This AI Paper introduces IXC-2.5 reward: Rewarding model of many alignment and effective LVLM performance

The tact of activities is very grown through the integration of the vision and language, allowing systems to interpret and generate information in many data ways. This skill promotes applications such as processing environment, computer-sensitive communication language, and person's computer interactions by easy to process the text, visual, and video. However, the challenges still exist in ensuring that such systems provide accurate, frick, and aligned, especially as the models have many complex.
The main difficulty in the construction of large models of the vision to achieve the results produced by people accompanied by human preferences. Many systems exist due to the production of reflected answers and non-compliance between many methods, as well as their dependence on the functions of the app. In addition, such high quality sets are smaller and varied from different types and functions such as mathematical thinking, analyzing the video, or following instructions. LVLMs cannot bring the decrease necessary in real-land operating systems without appropriate alignment measures.
The current solutions of these challenges are usually limited to only in the text prize or products that produce a small amount. Such models usually rely on the species or owners of patent, unstable and indirectly. In addition, current methods are limited to dry data sets and instructions described in advance that is unable to capture all real landfall differences. This results in a big gap between the power to improve complete rewards that can successfully direct LVLMs.
Researchers from Shanghai Artifics Laborantory, the Chinese Jiaa Tong University, Naning University, and Nanyang Technological University presented InternLM-XComposer (IXC-2.5-Rewards The model is an important step in improving the rewards of multiple kinds, provides a strong framework for adapting LVLM and popular preferences. Unlike other solutions, IXC-2.5-REWARD can process different forms, including text, pictures, and videos, and has the ability to do well in various apps. This method is the main development of current tools, considering lack of domain supply and scalabilities.
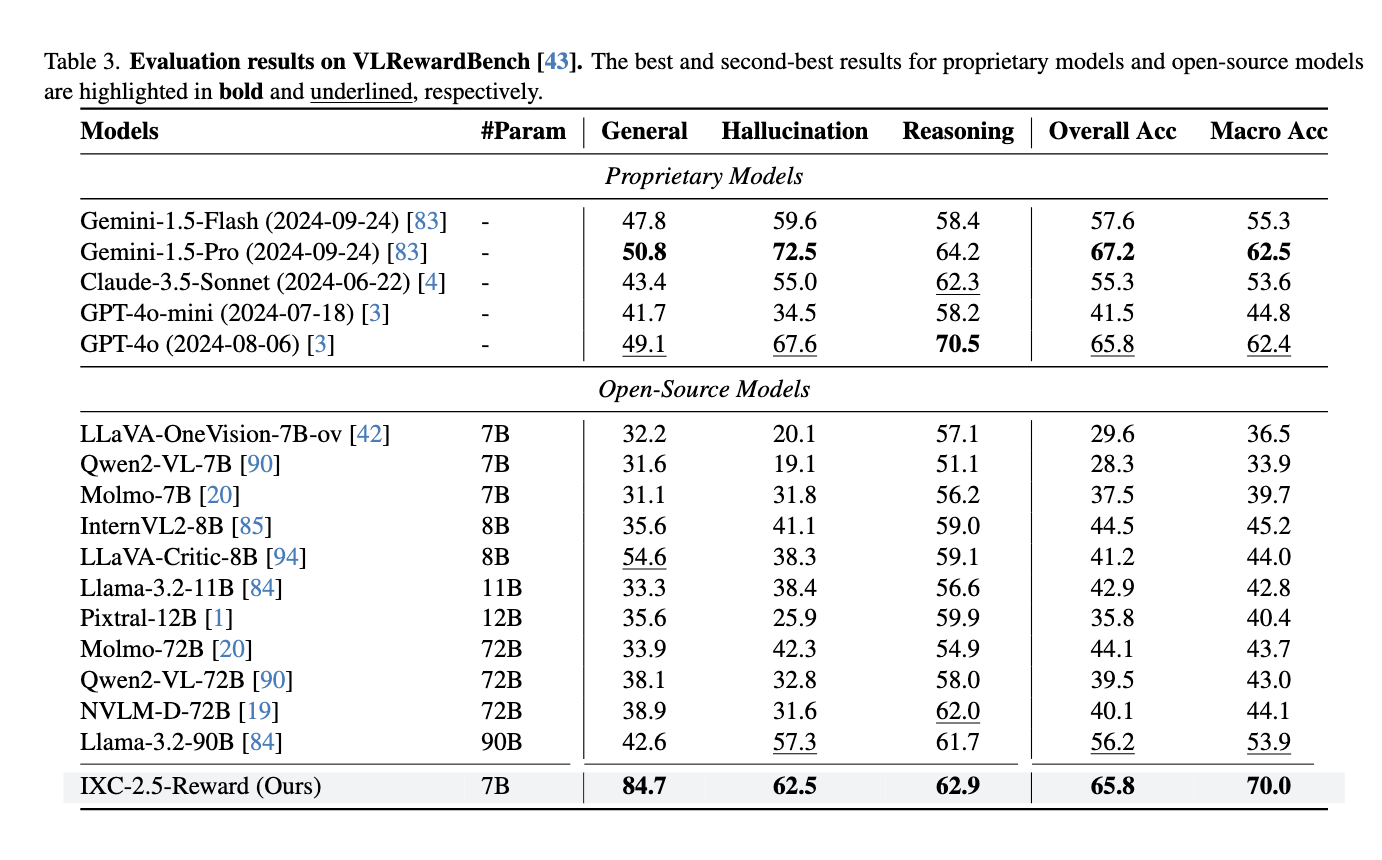
According to a particular research, IXC-2.5-REWARD was designed with extensive preferences and includes variety of backgrounds such as documents, common assumptions, and video comprehension. The model has a head for the points that foretell rewards points in the instructions provided and answers. The team has used effective learning algoriths such as the Proximal Policy Optimization (PPO) to train the chat model, IXC-2.5-2.5 – to provide high quality responses, aligned by the person. Training was in line with open and recently collected data, which ensures comprehensive use. In addition, the model is not afflicted by the common sneakers of lengths as it uses obstacles to the rest of the answers to ensure quality and summarizing.
The operation of IXC-2.5-REWARDS sets a new Bechamaker to AI with many situations. In VL-Rewardbench, the model has received the accuracy of all 200.0%, high-quality models such as Gemini-1.5-Pro (62.5% (62.4%). The program also produced competitive effects on the text of the text only, receiving 88.6% on REWARD-BENCH and 68.8% in RM-Bench. These results show that the model can save strong-language processing energy even if you do very well in multi-modal activities, and additionally, Ixc-2.5-Chat's chat model. Many, confirm the operation of a reward model in real world conditions.
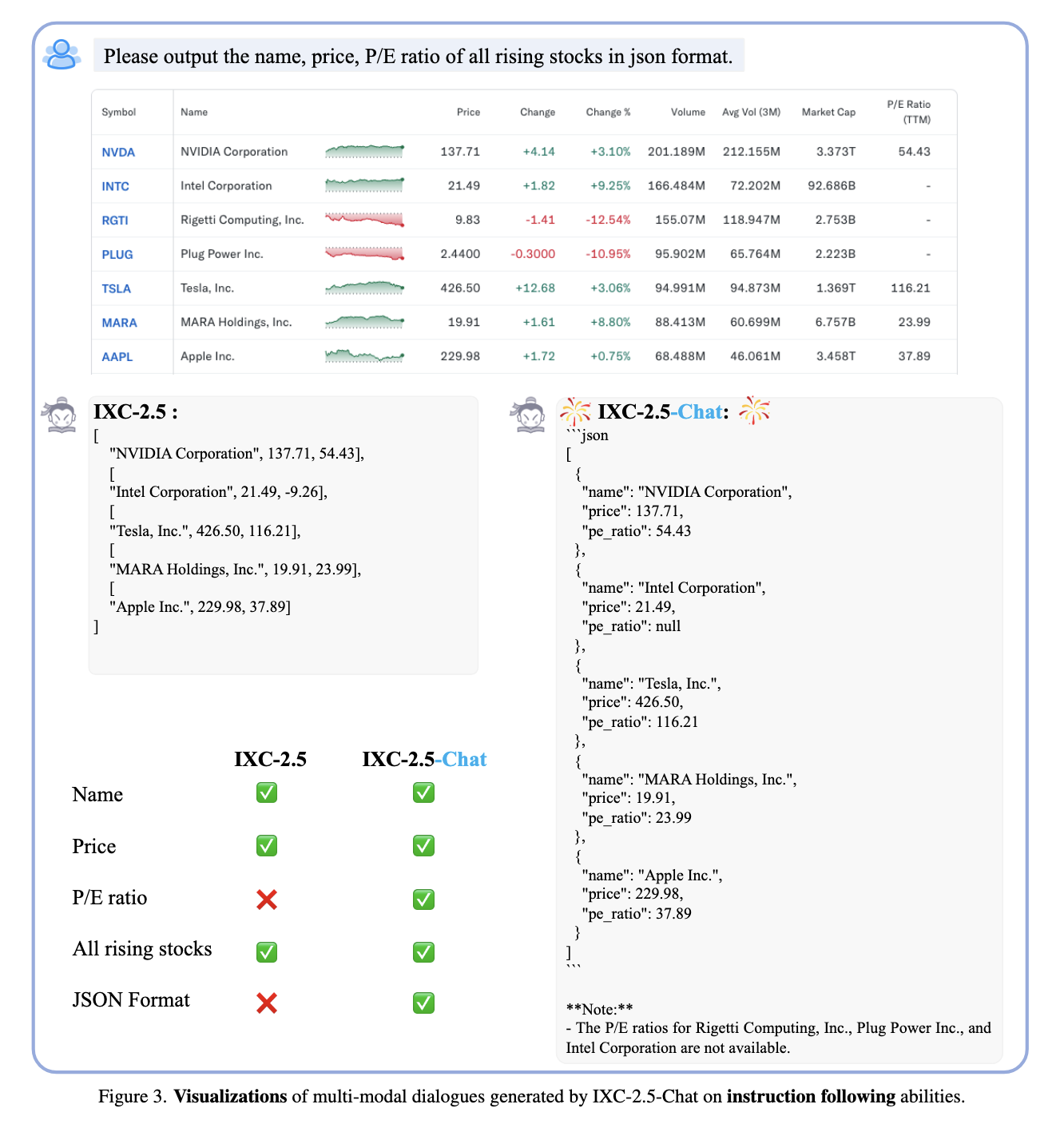
Researchers also show three IXC-2.5-REAWARD applications that emphasize its variations. First, it works as a monitored learning signal, which allows policy development strategies such as PPO to train models successfully. Second, the Model testing ability allowed good answers from many candidates to be chosen, which further advancels to improve performance. Finally, the IXC-2.5-REWARD is essential for the data and find sound or problematic samples in data sets, are filtered from training data, so, improving the quality of LVLM training data.
This work is to jump a great further prizes in many situations and closes critical spaces about size, fluctuations, and alignment and likeness. The authors have found a basis for additional success in this field through various data sets and use of high-quality learning strategies. The IXC-2.5-REWARD is set to turn AI systems with multiple situations and bring effective and efficiency in real ecosystems.
Survey Paper and Gitity. All the credit of this study goes to this work. Also, don't forget to follow Twitter and join our The phone station besides LinkedIn Grup. Don't forget to join our 70k + ml subreddit.
🚨 [Recommended Read] Nebius Ai Studio Excludes models of vision, new language models, embedded and lora (Has been raised)
Nikhil is an internshipant in MarkteachPost. He pursues two integrated grades of the Indian Institute of Technology, Kharagpur. Nikhil is ai / ML lover who resides researching programs in the fields such as biomaterials and biomedical science. As a solid resource in the material Science, he examines new development and creates opportunities to contribute.
📄 Meet 'Height': The administrative process for a private project (sponsored)



