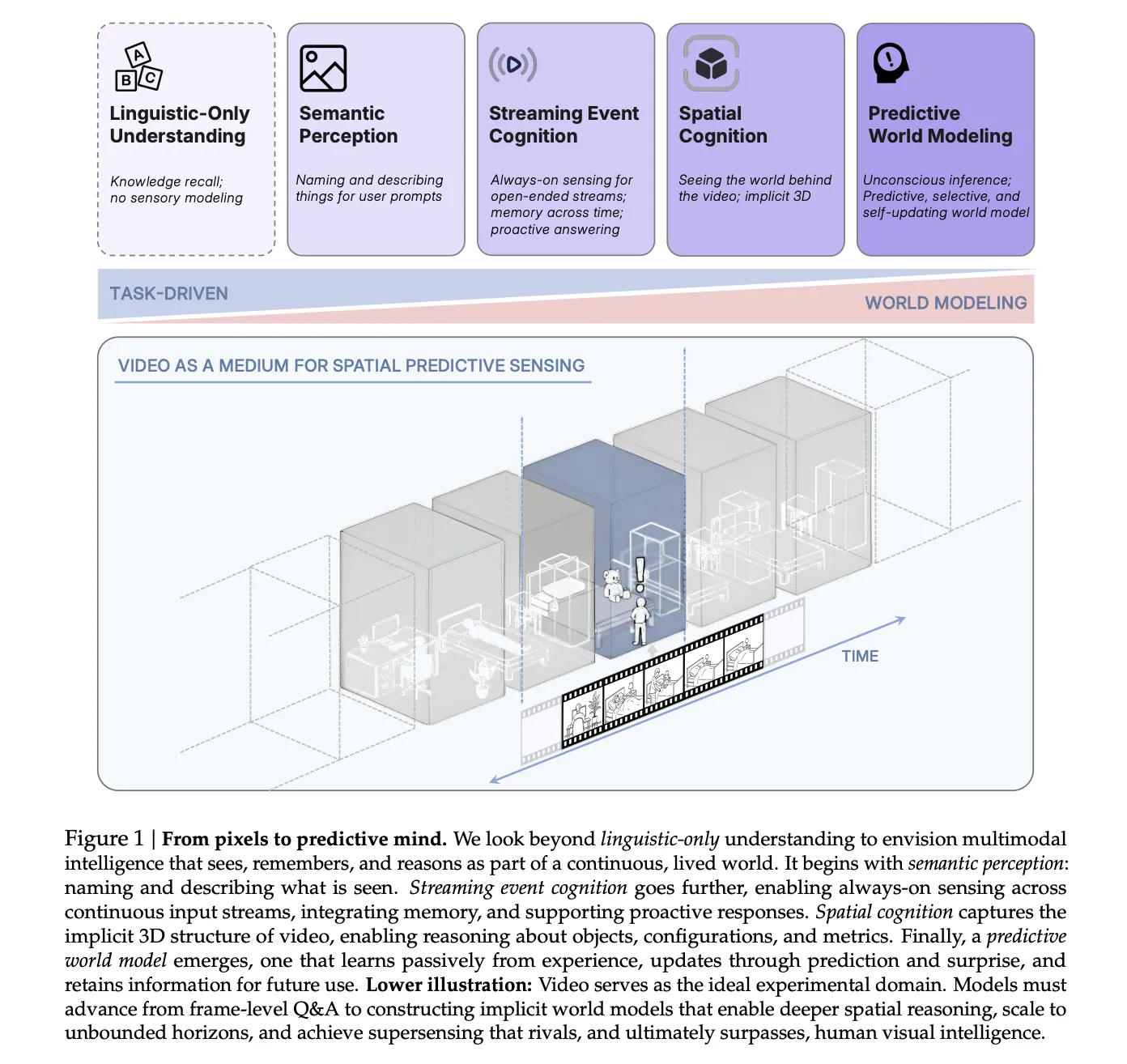
Why is Spatial Supersensing emerging as a core capability for multimodal AI systems?

Even robust 'long-term' models have failed miserably when they have to track things and account for long, messy streams, so the next frontier of competition will come from models of predict Next comes next and by choosing to remember only surprising, important events, not in just buying more windows of content. A group of researchers from New York University and Stanford imported cambria-s, a large video multimodal language family, and the vsi super benchmark and the vsi 590k dataset to test and train spatial supersensing on long videos.
From the video question he answers to the Spatial Supersensing presentation
The research group of spatial structures confuses it as a skill that goes beyond the ability to live languages alone. The categories are semantic perception, broadcast event perception, comprehensive spatial perception and projection world projection.
MLLMS current MLLMS video sample space and language dependent. Often they answer Benchmark questions using topics or random frames rather than continuous visual evidence. Diagnostic tests show that a few popular video benchmarks are solved with limited input or text only, so they don't really test the location sensitivity.
cambiker aims at the higher stages of this phenomenon, where the model has to remember the spatial properties at the same time, reason about the object locations and calculate and anticipate changes in the 3D world.
Vsi super, continuous sound pressure test
To reveal the gap between current systems and spatial interference, the research team designed vsi super, a benchmark in two parts that works on incredible videos.

Vsi super recall, or VSR, tests long-range vision and recall. Human annotators take Walkthrough Walkthroughs from Scannet, Scannet ++ and Aritscenes and use Gemini to insert something unusual, such as a ground bear in different parts of the pipe. This programmed sequence is diluted in streams up to 240 minutes. The model must report the order of places in which the object appears, which is a visual input to Haystack's sequential recall operation.

VSI Super Count, or VSC, measures continuous counting under changing views and rooms. Benchmark concaterates HOUROR TOURTS clip from the vsi bench and queries the number of times of the target object in all rooms. The model must deal with view changes, updates and scene changes and maintain a cumulative count. The test uses relative precision mean times from 10 to 120 minutes.
When cambrian-s 7b is tested on vsi super in the broadcast setting at 1 frame per second, the accuracy is 38.3 percent by 10 percent by 60 percent by 60 percent. The accuracy of VSC is close to zero at length. Gemini 2.5 Flash also degrades with vsi super despite long windows, showing that the Brute Force core contention is not enough for continuous area sensitivity.
VSI 590K, data intensive instruction
To check that scaling data can help, the research group created a vsi 590k, spatial command orpus with 5,963 videos, 490,658 images responding in pairs from 10 sources.
Sources include real 3D Scans available as scannets such as scannet, scannet ++ v2, arkitscenes, s3dis and web pseudo data such as youtube for the Web and Agibot.
The dataset defines 12 spatial query types, such as object count, absolute and equivalent distance, object size, room size and order order. Queries are generated by 3D annotations or reconstructions where spatial relationships are incorporated into geometry rather than textual heuristics. Abrations show that the real explanatory videos offer the greatest advantages over the vsi on the bench, followed by the generated data and the Pseudo-annotated images and that the full training gives the best local performance.

Cambiker model model and local performance
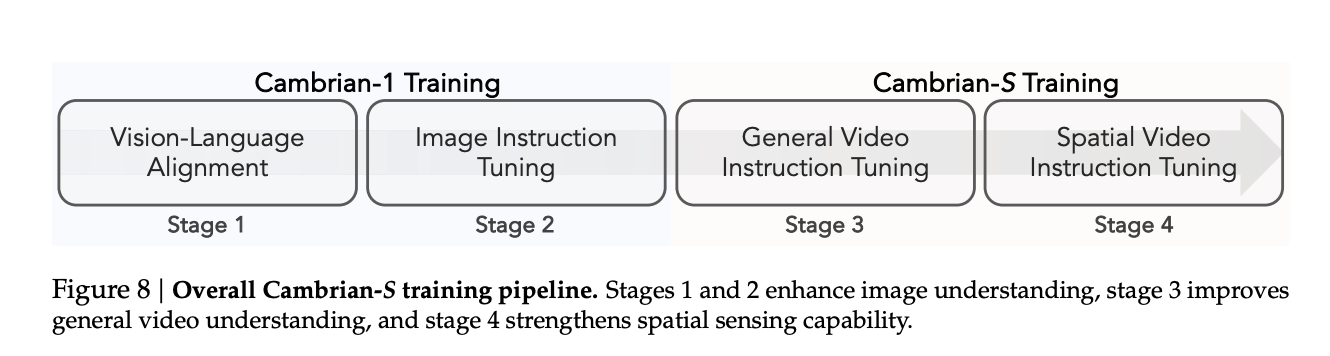
Cambria builds on cambria-1 and uses the QWENO2.5 language Backbones with 0.5B, 1.5b, 3b and 7B parameters and Siglip2 Sonder MLP connector and second MLP connector.
Training follows a Four-phase pipeline. Section 1 Perform visual language matching on Image Text Pairs. Section 2 It uses the image sound settings, equivalent to the advanced settings of cambria-1. Section 3 It accesses the video via General Video Materion Tuning's million sample mixer called CamBrian-S 3M. Section 4 Perform spatial video sending commands on the vsi 590k mix and a subset of the Section 3 data.
On the vsi bench, the cambria-s reaches an accuracy of 67.5 percent and acperformff aupport Sport Baselines such as intervl3.5 8B and Qwen VL 2.5 7B and proprietient gemini 3.5 Pro with a total of 16 points. The model also maintains strong performance in comprehension tests, eGoschema and other standard video benchmarks, so local auditory focus does not destroy general abilities.
Anticipating Hearing by Predicting Latent and Surprise
To go beyond the static context, a group of researchers proposes predictive sensing. They added the Latent Frame Predictit header, which is two MLPs that predict the next representation of the next video frame by matching the next token prediction.
Training is transformative Section 4. The model uses the measured error and the loss cosine distance between the predicted truth and the ground truth these factors, weighted against the language loss. A subset of 290,000 videos from vsi 590k, edited at 1 frame per second, was reserved for this purpose. During this phase the connector, the language model and both heads are trained together, while the Siglip Vision Encoder remains frozen.

In cosine detection the distance between the predicted and actual features becomes the deviation points. Frames with low stun are compressed before being stored in long-term memory and frames with high stun are stored in more detail. The non-volatile memory uses randomness to determine which frames to merge or discard and which queries return the frames that best match the query.

With the VSR, this shot-driven memory system allows for the ultimate accuracy of the Cambria Outperforms Gemini 1.5 Flash and Gemini 2.5 Flash in VSR at all times tested and avoids the sharp degradation seen in expansion-only models.
With VSC, the research team listens to the event-driven classification system. The model accumulates features at the level of the event and when the most surprising situation the signal of the scene of the event changes, summarizes that the buffer is part of the stages it responds and resets the buffer. The answers to the integration part provide the final calculation. In the broadcast attack, Gemini Live and GPT Realtime reaches less than 15 percent mean relative accuracy and drops close to zero at the 120-minute limit, while the cambrian has a shock wave that reaches about 38 percent and maintains 28 percent at 120 minutes.
Key acquisition
- The cambria-s and vsi 590k show that careful spatial data structure and strong video mlms can greatly improve spatial understanding on the vsi bench, but they simply fail on the vsi super, so the scale alone does not solve the potential for spatial distortion.
- VSI Super, with VSR and VSC, is purposely created from long videos that cross within the stress of continuous spatial visualization, which is easy to visualize in the standard window sample.
- Benchmarking shows that Frontier models, including the Gemini 2.5 Flash and Cambrian s, cambrian super cameras even if the length of the video is always limited to low context.
- A latent prediction module based on a prediction module based on the Latent Framentrance Expression Module, or surprise, driving memory compression and the event wave, which shows great advantages in VSI Super compared to long content areas while maintaining a stable GPU memory usage.
- The research work places in the full area as the kingship from the semantic display to predict the models of the world that are predicted and argue that the mlms of the future video should include the video memory of the future, not only large models, to handle unlimited streaming video in real applications.
cambria-s is a useful stress test for current video mlms because it shows that vsi super is not just a heavy bench, it reveals the systematic failure of long-form architectures that still rely on active visualization. The predictive projection module, based on the background frame prediction and the memory of the surprise burst, is an important step because the couples feel the area they feel with the data of the internal world rather than only the data and parameters. This study signals a shift from video guidance to predictive modeling as the next goal in the design for multimodal models.
Look Paper. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.



