Intel Labs checked low-level adapter and neural Architecture Search for the LLM Comtresse

Major language models (llms) have been severely removed from various remedies to correct environmentalism, including machine interpretation, text summarizing, and AI. However, their increasing stubit and size has led to the efficiency of the ability and challenges to use memory. As these models grow, needs need to be difficult to move in areas with limited associated associated skills.
The main obstacle and llms are lying in their large processes. Training and recreation These models include billions of parameters, making them use resources and reduce their access. The events available to improve efficiency, such as the good layout of parameter (PEFT), provide reliably but often compromise. The challenge is to find the way that can reduce the computational requirements while storing the accuracy of the model and efficiency of the world's actual circumstances. Investigators have been examining the methods that allow effective active planning without needing large computer resources.
Intel Labs and Intel Corporation presented the path that combines low strategies (Lora) with neural Architecure Search (NAS). This approach requires addressing the limits of the traditional rescue while developing efficiency and performance. Research Group creates a framework that uses the use of memory and computational speeds according to lower submission. This approach includes a super-sharing network of weight agreement that suits the capacity to enhance training. This combined one lets the model be well organized while keeping footprint of a small computer.
The Intel Labs method is focused on LasAs (low-quality construction facilities), which use elastic lora adapt of a beautiful model. Unlike the common ways that require full-complete LLMS editing, Lones enables the selected performance of items used for models, reduce the decline. Basic establishment lies in the conversion of high adapters, synchronically synchronized in the model needs. This method is supported by the Heuistic network searches that continue to broadcast a good order process. With focus on appropriate parameters, the process reaches the balance between computer and operating operations. This process is organized to allow selected performance for low-quality structures while maintaining the maximum speed of infance.
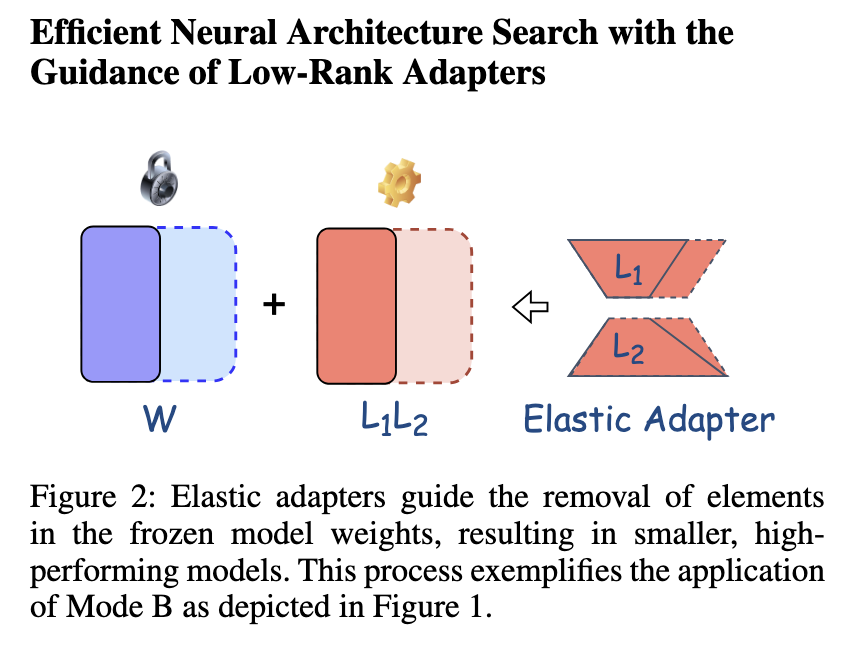
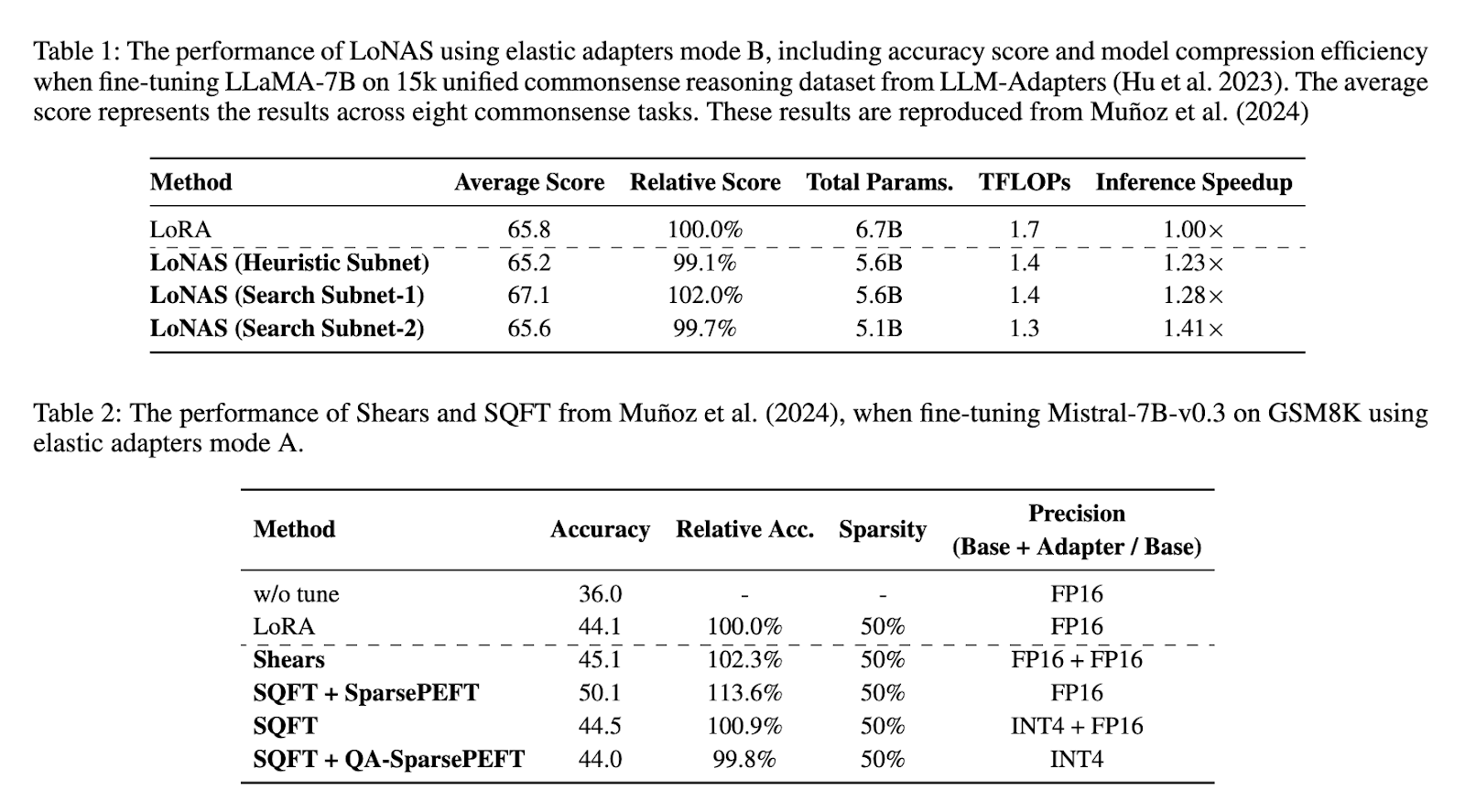
The functional assessment of the proposed methodology highlights its important improvement in standard strategies. The test results indicate that the LON has faster access to 1.4x while reducing model parameters about 80%. When used in LLAMA-7B ready for 15K unified 15k database, bones indicated a limited number of 65.8%. The Different Accumulative of the Different List of Latas indicated that the performance of the Heuristic subnet has been obtained by the speed of 1.23x, while the Subnet suspension is allowed for 1.28x and 1.41x speed. In addition, using Bone-V0-V0.3 In GSM8K activities increases the accuracy of 44.1% to 50.1%, to keep efficiency in all different model sizes. These findings ensure that the proposed methodology is very enhancing the performance of llms while reducing computer needs.
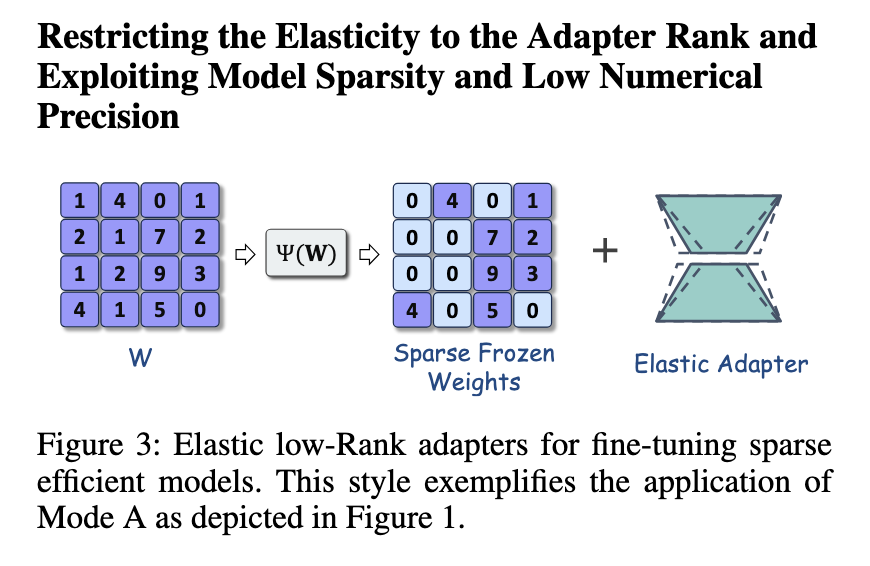
Excessive framework involves the introduction of Sheers, an advanced manner of regulatory control in a lones. The Shears uses the lower neural search of the option is working from time to the basic model using specified metrics, to ensure that good planning remains effective. This strategy is especially effective in keeping the model accuracy while reducing the number of active parameters. Another extension, SQFT, includes the sparsity and lower rates of prices for improved humorous material. Valuation techniques are used, SQFT confirms that organized models may arrange without losing efficiency. This reflection highlights the contexts of the lones and its opportunity to repeat.
Consolidation Lora Namasa provides a changing way to the damaging language. By filing the lowly low-based submissions, the study shows that computational achievement can be highly developed without compromising performance. The Intel Labs confirms that combining these strategies reduces the burden of good order while guaranteed the integrity of the model. Future research can check out additional performance, including improved network selection and the best Herusic strategies. This method sets an example of easily accessible to llms and is used in different locations, expressing a well-effective way of AI.
Survey Page and GitHub paper. All credit for this study goes to research for this project. Also, don't forget to follow Sane and join ours Telegraph station including LinkedIn Grtopic. Don't forget to join ours 70k + ml subreddit.
🚨 Meet the Work: an open source opened with multiple sources to check the difficult program AI (Updated)
Nikhil is a student of students in MarktechPost. Pursuing integrated graduates combined in the Indian Institute of Technology, Kharagpur. Nikhl is a UI / ML enthusiasm that searches for applications such as biomoutomostoments and biomedical science. After a solid in the Material Science, he examines new development and developing opportunities to contribute.
✅ [Recommended] Join Our Telegraph Channel



