NYU investigators launched Wildchat-50m: Main static data for successful expenditure of the successful llm post-traing training

The main language model (llm) focuses on the assessment of models and enhancing the power of the first training phase. It includes the good direction of good structures (sft) and the validity of models of models for personal preferences and specific requirements. Data generation is important, allows investigators to check and improve learning strategies in the background. However, an open study on this domain is at its first level, faces the data availability and limitations of scale. Without high quality information, analyzing the performance of different conversion strategies and evaluating its functionality to the actual property applications is difficult.
One of the main challenges in the field is not a large scale, is found in public accounting information at the LLM Post-Training details. Investigators should access various chat dassets to make meaning comparative and developing alignment strategies. The lack of standard datasets limits post-training assessment capacity in different models. In addition, the major cost of the generation of the capital and racial needs are prevented from many educational institutions. These items create barriers to improve the efficiency of the model and to ensure well-organized llms are common in the activities and user interaction.
Existing methods for the Code of Data for the Code of LLM Training depends on the combination of models generated and the barn details. Datasets, such as WILLDCHAT-1M from Allen Ai Nelsys-Chat-1M, provide important understanding in the use of data data. However, they are often limited to diversity of rate and model. Investigators develop various strategies to evaluate the quality of the data data, including the evaluation of the llM and efficient electrical performance to operate the operation and use of the Vram. Despite these efforts, the territory still lacks the full dataset and accessible to the community that allows a great exam and effective training methods in the background.
Investigators from New York University (NYU) introduced WildChat-50m, a broad wide dataset designed to facilitate post-operative training. The data is creating a wild collection and extends it to include answers from high open models. These models range from 0.5 to 104 billion parameters, making wildchat-50m of the largest and very different data of communication publicly. The data is enabling broader comparisons of data generation models and is the basic of developing the training strategies in the background. By making wildchat-50m accessible, a group of researchers aims to close the gap between the industrial training and education research.
The data is developed by comparing the writing texts from many models, each participate in over a million conversations. The data contains approximately 125 million conversations, provides an event that has been previously available. The data collection process takes place over two months using a shared survey cluster of 12 × 8 H100 GPU. This setup is allowed researchers to make good use of the time of working and assure different responses. Dataset also acts as a Re-Wild foundation, the highlight of the Fine-Tuning (SFT) MIX develops the efficiency of the LLM. In this way, researchers have successfully demonstrated the Wildchat-50m to prepare the use of data while maintaining high-effective functional performance.
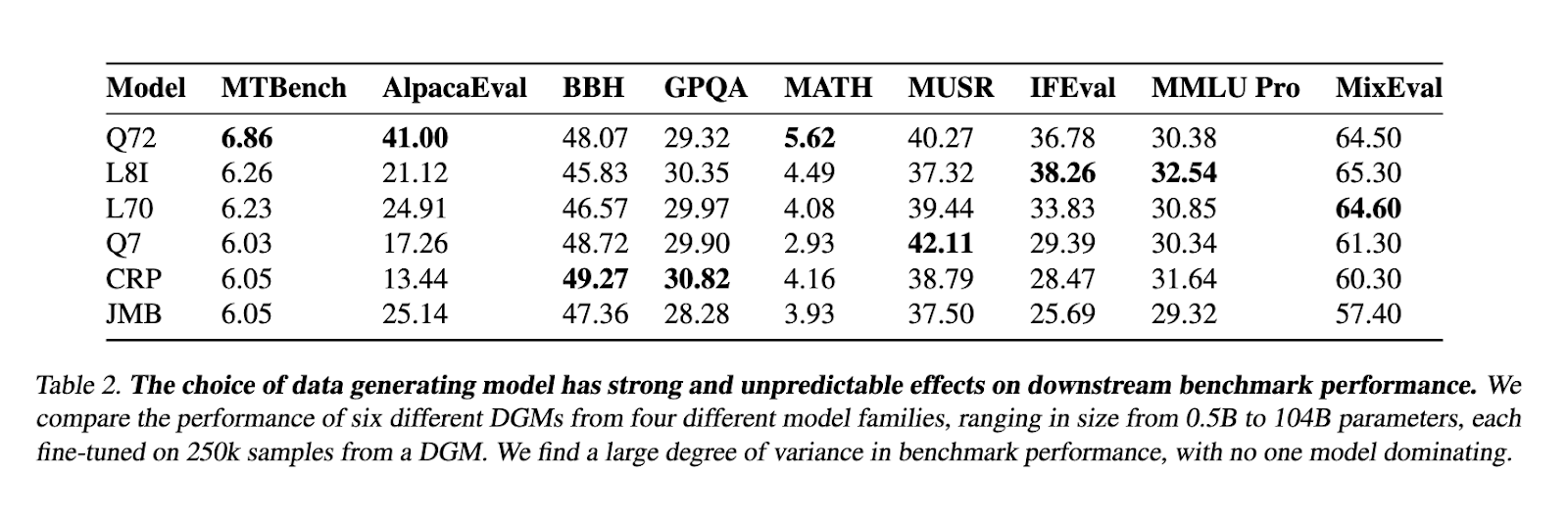
Wildchat-50m operation was confirmed by a series of hard benches. The St-Wild Sald method, based on WILLDCHAT-50M, the OverDened combination of Tulu-3 SFT developed by Allen Ai while using 40% of data size. The test includes multiple operations, for the development of something in response, aligning the model, and the accuracy of the measurement. Details of the Data Development Data Development During the process of working also highlighted, in exchange for exchanging analysis that illustrates greater improvement at the speed of Token. In addition, well-organized models use Wildchat-50M to indicate important enhancements in the skills following training and performance skills to discuss all various testing benches.
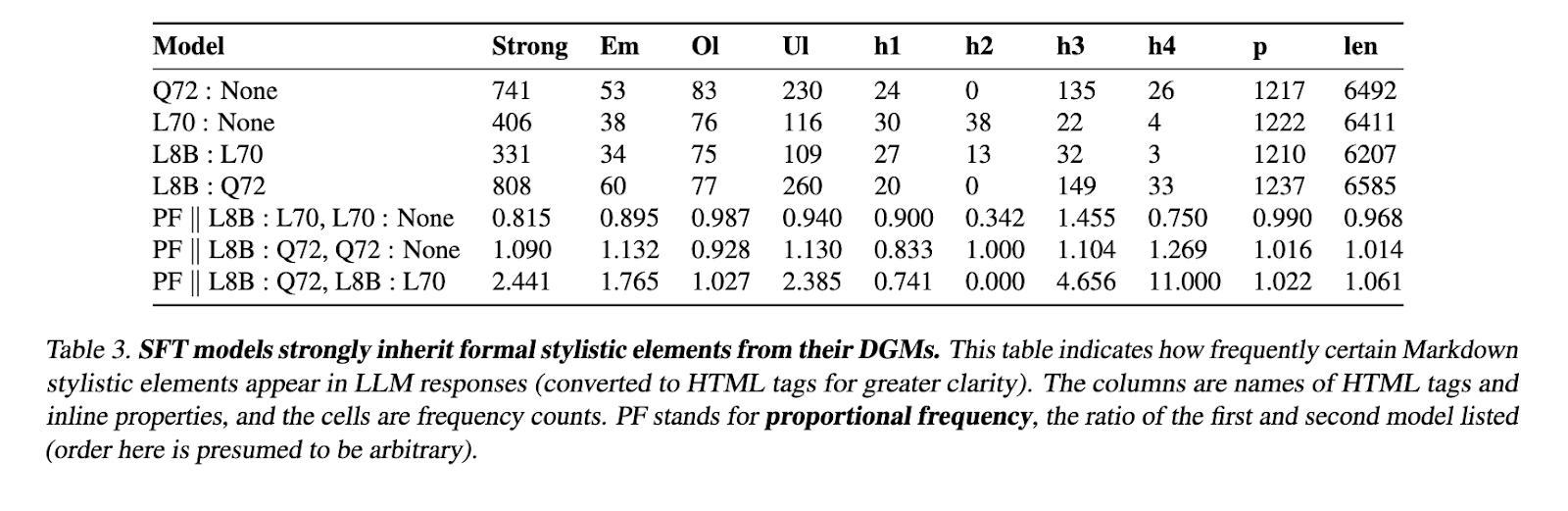
This study emphasizes the importance of the highest data of executing in LLM Post-Training and produces Wildchat-50m as an important source to adjust the model alignment. By providing large data available to the public, researchers have enabled additional development in directing good planning methods. The comparative analysis of this study provides the key understanding of the efficiency of the models generating different data and learning strategies. Moving, the introduction of WILDCHAT-50M is expected to be funded to investigate statements to research statements and industries, eventually including skilled and flexible languages.
Survey Paper, dataset in face and github. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 75k + ml subreddit.
🚨 MarktechPost is shouting for companies / initializing / groups to cooperate with the coming magazines of AI the following 'Source Ai in production' and 'and' Agentic Ai '.
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel
 Method That Reduces Doom Loops in Consulting Models")

 Open Model with 21B Functional Parameters and 256K Content")
