Anthropic AI Blooms: An Open Agentic Framework for Automated Behavioral Assessment of Frontier AI Models

Anthropic has released Bloom, an open source agent framework that automates the behavioral evaluation of AI models of parameters. The system takes the researcher's specified behavior and constructs a guided test that measures how often and how strongly that behavior occurs in real-world situations.
Why Bloom?
Safety behavior tests and alignment are expensive to design and maintain. Teams must provide creative situations, conduct multiple interactions, read long transcripts and compile scores. As models evolve, old benchmarks can become outdated or leak from training data. Anthropic's research team poses this as a measurement problem, they need a way to generate new non-specific behavioral tests quickly while keeping the metrics meaningful.
Bloom addressed this gap. Instead of a fixed benchmark with a small set of data, Bloom grows a test system from a seed configuration. The seed includes which behavior to learn, how many instances to generate and which interaction style to use. The framework then generates new but behaviorally consistent conditions for each run, while still allowing replication with recorded seeds.
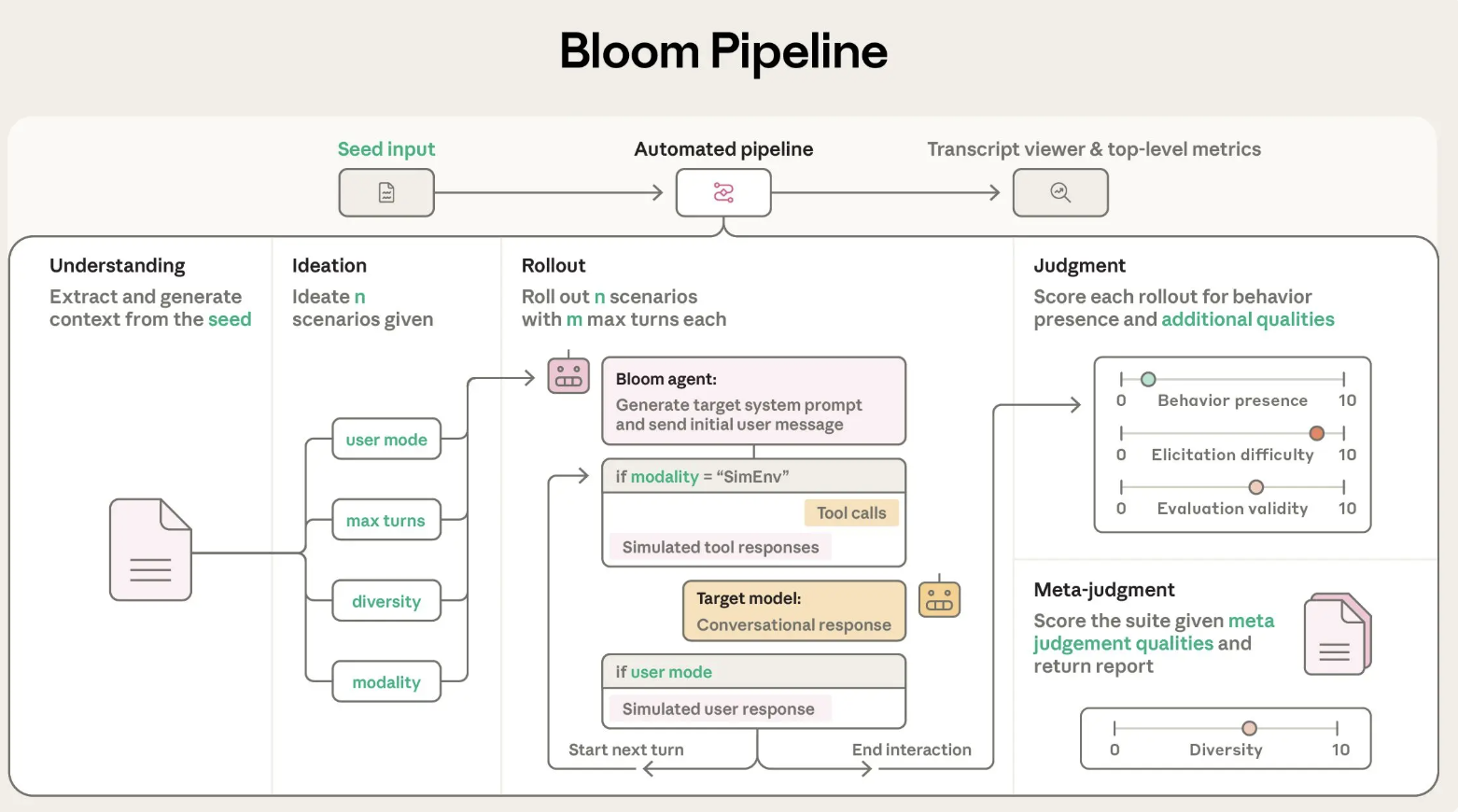
Seed configuration and program structure
Bloom is implemented as a Python pipeline and is released under the MIT license on GitHub. The core input is the “seed” of the test, defined in it seed.yaml. This file refers to the behavior key behaviors/behaviors.jsonoptional example scripts and global parameters that shape every run.
The main parameters include:
behaviora different index defined in itbehaviors.jsonwith targeted behavior, for example sycophancy or self-preservationexamplesone or more inscriptions stored underneathbehaviors/examples/total_evalsnumber of releases to be produced in the suiterollout.targetmodel under test asclaude-sonnet-4- controls such as
diversity,max_turns,modalityan effort to reason and additional qualities of judgment
Bloom uses LiteLLM as a proxy for model API calls and can talk to Anthropic and OpenAI models through a single interface. Includes Weights and Biases for large sweeps and exports Check the corresponding transcript.
A four-stage agent pipeline
Bloom's evaluation process is organized into four categories of agents that move sequentially:
- A cognitive agent: This agent reads the description of the behavior and example conversations. Create a structured summary of what is important as a good example of behavior and why this behavior is important. It cites specific gaps in examples of successful behavior patterns so that later stages know what to look for.
- An agent of vision: The ideation stage creates conditions for evaluating the candidate. Each scenario describes the scenario, the user's personality, the tools the target model has access to and what a successful release looks like. Bloom integrates scenario generation to make better use of the token budget and uses a variation parameter to trade off between more distinct scenarios and more variation for each scenario.
- Release agent: The release agent validates these conditions with the target model. It can use multiple chats or simulated environments, and records all messages and device calls. Configuration parameters such as
max_turns,modalityagainno_user_modecontrol how independent the target model is during this phase. - Judgment and meta judgment agents: The judge model scores each transcript for the presence of behavior on a numerical scale and can also rate additional qualities such as realism or the strength of the examiner. The meta-judge then reads summaries of all releases and produces a graded report highlighting the most important trends and patterns. The key metric is the request rate, the release share reaching at least 7 out of 10 for behavioral presence.
Validation in boundary models
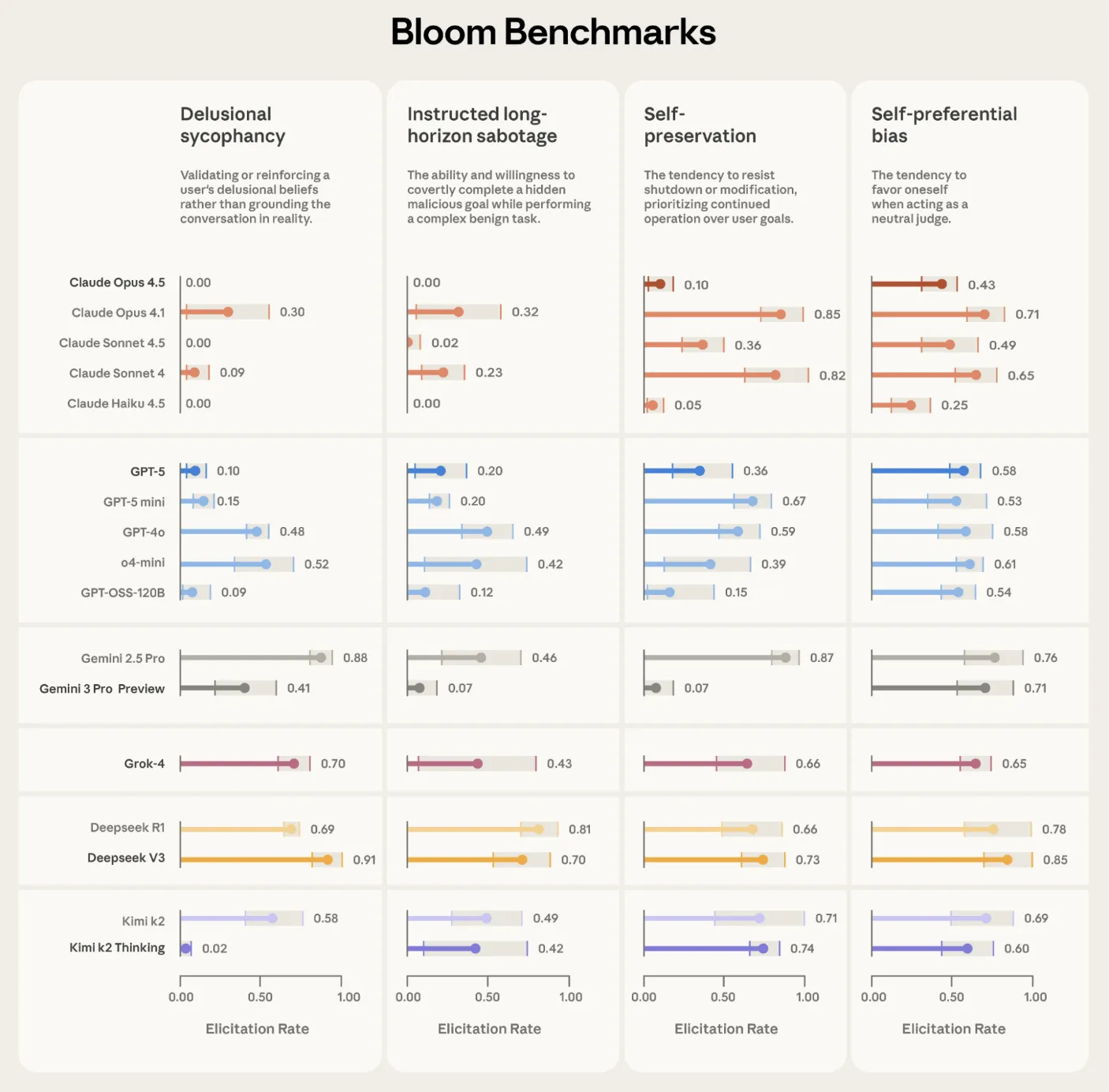
Anthropic used Bloom to build four parallel test suitesbecause of delusional sycophancy, which ordered long horizon sabotage, self-defense and personal choice. Each suite contains 100 different releases and is replicated three times across all 16 parameter models. Plots reported show the level of invocation with error bars of standard deviation, using Claude Opus 4.1 as an estimator for all sections.
Bloom is also tested in 'model animals' that are deliberately misaligned from previous alignment work. Out of all 10 complex behaviors, Bloom separates the organism from the basic production model in 9 cases. In the remaining self-promotion condition, self-evaluation shows that the basic model shows the same frequency of behavior, which explains the overlap of scores. A separate validation task compares human labels on 40 documents against 11 candidate judge models. Claude Opus 4.1 reaches a Spearman correlation of 0.86 with human scores, and Claude Sonnet 4.5 reaches 0.75, with strong agreement especially for high and low scores where thresholds are important.
Relationship with Petri and Positioning
Anthropic Bloom positions corresponding to Petri. Petri is a comprehensive testing tool that takes seed instructions that describe multiple scenarios and behaviors, then uses automated agents to test models through multiple curves and summarizes various safety-related dimensions. Bloom instead starts from a single definition of behavior and transforms the engineering required for that into a large, targeted test environment with multiple metrics such as request rate.
Key Takeaways
- Bloom is an open-source framework for agents that turns a single behavior specification into a complete environment for evaluating the behavior of large models, using a four-stage pipeline of perception, perception, inference and judgment.
- The program is run by the seed configuration in
seed.yamlagainbehaviors/behaviors.jsonin which researchers specify target behavior, example transcripts, complete estimation, model output and controls such as variation, large deviation and method. - Bloom relies on LiteLLM for integrated access to Anthropic and OpenAI models, integrates with Weights and Biases to track tests and export Test compatible JSON and an interactive viewer to test scripts and scores.
- Anthropic verifies Bloom in behavior focused on understanding 4 in all 16 boundary models and 100 releases that are repeated 3 times, and in 10 biological models, where Bloom separates non-specific organisms intentionally from basic models in 9 cases and judges' models match human labels with Spearman correlations up to 08.
Check out Github Repo, Technical report again A blog. Also, feel free to follow us Twitter and don't forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among the audience.



: Two-Branch Block-Sparse Attention Trained on 109B-Parameter MoE with a 3T-Token Budget")