
Understanding long videos, such as 24-hour CCTV footage or full-length films, is a major challenge in video processing. Major Language Models (LLMs) they have shown great potential in handling multimodal data, including videos, but struggle with large data and high processing requirements for long content. Many existing methods for managing long videos lose important information, as simplifying the visual content often removes subtle but important information. This limits the ability to effectively interpret and analyze complex or dynamic video data.
Techniques currently used to understand long videos include extracting key frames or converting video frames to text. These methods make it easier to process but lead to a great loss of information as subtle details and visual nuances are removed. Advanced video LLMs, such as Video-LLaMA and Video-LLaVA, attempt to improve understanding using multimodal presentations and specialized modules. However, these models require a lot of computational resources, are task-specific, and struggle with long or irregular videos. Multimodal RAG systems, such as iRAG and LlamaIndex, improve data acquisition and processing but lose valuable information when converting video data to text. These limitations prevent current methods from fully capturing and exploiting the depth and complexity of video content.
To address the challenges of video understanding, researchers from Om AI research again Binjiang Institute of Zhejiang University was introduced Agentstwo-step method: Video2RAG for pre-processing and DnC Loop for processing. In Video2RAG, raw video data is captured by scene, visual information, and audio transcription to create a summary of a scene's captions. These captions are entered into the machine and stored in a database enriched with additional information about the time, place, and details of the event. In this way, the process avoids the input of large contexts in language models, thus, problems such as token overload and conceptual complexity. To perform the task, questions are coded, and these video segments are retrieved for further analysis. This ensures efficient video understanding by balancing detailed data representation and computational feasibility.
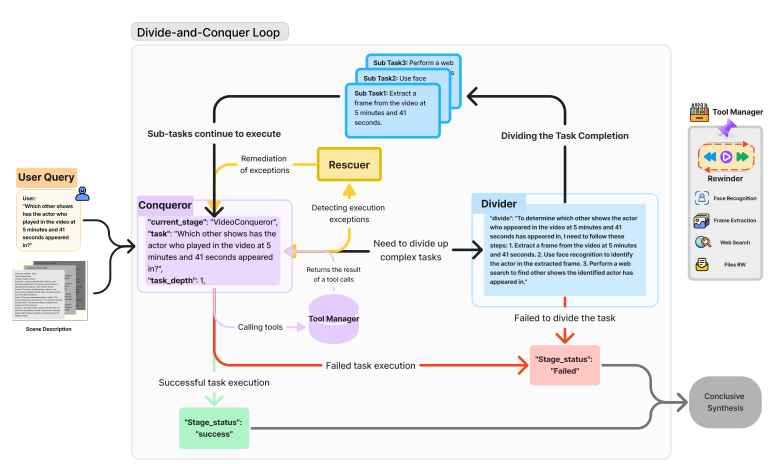
The DNC Loop uses a divide-and-conquer strategy, iteratively breaking down tasks into manageable subtasks. The Conquest module checks functions, directs isolation, tool manipulation, or direct maintenance. The Divider module divides complex functions, and the Sorter deals with fatal errors. Iterative task tree structure helps in efficient management and resolution of tasks. The combination of pre-processing programmed by Video2RAG and the robust framework of DnC Loop enables OmAgent to deliver a complete video understanding system that can handle complex queries and generate accurate results.
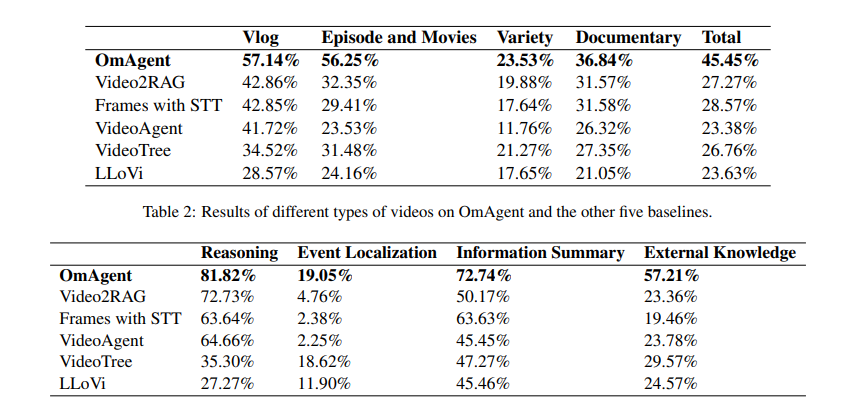
The researchers conducted tests to verify OmAgent's ability to solve complex problems and understand long-form videos. They used two benchmarks, MBPP (976 Python functions) and FreshQA (dynamic real-world Q&A), to test general problem solving, focusing on planning, task execution, and tool usage. They designed a benchmark with over 2000 Q&A pairs for video understanding based on various long videos, hypothesis testing, event localization, information summarization, and external knowledge. OmAgent consistently underperforms across all metrics. For MBPP and FreshQA, OmAgent scored 88.3% and 79.7%, respectively, outperforming GPT-4 and XAgent. OmAgent received 45.45% overall video activity compared to Video2RAG (27.27%), frames with STT (28.57%), and other bases. Succeeded in reasoning (81.82%) and summary of information (72.74%) but struggled to localize events (19.05%). OmAgent's Divide-and-Conquer (DnC) loop and feedback capabilities greatly improved performance in tasks requiring detailed analysis, but accuracy in event localization remained a challenge.
In short, what is proposed Agents combines a multimodal RAG with a general AI framework, which enables advanced video understanding with almost infinite cognitive power, a secondary memory mechanism, and a tool-independent application. It has achieved strong performance in many benchmarks. Although challenges such as event positioning, character alignment, and audio-visual compatibility remain, this approach can serve as a foundation for future research to improve character dissonance, audio-visual synchronization, and the understanding of non-verbal audio cues, to improve understanding of long-form video.
Check it out i Paper again GitHub page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 Recommend Open Source Platform: Parlant is a framework that is changing the way AI agents make decisions in customer-facing situations. (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these advanced technologies in the agricultural domain and solve challenges.
📄 Meet 'Height': The only standalone project management tool (Sponsored)


 ye-Cross-Embodiment Robot Manipulation")