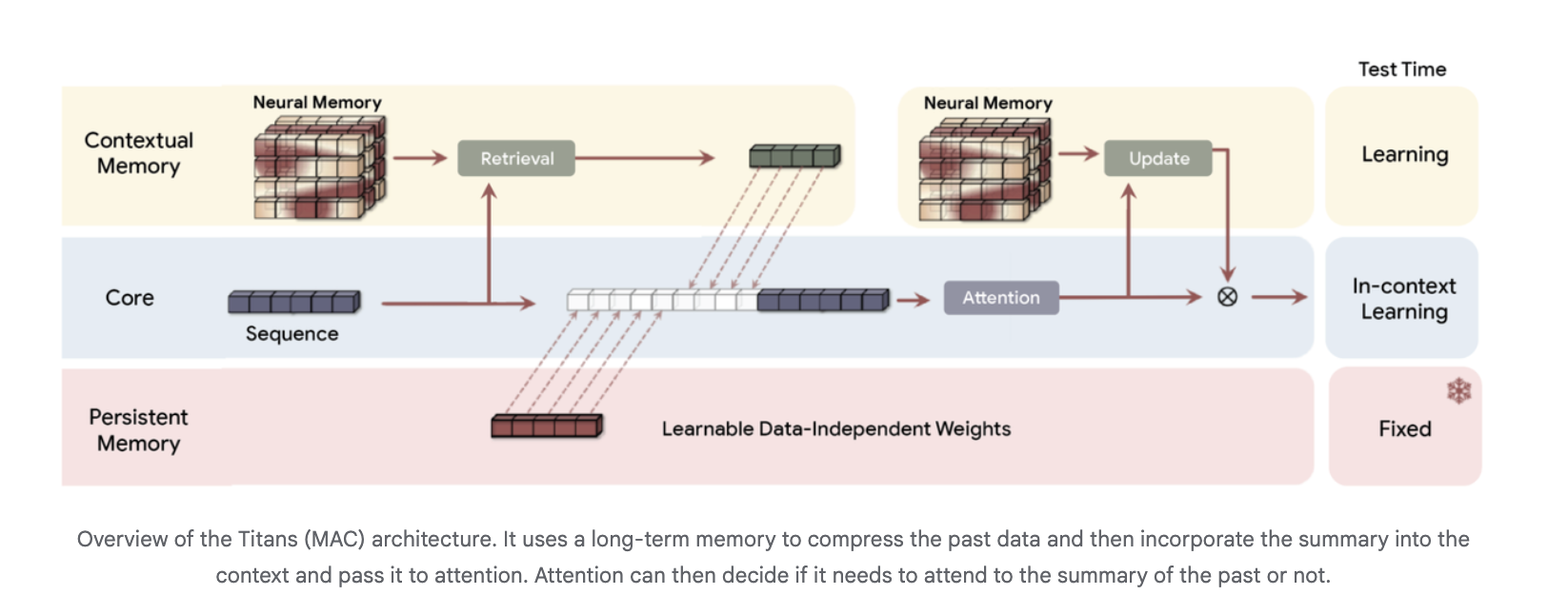
Titans, the long-term long-term memory we learn during testing
The Titans research paper introduces a neural long-term memory module that is itself a deep perceptron rather than a vector or matrix state. Decoding is interpreted as short-term memory, because it only sees a limited window, while neural memory works like long-term memory.
For each election, the titans describe the memory loss associated with it
ℓ (mₜ₋₁; kₜ, vₜ) = vₜ) = ‖Mₜ₋₁ (Kₜ) – Vₜ‖²
Where Mₜ₋₁ is the current memory, Kₜ is the key and vₜ is the value. The gradient of this loss in relation to memory parameters is the “surprise metric”. Larger gradients correspond to surprising tokens that should be kept, smaller gradients correspond to expected tokens that are largely ignored.
The memory parameters are updated during the test with gradient descent with momentum and weight, all of which work well as a matrix multiplication point, which shows how to prepare for the reading of successive matrices.
Architecturally, Titans uses three branches of memory in the backbone, usually running on Titans Mac Variant:
- A basic branch that generalizes in the context of attentional learning
- A memory branch of content that is read in the latest order
- A branch of persistent memory that has organized hardware that contains import information
Long-term memory stores tokens of the past in a condensed form, and is transmitted as additional context for attention. Attention can choose when to read that summary.
Test results for titans
In the language model and nice reference benches like C4, Wikitext and hellaswag, the more architectural form of the updated art line is rewritten and the same size. Google Research attributes this to the high optical power of deep memory and its ability to maintain performance as memory length increases. Deep neural memories with the same parameter budget but higher depth consistently give lower precision.
For more recall, the research team uses the Babilong Benchmark, where the facts are distributed over very long documents. Titans judge all supporters, including very large models like GPT-4, while using few parameters, and the scale in Windows Contectlex without 2000,000 tokens.
The Research Team reports that the Titans maintain the same active training and direct submissiveness. Neural memory is less alone than the standard models agree, but the layers of hybrid titans with the attention of sliding windows are always competing with sprinkles while improving accuracy.
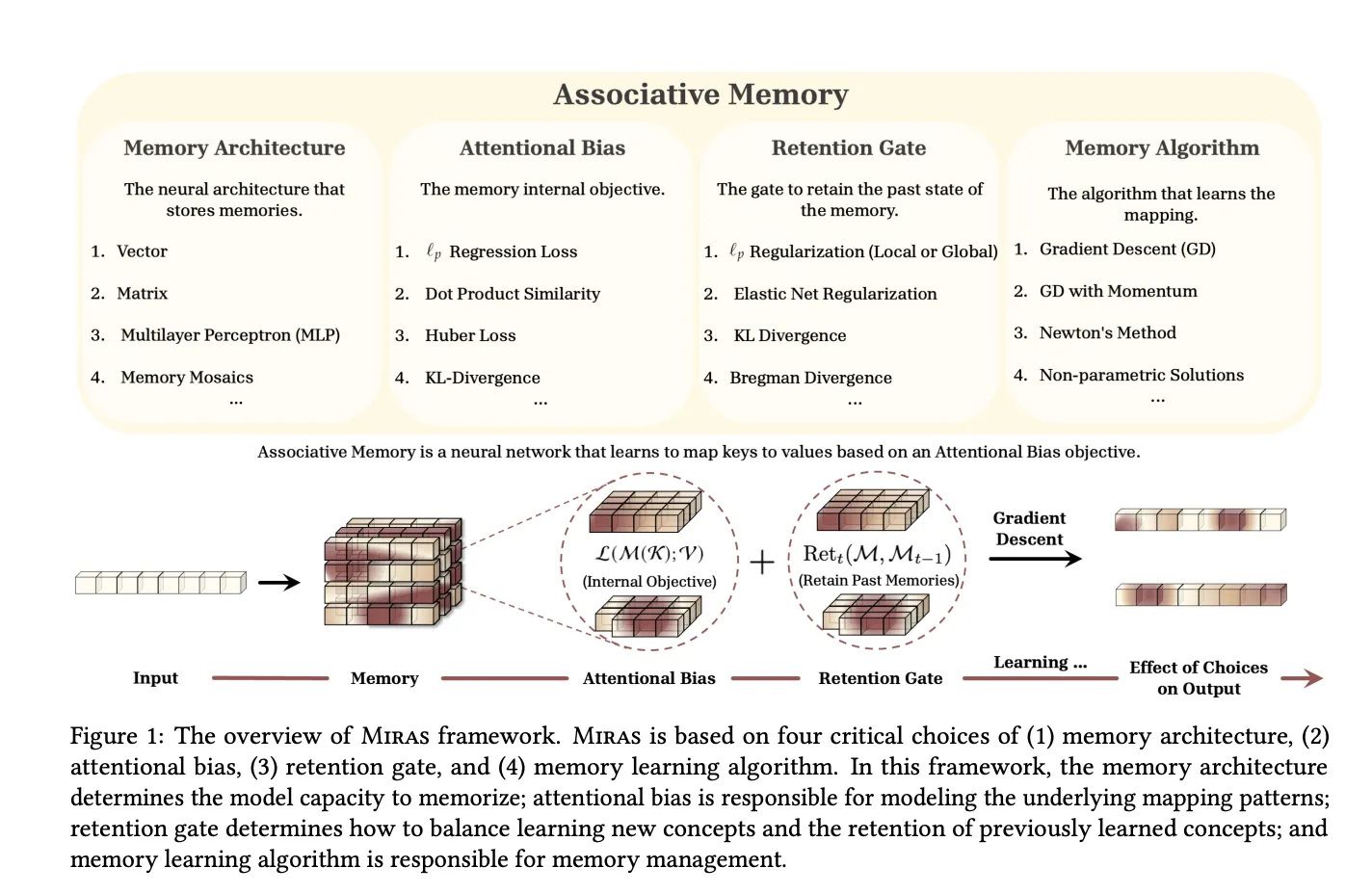
Miras, a unified framework for sequencing models as an associative memory
Miras' research paper, “Everything is connected: A journey through Test Time Moms, neglect, maintenance, and maintenance of the Internet,” applies this idea well. It recognizes that modern models of sequencing can be seen as collective memories until the keys are mapped while equating learning and forgetting.
Miras describe any sequence of four design decisions:
- Memory structure For example veter, direct map, or MLP
- Ignoring the Choice the inner loss that explains that he misses remembering
- The last gate a striker that keeps the memory close to its past state
- Memory algorithm rule of thumb to work online, usually gradient feant with Momentum
Using this lens, the Miras recover several families:
- Standard Hebbian Stykey Linear models and retnet as Dot Product Poly Assomiative Memories
- Delta Rule models such as Deltanet and Goltanet deltanet + MSE based memories with value recovery and specific storage gates
- Titans LMM as memory based nonlinear MSE with local and global storage made of gradient feost with Momentum
Obviously, the Riras then go beyond the standard MSE or DOT product targets. The research group created a new discrimination based on Lₚ methods, strong huber loss, and new final gates based on diplences with a probability price, standard Bregman.
In this design space, the research team has developed three free models:
- Man and Monerale It uses 2 layers of memory
- Yawad It uses the same memory of MLP with the huber loss of oblivion and the oblivion gate related to the Titans
- The side of learning badly Use reverse loss as bias ambiguity and final KL subtraction gate with prouse styx Memory Memory.
These various miras replace the llama-style focus on the spine, use the high splits that are separated from the Miras under, and can be combined with the sliding window focus in the hybrid models. Training is always the same in terms of sequence and gradient gradients with respect to the memory state from the previous chunk.
In research tests, Moneta, yaad and the Memora game or surpasses the usual standard models and transformer ++ in the model language, to remember extensive tasks, while remembering deep time tasks.
Key acquisition
- Titans present deep long-term neural memory learning during testingwhich uses a decent gradient in the loss of L2 Associative Memory so the model preserves surprising stores while preserving visible updates in accelerators.
- Titans combine attention with long-term neural memorywhich uses branches such as core, content memory and persistent memory therefore short maintenance short accuracy and neural module stores information over 2000,000 tokens.
- Strong Titans Experforms for RNNS and Transformers + BaseLinesincluding Deltanet for Mamba-2 and Gated Deltanet, in language mode and commonsense reference benchmarks in comparable parameter estimation, while remaining competitive and pass-through.
- In terms of the longest recall benches such as BabilongTitans achieve the highest precision of all basulines, including large attention models such as GPT 4, while using fewer parameters and still capable of effective training and detection.
- Miras provide a unified framework for sequential models such as associative memoriesExplaining the structure of the memory, attention bias, storage and control, and revealed new attention to structures such as Moneta, transformer ++ in the framework of long tasks and consulting tasks.
Look Technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.



