The SQL is one of the key languages that are widely used in all businesses, and requires understanding of information and the Table Metadata. This can be difficult for nonxochnical users who do not have professional in SQL. Today, the productive AI can help in a bridge of information gap for nonechnical users to produce SQL queries through the Topt-to-SQL system. This app allows users to ask questions in the environment and produce the SQL question of the user request.
Large models of language (llms) are trained to produce accurate SQL questions to obtain natural language instructions. However, Off-The-Sheff llMS cannot be used without any changes. First, llms do not have access to business information, and models need customization to understand a specific business database. In addition, difficulty increases due to the existence of column symbols and internal metrics available.
Restriction of the LLMS in understanding of the business information and the person's context may be considered using the generation of land reform (RAG). In this sentence, we check using Amazon Bedrock to create the Text-to-SQL app using the RAG. We use Sonthropic's Clause 3.5 SonNet model to generate SQL questions, Amazon Titan in Amazon Bedrock Text Income and Amazon Bedrock to access these models.
Amazon Bedrock is a fully owned service that gives the selection of the most effective Femal Modes (FMS).
Looking for everything
This solution is based on the following services:
- Basic model – We use anthropic's Claude 3.5 Sonnet in Amazon Bedrock as our LLM to generate SQL user questions.
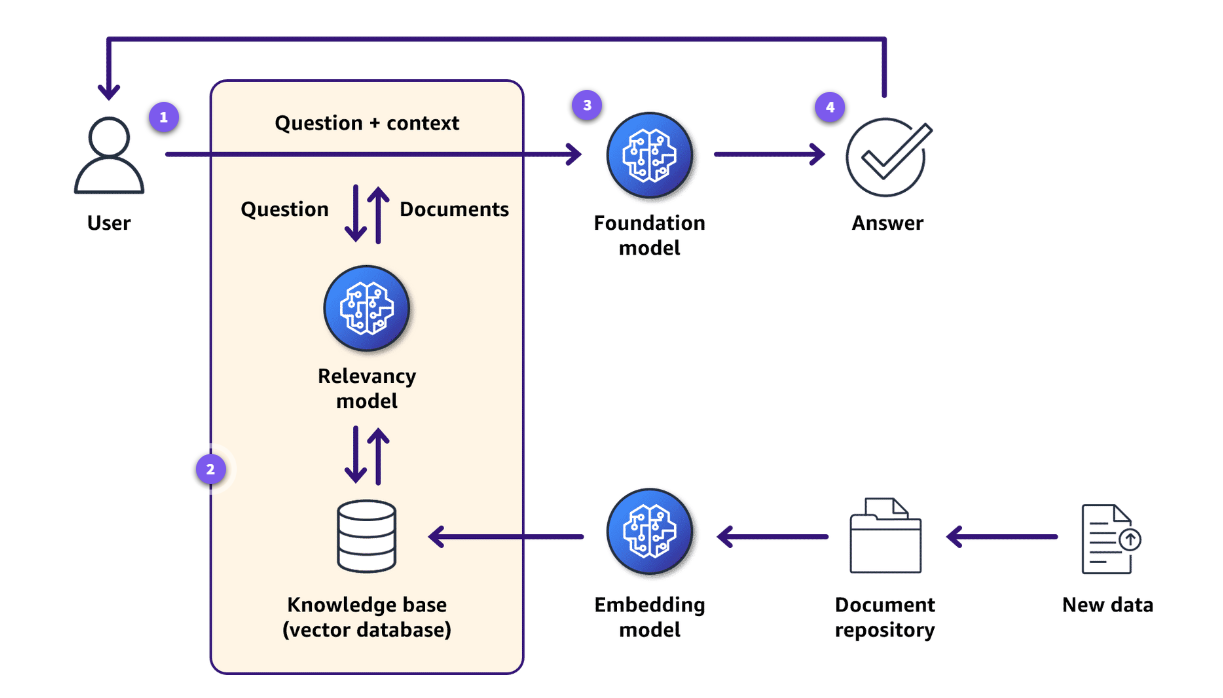
- The support of the vectors – We use Amazon Titan Scripture at Shuddings v2 in Amazon Bedrock to embeddlers. Empowerment is the procedure, photos, and sound offered numbers of numbers in the veter. The embassy is usually made of machine study model (ML). The next drawing provides a lot of details about embupil.
- Rag – We use the RAG for additional citizen about Telt Schema, column symbomms, sample questions in FM. The RAG is a framework for building AI products that can use business data and vector details overcome information limitations. RAG works using retaliation module to receive the relevant information from the external data store for the immediate user reply. This data obtained is used as context, combined with original trespan, to create quickly expanded transferred to the LLM. The language model then issued a SQL question that included business information. The next drawing shows the rag frame.
- Support – This open Python library enables you to understand and share good ML and Data Science programs. Just a few minutes You can create powerful data apps using the Python only.
The following drawing shows the formation of a solution.
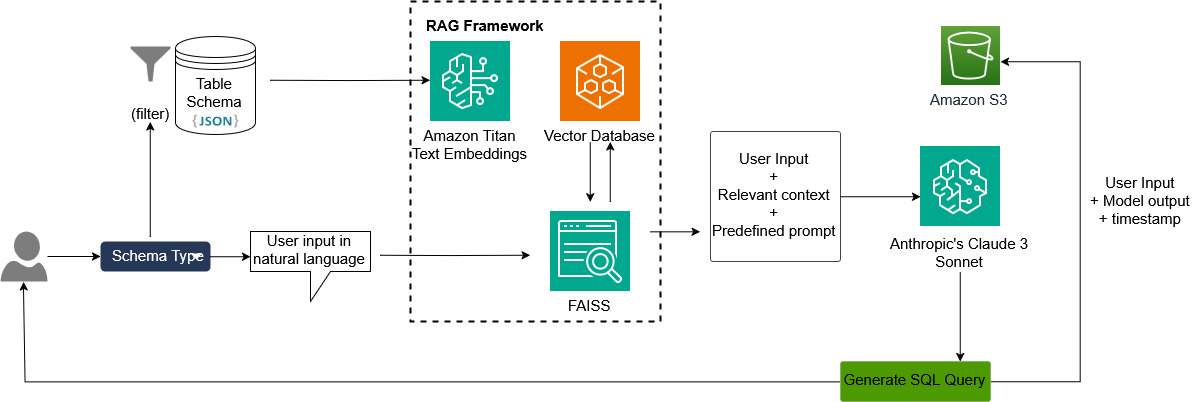
We need to update the llms with a special business database. This is sure that the model can understand data information and produce an answer designed for schema and table based on business. There are many files for the file available to store this information, such as JSON, PDF, TXT, and yaml. In our case, we create JSON files to keep a table schema, the descriptions of the table, columns contain symptoms of mind, and the sample questions. The programs listed by JSON allows the clear and formal representation of the complex information such as tables Schems, column descriptions, and sample questions. This structure helps rapid disturbing and deception data in many planning languages, reducing the need for normal awakening.
There may be many tables similar to the same information, which can reduce the accuracy of the model. Increasing accuracy, we divided tables in four different types based on schema and created four Files at JSON to keep different tables. Add one drop menu by four choices. Each choices represent one of these four categories and be included in JSON's files per person. After the user selects a value from the drop menu, the correct JSON file is transferred to Amazon Titan text V2, which can convert the text into embeddate. This embedding is kept in the vector database of return quickly.
We have added a speedy template to FM to explain the roles and responsibilities of the model. You can add further information such as the SQL engine should be used to generate SQL questions.
When the user provides chat propt, we use the same search to find the appropriate table metadata from the Vector data for the user question. User installation included with the appropriate table metadata and a speedy template, transferred to FM as one installation of everything together. FM produces a SQL question based on the final installation.
To explore the accuracy of model and track the method, we store all the installation information and output from Amazon Storage Service (Amazon S3).
Requirements
To create this solution, complete the following requirements:
- Sign up for AWS account if you don't do one.
- Enable access to the Amazon Titan model Terrified text V2 and Anthropic's Claude 3.5 Sonnet 3.5 Sonnet in Amazon Bedrock.
- Create S3 As' Syplesql-logs-*.', Restore'*.'For your unique identifier. Bicycles worldwide throughout Amazon S3 Service.
- Select your checkpoint. We recommend that you check at Amazon Sagemaker Studio, although you can use other local locations.
- Enter the following libraries to make code:
pip install streamlit
pip install jq
pip install openpyxl
pip install "faiss-cpu"
pip install langchain
Method of doing things
There are three main elements in this solution:
- JSON Files Keep a table schema and prepare for the llm
- Vector Indicator using Amazon Bedrock
- The direction of the urban
You can download all three things and snippets of the code provided in the following section.
Produce a table schema
We use JSON's format to keep the table gramma. Providing more in model, added the table and its description, columns and its symbols, and sample questions to our JSON files. Create JSON file such as Table_Schema_a.json by imitating the following code:
{
"tables": [
{
"separator": "table_1",
"name": "schema_a.orders",
"schema": "CREATE TABLE schema_a.orders (order_id character varying(200), order_date timestamp without time zone, customer_id numeric(38,0), order_status character varying(200), item_id character varying(200) );",
"description": "This table stores information about orders placed by customers.",
"columns": [
{
"name": "order_id",
"description": "unique identifier for orders.",
"synonyms": ["order id"]
},
{
"name": "order_date",
"description": "timestamp when the order was placed",
"synonyms": ["order time", "order day"]
},
{
"name": "customer_id",
"description": "Id of the customer associated with the order",
"synonyms": ["customer id", "userid"]
},
{
"name": "order_status",
"description": "current status of the order, sample values are: shipped, delivered, cancelled",
"synonyms": ["order status"]
},
{
"name": "item_id",
"description": "item associated with the order",
"synonyms": ["item id"]
}
],
"sample_queries": [
{
"query": "select count(order_id) as total_orders from schema_a.orders where customer_id = '9782226' and order_status="cancelled"",
"user_input": "Count of orders cancelled by customer id: 978226"
}
]
},
{
"separator": "table_2",
"name": "schema_a.customers",
"schema": "CREATE TABLE schema_a.customers (customer_id numeric(38,0), customer_name character varying(200), registration_date timestamp without time zone, country character varying(200) );",
"description": "This table stores the details of customers.",
"columns": [
{
"name": "customer_id",
"description": "Id of the customer, unique identifier for customers",
"synonyms": ["customer id"]
},
{
"name": "customer_name",
"description": "name of the customer",
"synonyms": ["name"]
},
{
"name": "registration_date",
"description": "registration timestamp when customer registered",
"synonyms": ["sign up time", "registration time"]
},
{
"name": "country",
"description": "customer's original country",
"synonyms": ["location", "customer's region"]
}
],
"sample_queries": [
{
"query": "select count(customer_id) as total_customers from schema_a.customers where country = 'India' and to_char(registration_date, 'YYYY') = '2024'",
"user_input": "The number of customers registered from India in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id where c.customer_name="john" and to_char(o.order_date, 'YYYY-MM') = '2024-01'",
"user_input": "Total orders placed in January 2024 by customer name john"
}
]
},
{
"separator": "table_3",
"name": "schema_a.items",
"schema": "CREATE TABLE schema_a.items (item_id character varying(200), item_name character varying(200), listing_date timestamp without time zone );",
"description": "This table stores the complete details of items listed in the catalog.",
"columns": [
{
"name": "item_id",
"description": "Id of the item, unique identifier for items",
"synonyms": ["item id"]
},
{
"name": "item_name",
"description": "name of the item",
"synonyms": ["name"]
},
{
"name": "listing_date",
"description": "listing timestamp when the item was registered",
"synonyms": ["listing time", "registration time"]
}
],
"sample_queries": [
{
"query": "select count(item_id) as total_items from schema_a.items where to_char(listing_date, 'YYYY') = '2024'",
"user_input": "how many items are listed in 2024"
},
{
"query": "select count(o.order_id) as order_count from schema_a.orders o join schema_a.customers c on o.customer_id = c.customer_id join schema_a.items i on o.item_id = i.item_id where c.customer_name="john" and i.item_name="iphone"",
"user_input": "how many orders are placed for item 'iphone' by customer name john"
}
]
}
]
}
Prepare the LLM and initiate the Vector Indicator using Amazon Bedrock
Create a Python file as a library .py by following these steps:
- Enter the following import statements to add the required libraries:
import boto3 # AWS SDK for Python
from langchain_community.document_loaders import JSONLoader # Utility to load JSON files
from langchain.llms import Bedrock # Large Language Model (LLM) from Anthropic
from langchain_community.chat_models import BedrockChat # Chat interface for Bedrock LLM
from langchain.embeddings import BedrockEmbeddings # Embeddings for Titan model
from langchain.memory import ConversationBufferWindowMemory # Memory to store chat conversations
from langchain.indexes import VectorstoreIndexCreator # Create vector indexes
from langchain.vectorstores import FAISS # Vector store using FAISS library
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text into chunks
from langchain.chains import ConversationalRetrievalChain # Conversational retrieval chain
from langchain.callbacks.manager import CallbackManager
- Start the Amazon Bedrock Client and prepare anTropic's Clause 3.5 You can limit the number of output tokens to make costs:
# Create a Boto3 client for Bedrock Runtime
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
# Function to get the LLM (Large Language Model)
def get_llm():
model_kwargs = { # Configuration for Anthropic model
"max_tokens": 512, # Maximum number of tokens to generate
"temperature": 0.2, # Sampling temperature for controlling randomness
"top_k": 250, # Consider the top k tokens for sampling
"top_p": 1, # Consider the top p probability tokens for sampling
"stop_sequences": ["nnHuman:"] # Stop sequence for generation
}
# Create a callback manager with a default callback handler
callback_manager = CallbackManager([])
llm = BedrockChat(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0", # Set the foundation model
model_kwargs=model_kwargs, # Pass the configuration to the model
callback_manager=callback_manager
)
return llm
- Create and replace the grammatical indicator provided. This method is an effective way to filter tables and give appropriate input to model:
# Function to load the schema file based on the schema type
def load_schema_file(schema_type):
if schema_type == 'Schema_Type_A':
schema_file = "Table_Schema_A.json" # Path to Schema Type A
elif schema_type == 'Schema_Type_B':
schema_file = "Table_Schema_B.json" # Path to Schema Type B
elif schema_type == 'Schema_Type_C':
schema_file = "Table_Schema_C.json" # Path to Schema Type C
return schema_file
# Function to get the vector index for the given schema type
def get_index(schema_type):
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0",
client=bedrock_runtime) # Initialize embeddings
db_schema_loader = JSONLoader(
file_path=load_schema_file(schema_type), # Load the schema file
# file_path="Table_Schema_RP.json", # Uncomment to use a different file
jq_schema=".", # Select the entire JSON content
text_content=False) # Treat the content as text
db_schema_text_splitter = RecursiveCharacterTextSplitter( # Create a text splitter
separators=["separator"], # Split chunks at the "separator" string
chunk_size=10000, # Divide into 10,000-character chunks
chunk_overlap=100 # Allow 100 characters to overlap with previous chunk
)
db_schema_index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS, # Use FAISS vector store
embedding=embeddings, # Use the initialized embeddings
text_splitter=db_schema_text_splitter # Use the text splitter
)
db_index_from_loader = db_schema_index_creator.from_loaders([db_schema_loader]) # Create index from loader
return db_index_from_loader
- Use the next task to create and restore the memory of the chat.
# Function to get the memory for storing chat conversations
def get_memory():
memory = ConversationBufferWindowMemory(memory_key="chat_history", return_messages=True) # Create memory
return memory
- Use the following template following to generate SQL queries based on user installation:
# Template for the question prompt
template = """ Read table information from the context. Each table contains the following information:
- Name: The name of the table
- Description: A brief description of the table
- Columns: The columns of the table, listed under the 'columns' key. Each column contains:
- Name: The name of the column
- Description: A brief description of the column
- Type: The data type of the column
- Synonyms: Optional synonyms for the column name
- Sample Queries: Optional sample queries for the table, listed under the 'sample_data' key
Given this structure, Your task is to provide the SQL query using Amazon Redshift syntax that would retrieve the data for following question. The produced query should be functional, efficient, and adhere to best practices in SQL query optimization.
Question: {}
"""
- Use the following task to get feedback from RAG chat model:
# Function to get the response from the conversational retrieval chain
def get_rag_chat_response(input_text, memory, index):
llm = get_llm() # Get the LLM
conversation_with_retrieval = ConversationalRetrievalChain.from_llm(
llm, index.vectorstore.as_retriever(), memory=memory, verbose=True) # Create conversational retrieval chain
chat_response = conversation_with_retrieval.invoke({"question": template.format(input_text)}) # Invoke the chain
return chat_response['answer'] # Return the answer
Prepare the direction of the former UI
Create a file app .Pay according to these steps:
- Import information libraries:
import streamlit as st
import library as lib
from io import StringIO
import boto3
from datetime import datetime
import csv
import pandas as pd
from io import BytesIO
- Start S3 Client:
s3_client = boto3.client('s3')
bucket_name="simplesql-logs-****"
#replace the 'simplesql-logs-****’ with your S3 bucket name
log_file_key = 'logs.xlsx'
- Configure UI Guide:
st.set_page_config(page_title="Your App Name")
st.title("Your App Name")
# Define the available menu items for the sidebar
menu_items = ["Home", "How To", "Generate SQL Query"]
# Create a sidebar menu using radio buttons
selected_menu_item = st.sidebar.radio("Menu", menu_items)
# Home page content
if selected_menu_item == "Home":
# Display introductory information about the application
st.write("This application allows you to generate SQL queries from natural language input.")
st.write("")
st.write("**Get Started** by selecting the button Generate SQL Query !")
st.write("")
st.write("")
st.write("**Disclaimer :**")
st.write("- Model's response depends on user's input (prompt). Please visit How-to section for writing efficient prompts.")
# How-to page content
elif selected_menu_item == "How To":
# Provide guidance on how to use the application effectively
st.write("The model's output completely depends on the natural language input. Below are some examples which you can keep in mind while asking the questions.")
st.write("")
st.write("")
st.write("")
st.write("")
st.write("**Case 1 :**")
st.write("- **Bad Input :** Cancelled orders")
st.write("- **Good Input :** Write a query to extract the cancelled order count for the items which were listed this year")
st.write("- It is always recommended to add required attributes, filters in your prompt.")
st.write("**Case 2 :**")
st.write("- **Bad Input :** I am working on XYZ project. I am creating a new metric and need the sales data. Can you provide me the sales at country level for 2023 ?")
st.write("- **Good Input :** Write an query to extract sales at country level for orders placed in 2023 ")
st.write("- Every input is processed as tokens. Do not provide un-necessary details as there is a cost associated with every token processed. Provide inputs only relevant to your query requirement.")
- Produce a question:
# SQL-AI page content
elif selected_menu_item == "Generate SQL Query":
# Define the available schema types for selection
schema_types = ["Schema_Type_A", "Schema_Type_B", "Schema_Type_C"]
schema_type = st.sidebar.selectbox("Select Schema Type", schema_types)
- Use the following SQL generation:
if schema_type:
# Initialize or retrieve conversation memory from session state
if 'memory' not in st.session_state:
st.session_state.memory = lib.get_memory()
# Initialize or retrieve chat history from session state
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
# Initialize or update vector index based on selected schema type
if 'vector_index' not in st.session_state or 'current_schema' not in st.session_state or st.session_state.current_schema != schema_type:
with st.spinner("Indexing document..."):
# Create a new index for the selected schema type
st.session_state.vector_index = lib.get_index(schema_type)
# Update the current schema in session state
st.session_state.current_schema = schema_type
# Display the chat history
for message in st.session_state.chat_history:
with st.chat_message(message["role"]):
st.markdown(message["text"])
# Get user input through the chat interface, set the max limit to control the input tokens.
input_text = st.chat_input("Chat with your bot here", max_chars=100)
if input_text:
# Display user input in the chat interface
with st.chat_message("user"):
st.markdown(input_text)
# Add user input to the chat history
st.session_state.chat_history.append({"role": "user", "text": input_text})
# Generate chatbot response using the RAG model
chat_response = lib.get_rag_chat_response(
input_text=input_text,
memory=st.session_state.memory,
index=st.session_state.vector_index
)
# Display chatbot response in the chat interface
with st.chat_message("assistant"):
st.markdown(chat_response)
# Add chatbot response to the chat history
st.session_state.chat_history.append({"role": "assistant", "text": chat_response})
- Log in dialogues in S3 bucket:
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
try:
# Attempt to download the existing log file from S3
log_file_obj = s3_client.get_object(Bucket=bucket_name, Key=log_file_key)
log_file_content = log_file_obj['Body'].read()
df = pd.read_excel(BytesIO(log_file_content))
except s3_client.exceptions.NoSuchKey:
# If the log file doesn't exist, create a new DataFrame
df = pd.DataFrame(columns=["User Input", "Model Output", "Timestamp", "Schema Type"])
# Create a new row with the current conversation data
new_row = pd.DataFrame({
"User Input": [input_text],
"Model Output": [chat_response],
"Timestamp": [timestamp],
"Schema Type": [schema_type]
})
# Append the new row to the existing DataFrame
df = pd.concat([df, new_row], ignore_index=True)
# Prepare the updated DataFrame for S3 upload
output = BytesIO()
df.to_excel(output, index=False)
output.seek(0)
# Upload the updated log file to S3
s3_client.put_object(Body=output.getvalue(), Bucket=bucket_name, Key=log_file_key)
Check the solution
Open your terminal and urges the following command to use the streaming system.
streamlit run app.py
To visit the app using your browser, navigation in the localhost.
Visiting the program using Sagemaker, Copy your Notebook URL and replace 'Default / Lab' in the URL with 'Automatic / representative / 8501 /' . You have to look like the following:
Designate Produce a SQL question to open the dialog window. Check your app by asking questions in the environment. We have tested the app for the following questions and produced accurate SQL questions.
Counting of orders placed from India last month?
Write the question that will issue a canceled order of the list of lists this year.
Write a question to issue the top 10 objects with the highest order each country.
Tips for solving problems
Use the following solutions to deal with errors:
Error – Error raised in the NEPOCTET file means an error occurring (AccessEedException. You don't have access to model with a specified model ID.
Solution – Make sure you have access to FMS Bedrock, Amazon Titan Text embed V2, and anthropic's Claude 3.5 Sonnet 3.5 Sonnet.
Error – app.py is not easy
Solution – Make sure your JSON file and python files are the same folder and arouse the command to the same folder.
Error – No module named streamlit
Solution – Unlock Terminal and add a broadcast module by using the command pip install streamlit
Error – An error error has appeared not.
Solution – Verify your bucket name in the App.py file and update the word based on your S3 name.
Clean
Clean your resources to avoid installing costs. Cleaning your S3 bucket, heading in a bucket.
Store
In this post, show how Amazon Bedrock can be used to create the Text-to-SQL app based on special business datasets. We have used Amazon S3 to keep the results generated by a corresponding installer model. These logs can be used to explore accuracy and improve context by providing further information on the basis of information. With a tool for such tools, you can create default solutions to networking users, and give them energy to successfully associate with data.
Ready to start with Amazon Bedrock? Start learning about these practical worksheets.
For more information on SQL generation, see these posts:
We have recently introduced the NL2SQL module with a formal data in Amazon Bedrock Information. To learn more, visit Amazon Bedrock Informal Base Now supports the recovery data.
About the writer
 Rajendra Churchhary by a SR business commentator. in Amazon. At 7 years of experience in creating data solutions, he has a great technology in the data recognition, data modulation, and data engineering. You are passionate about supporting customers by installing AI solutions. Outside work, Rajendra is an Apid Fodedie Liver and Music music, and she enjoys swimming and walking.
Rajendra Churchhary by a SR business commentator. in Amazon. At 7 years of experience in creating data solutions, he has a great technology in the data recognition, data modulation, and data engineering. You are passionate about supporting customers by installing AI solutions. Outside work, Rajendra is an Apid Fodedie Liver and Music music, and she enjoys swimming and walking.
")



