
The dappas processing remains important to the success of the machine reading, but the actual world dates usually contain errors. Cleanlab usage data using an active solution, includes its Python package to use algorithms convincing algoriths. For alternating received and correction of label errors, Cleasalab simplify the process of study data before the machine's learning. With its use of statistical methods to identify data problem, the Cleanlab gives the first power of data using Cleanlab Python to develop model's reliability. For example, the SCLABABSWHSWHSWHSWHSWINGSHIPS WEARS, improve machine learning effects with small effort.
Why do you have to get the news data?
Directly input data has a direct impact on model performance. The dirty data with incorrect labels, merchants, and non-compliance leads to negative predictions and unfaithful discernment. Models are trained by accurate data that enables these errors, creating the effect of throwing unique things throughout your plan. Quality quality of completion of these issues before starting the priority.
Pre-work performance also saves time and resources. Pure data means few models of models, quick training, and cost of integration. It prevents the frustration of models that conflict with them when the real problem is lying on details itself. The main conversion changes the green data into important information that algorithms can read successfully from.
How can you find a broader data using Cleanlab?
Cleanlab helps clean and verify your data before training. It finds bad labels, duplicate, and low-quality samples use ML models. It is very good to get a label and the data quality checks, not a basic text.
Important CLEANLAB Factors:
- Receives lost data (noisy labels)
- Flags flags and emptied
- Checks low or non-relevant samples
- It provides a label of Insights
- Works with any ML Classifier to improve data quality
Now, let's go how you can use the Cleeanlab action by the step.
Step 1: Installing libraries
Before you start, we need to install a few important libraries. This will help us to load data and use well-cleaning tools.
!pip install cleanlab
!pip install pandas
!pip install numpy- Cleanlab: To get a label and data quality problems.
- Pandas: Reading and managing CSV data.
- NUNPY: Supports instant rates used by Cleanlab.
Step 2: Upload Dataset
We now upload dataset using pandas to start re-develop.
import pandas as pd
# Load dataset
df = pd.read_csv("/content/Tweets.csv")
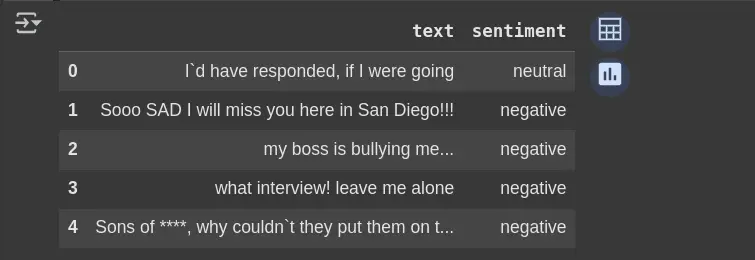
df.head(5)- PD.READ_CSV ():
- df.head (5):
Now, once we have downloaded the information. We will focus on columns only we need and evaluate any lost prices.
# Focus on relevant columns
df_clean = df.drop(columns=['selected_text'], axis=1, errors="ignore")
df_clean.head(5)Remove the selected column_Text if available; You avoid mistakes if not. It helps keep columns needed for analysis.
Step 3: View Labuli Problems
from cleanlab.dataset import health_summary
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.preprocessing import LabelEncoder
# Prepare data
df_clean = df.dropna()
y_clean = df_clean['sentiment'] # Original string labels
# Convert string labels to integers
le = LabelEncoder()
y_encoded = le.fit_transform(y_clean)
# Create model pipeline
model = make_pipeline(
TfidfVectorizer(max_features=1000),
LogisticRegression(max_iter=1000)
)
# Get cross-validated predicted probabilities
pred_probs = cross_val_predict(
model,
df_clean['text'],
y_encoded, # Use encoded labels
cv=3,
method="predict_proba"
)
# Generate health summary
report = health_summary(
labels=y_encoded, # Use encoded labels
pred_probs=pred_probs,
verbose=True
)
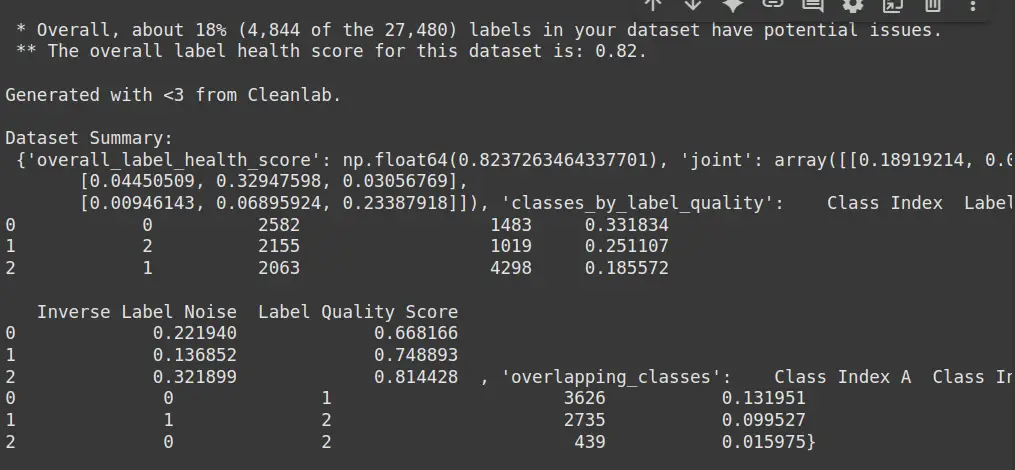
print("Dataset Summary:n", report)- df.dropna (): It removes rows with missing prices, guaranteeing the cleansing data for training.
- Lebencoder (): It turns the thread labels (eg, “DPT”, “o'i”) into integers labels to accompany the model.
- Do_pipeline (): Creates a pipe with TF-IDf Vericizer (converting text to numeric numbers) and model for reconciliation.
- Cross_val_predict (): Make 3-fold cross-verification and revision predicted to be predicted instead of labels.
- Health_Summary (): It uses clean up to analyze opportunities and predicted labels, pointing to potential issues in label as Mislabels.
- Print (Report): Indicates a relief report, highlighting any of the label or errors in the Database errors.
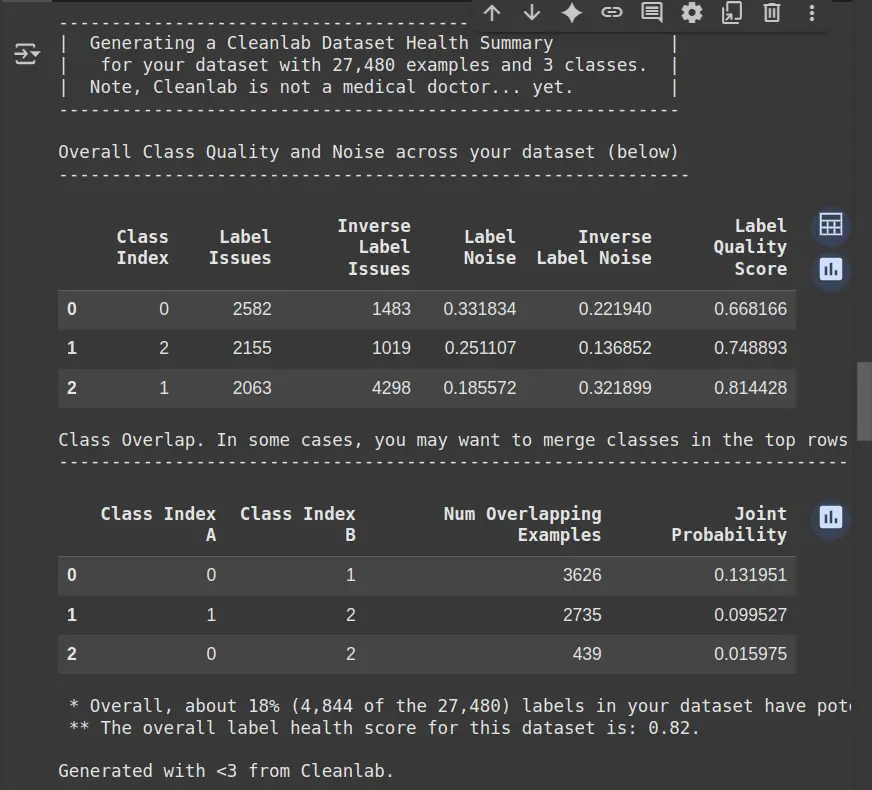
- Label Problems: Indicates how many samples in the class have are wrong labels or strong.
- Various Labuli Problems: Displays the number of situations where the wrong-predicted labels (opposite of true labels).
- Label Audio: It measures the size of the audio (irregularity or uncertain) in each class.
- Enter Label Score Qualig: Displays the full quality of class labels (high points meaning better quality).
- Class A consignment: Identify how many examples disconnect between different classes, and more likely to appear.
- Label Score Work Score: It provides a full indication of the data label of data (high points that mean better health).
Step 4: Get low-level samples
This step adds to and distinguish samples in the database that can have label problems. Cleanlab uses the chances of being predicted and true labels to identify low-quality samples, can be reviewed and cleaned.
# Get low-quality sample indices
from cleanlab.filter import find_label_issues
issue_indices = find_label_issues(labels=y_encoded, pred_probs=pred_probs)
# Display problematic samples
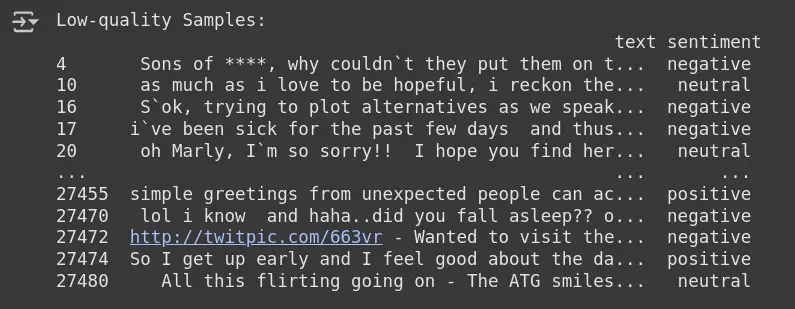
low_quality_samples = df_clean.iloc[issue_indices]
print("Low-quality Samples:n", low_quality_samples)- Get_label_issues (): The work from Cleanlab receives sampled indices for label problems, based on comparisons of predicted (Pre_Probs) and true labels (Y_Proded).
- Uninstall with # indices: It keeps pure samples indices identified as potential censes (ie, low-level samples).
- df_clean.iloc[issue_indices]: Discharge problem rows from clean data (DF_Clean) using low-level indices.
- Low_qual_amample: Holds the samples identified as they have the issues of label, which can be continuously reviewed for preparation.
Step 5: Find sound labels with Model Prediction
This step involves using cleaning, cleaning method, receiving noisy labels in the Databots by training model and using its predictions to identify the non-nalyts.
from cleanlab.classification import CleanLearning
from cleanlab.filter import find_label_issues
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
# Encode labels numerically
le = LabelEncoder()
df_clean['encoded_label'] = le.fit_transform(df_clean['sentiment'])
# Vectorize text data
vectorizer = TfidfVectorizer(max_features=3000)
X = vectorizer.fit_transform(df_clean['text']).toarray()
y = df_clean['encoded_label'].values
# Train classifier with CleanLearning
clf = LogisticRegression(max_iter=1000)
clean_model = CleanLearning(clf)
clean_model.fit(X, y)
# Get prediction probabilities
pred_probs = clean_model.predict_proba(X)
# Find noisy labels
noisy_label_indices = find_label_issues(labels=y, pred_probs=pred_probs)
# Show noisy label samples
noisy_label_samples = df_clean.iloc[noisy_label_indices]
print("Noisy Labels Detected:n", noisy_label_samples.head())
- Encoding label (Lelencer ()): It converts thread labels (eg, “good”, “bad”) to prices, making them ready for machine reading models.
- Vetrization (tfidfvechizer ()): Converts text data into treasures using TF-IDF, focusing on 3,000 most important features from the “text” column.
- A classifierRuesses () train): It uses logical refinement as classifier training model with labels included and the vector text details.
- Cleaning (Cleaning ()): It works cleanliness in a refund model. This approach is considering the power of a model to hold a sound labels by looking at them during training.
- Oppositions of prediction (prediction_proba ()): After training, the model forecasts class opportunities for each sample, used to identify the potential labels.
- Get_label_issues (): It uses the chances of being predicted and true labels to find that the samples with naisy labels (ie, are misshabels).
- Show sound labels: Returns and indicate samples with noisy labels based on their indices, which allows you to review and make it clean.
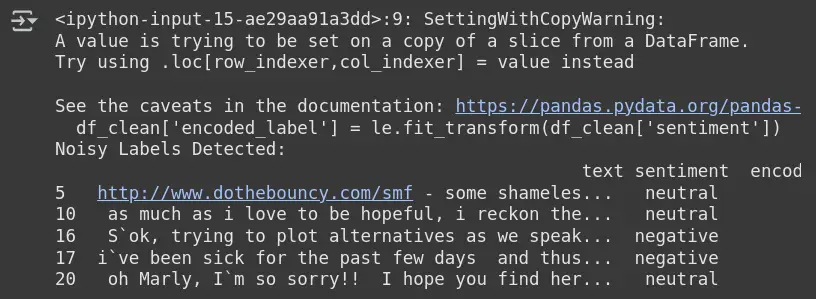
Vision
Exit: Finded by noisy labels
- Pure flagples are clean when the predictable feelings (from model) does not match the provided label.
- Example: Line 5 has been written to be neutral, but the model thinks it may not be.
- These samples may be mistreated or strong based on model behavior.
- It is helpful to see, pay, or remove samples that have a better functional problem.
Store
Presprocessing is the key to making a reliable machine learning models. It removes non-compliance, normal input, and develops data quality. But a lot of work goes missing one thing with noisy labels. Cleanlab fills the gap. It recognizes lost data, vendors, and low-level samples automatically. NEVER want you to learn what you have learned. This makes your clean cleanness and models wise.
Cleanlab cleanness is not just precisely, saves time. By removing bad labels early, he reduces the burden of training. Fewer errors mean quick encounter. More signal, little noise. Models are better, little effort.
Frequently Asked Questions
Ans. Cleanlab helps to find and repair lost, noisy data, or low-quality data in details of label. It helps to the backgrounds such as text, image, and tabar data.
Ans. No. Cleanlab works with the issue of existing models. You do not need to update to find news label.
Ans. Not actually. Cleanlab can be used in traditional ML models and deep reading models, as long as you give opportunities for predictions.
Ans. Yes, the Cleanlab is made for a simple combination. You can start quickly with a few of the code lines, without major changes in your work travel.
Ans. Cleanlab can handle various types of label sounds, including sisale, vendors, and unsure labels, making savings your data and more conviction in training models.
![]()
Hi, I'm Vipin. I have love for data science and a machine reading. I have information in analyzing data, building models, and solving real world problems. I intend to use data to create practical solutions and continue to study in the fields of data science, machine-study, and NLP.
Sign in to continue reading and enjoy the content by experts.
")


