Tencent Huyuan releasing Huyunaanocr: 1b parameter ending OCR VLM expert

Tencent Huyuan released Hunyoan, a 1B parameter language model specialized in OCR and document understanding. The model is built on traditional Hunyun architecture and uses spots, paring, information extraction, visual question answering, and text translation that is translated with one end to complete the pipeline.
Huyunor is a lightweight alternative to standard vlms like Gemini 2.5 and Qwen3 VL that sync or bypass OCR centric functions. It aims to produce use cases such as document parsing, card and receipt issuance, video sub-domains, and multilingual translation.
Architecture, traditional vishi and lightweight LLM
HUNYUANOCR 3 main modulesA traditional solution for maintaining a link called Huyuan Vit, a flexible MLP connector, and a lightweight language model. Encoder is based on Siglip-v2-400m and has been extended to support arbitrary input decisions that keep the original ratio. Images are divided into titles according to their traditional measurements and processed with global attention, which improves recognition in long lines of text, long documents, and low quality scans.
The flexible MLP connector enables readable installation with spatial dimensions. It compresses visual tokens in short order, while preserving information from dense regions. This reduces the length of the sequence passed to the language model and reduces the value, while preserving the relevant OCR information.
The language model is based on the Huyun 0.5B wide model and uses the XD thread. The XD thread divides the position of the rotary dynamic into 4 parts of text, height, width and time. This gives the model a traditional way of synchronizing the 1D Token Order with the 2D structure and the 3D SpatiOToSemoral structure. Because of this, the same stack can handle multiple column pages, cross page flows, and sequences of video frames.
Training and cutting followed the end completely to finish the phasigm. There is no external analysis or external analysis or input loop model. All operations are expressed as natural language dynamics and handled in a single pass. This design eliminates error propagation in all PIPELINE stages and simplifies deployment.

Data and initial training recipe
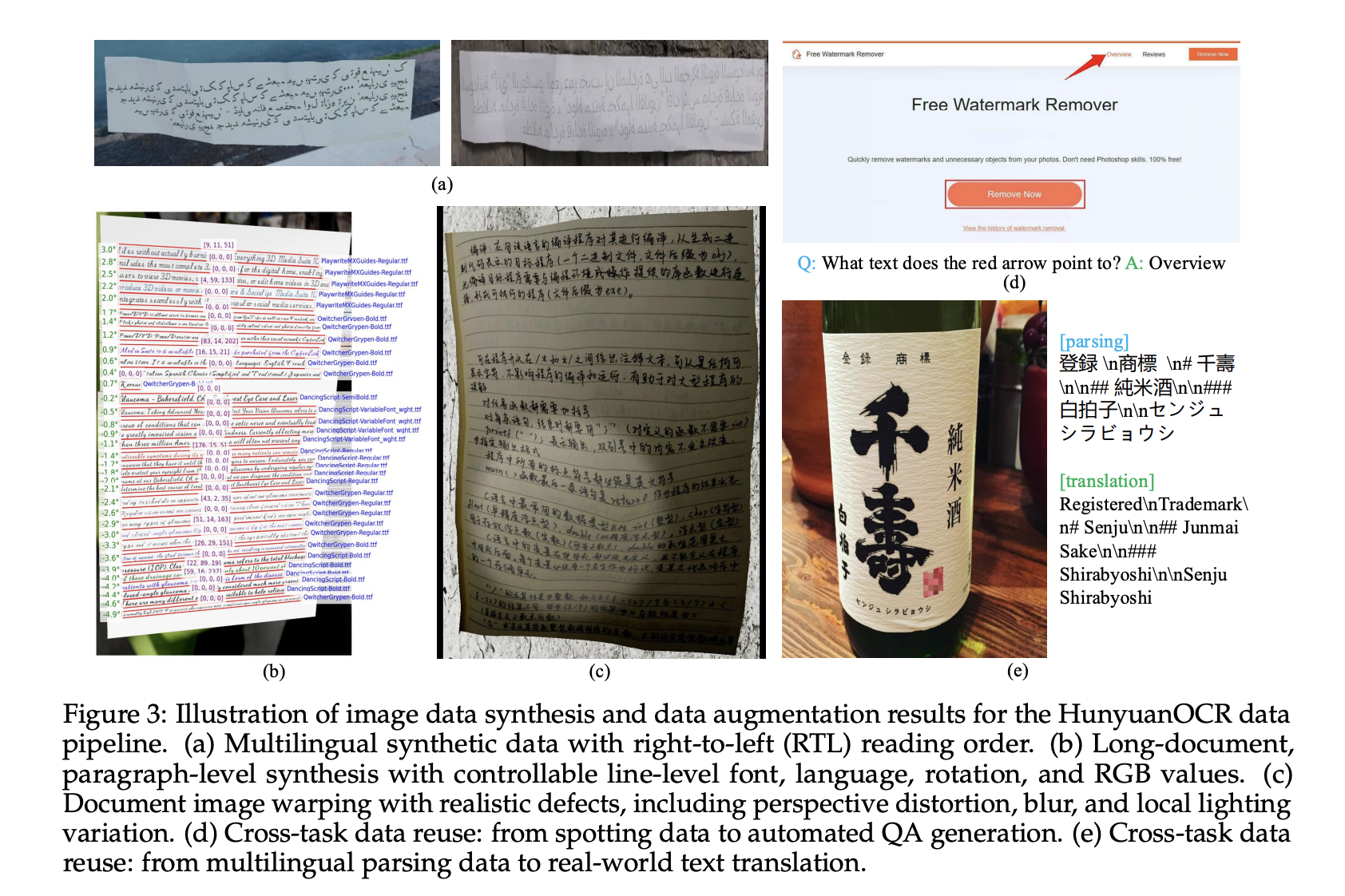
The data pipeline consists of more than 200m of image text, in all real world situations, including street views, documents, advertisements, text, cards and certificates, video frames, and game typing, and game typing. The Corpus covers more than 130 languages.
The generated data comes from a multilingual generator that supports left-handed text input and paragraph-level translation. The pipeline controls the font, language, rotation of roses, and RGB values, and uses warping, fading, and local lighting changes to simulate mobile capture and other difficult situations.
Pre-training follows 4 stages. Stage-1 performs linguistic compatibility of the vision with plain text, artificial objects and recognition data, and standard caption data, using 50B tokens and 8B context. Phase-2 runs multimodal pre-training on 300b tokens that mixes pure text with visual, dynamic, translation, translation, VQA samples. Stage-3 extends the context length to 32k with 80b tokens focusing on long documents and long text. STAGE-4 is directed to a good application organized by 24b tokens of negative human data and Hard.
Reinforce Learning with Guaranteed Rewards
After the supervised training, Huyunuanocc is done again by relearning. The research group uses Group Valing Common Optimization GRPO and reinforcement learning with guaranteed reward settings for structured tasks. To see the text, the reward is based on connecting more than the union similarity of the boxes combined with the normal editing distance with the text. For document awareness, the reward uses the average editing distance between the generated and the reference structure.
For VQA and translation, the program uses an LLM as a judge. VQA uses a binary reward that evaluates semantic play. Translation using comet style hits LLM with scores inside [0, 5]it is normal to [0, 1]. The training framework includes length limits and strict limits, and we assign a zero reward when the results overflow or break the schema or promote efficiency and promote efficiency of json or promote efficiency of json or promote efficiency or output.
Benchmark results, model 1b competes with major VLMS
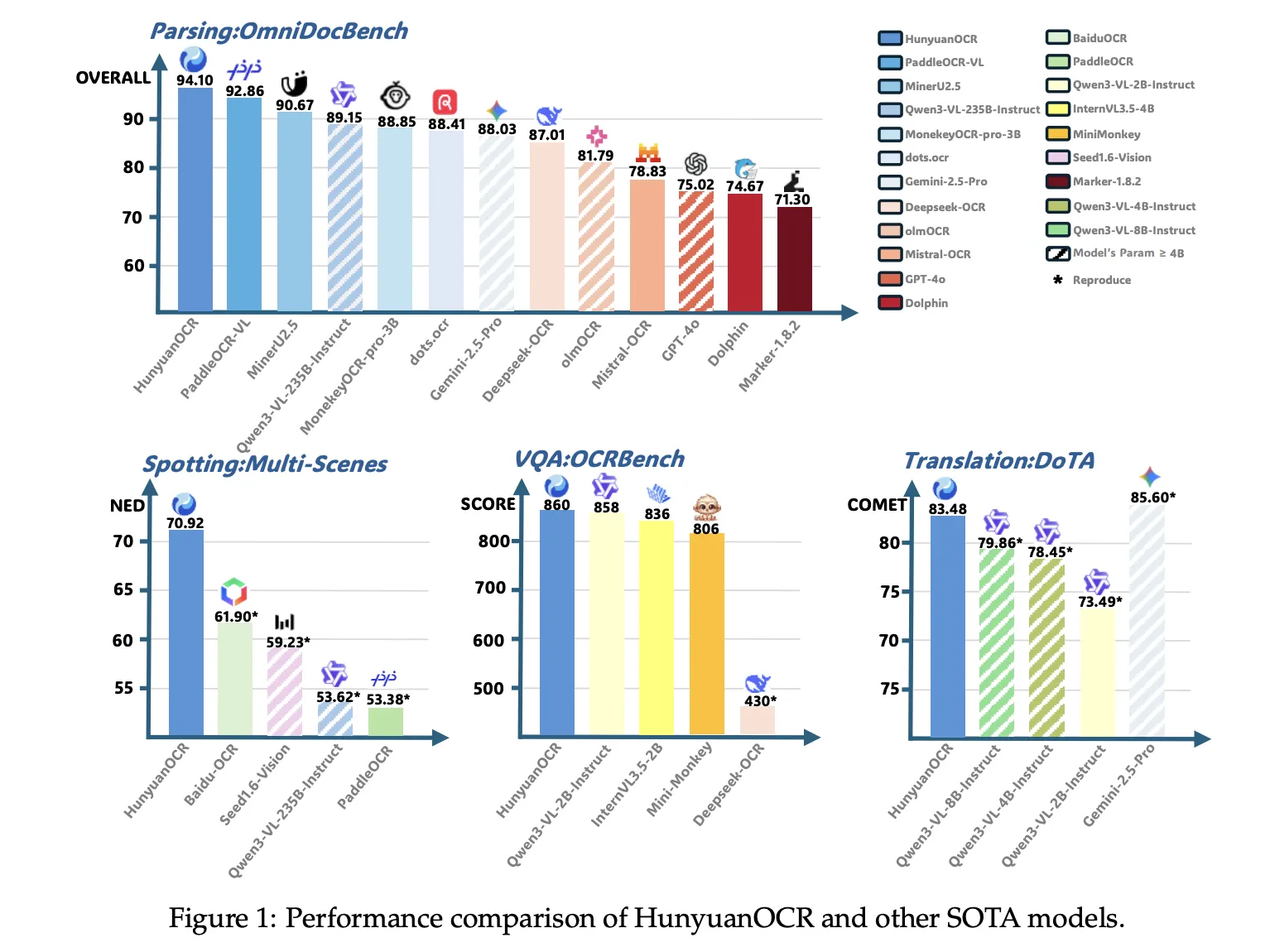
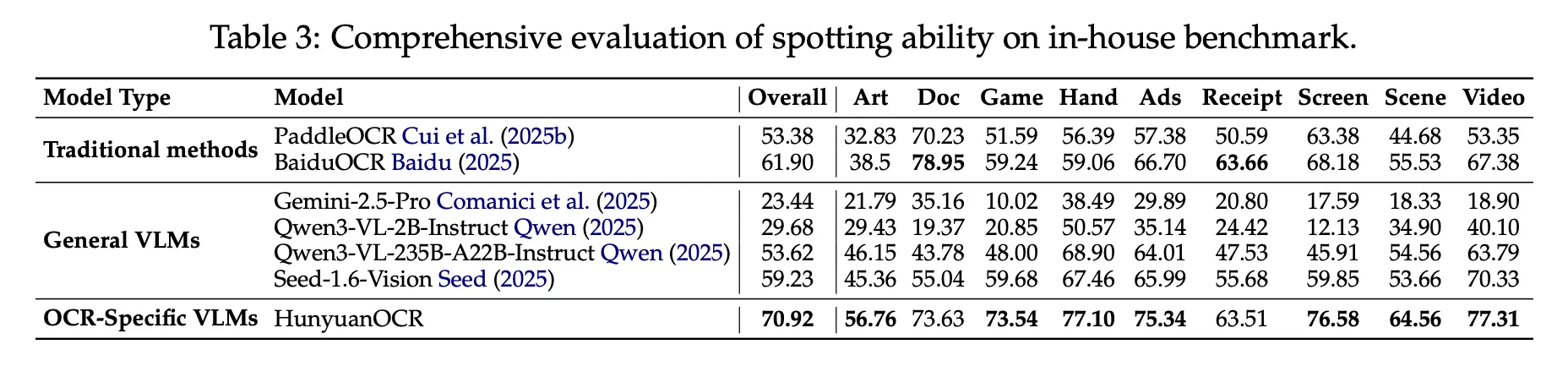
In an internal benchmark of 900 images in 9 categories, Hunyoanoc reaches a total score of 70.92. It outperforms traditional pipelines such as Padceloc and Baiduc and standard vlms such as Gemini 2.5 Pro, Qwen3 VL 235B, despite using fewer parameters.
In Omnidocbelch, Huyunuanocz reaches 94.10 overall, with 94.73 in formulas and 91.81 in tables. In the Wild Omnidocbelch Variant, for printing and duplicating documents under folders and lighting changes, the scores will be 85.21. In Docml, the Multilingual Parsing Benchmark for these 14 Chinese and English languages, reaches 91.03, and the paper reports the state of the art results for all 14 languages.
In terms of information extraction and VQA, Huyunoanoct achieves an accuracy of 92.29 for cards, 92.53 for receipts, and 92.87 for video subtitles. In OCRBENCH, CONTINUOUS 860, it is higher than Deentiseek OCR in the same measure and it is close to standard vlms such as qwen3 vl 2b it teaches and Gemini 2.5 Pro.
For text translation, Huyunocc uses Dota Benchmark and an internal set of DoCML. It achieves a strong comet comet in Dota English to Chinese Donstation translation, and the model wins the first place tracking 2.2 OCR free ICDAR 2025 DIM TRECE small model.
Key acquisition
- Compact End to end OCR VLMThe Huyuthaanocr model is an OCR language model that focuses on the traditional 0.4B type on the 0.5B Huyun Vol in the car with the MLP adapter, and rus, data extraction, VQA and translation, acquisition modules.
- Integrated support for various OCR modes: The model is trained with 200M text pairs 9 images of 9 years of text, including documents, advertisements, commercials, handwritten content, video communication sites, with support for more than 130 languages in the transmission.
- Data Pipeline and reinforcement learning: Training uses a 4-stage recipe, Vision language alignment, multimodal pre-training, pre-training and well-targeted application training, followed by guaranteed vision rewards, guaranteed vision rewards, guaranteed spot recognition rewards, parsing, VQA and translation.
- Robust Benchmark results for rub 3b models
Huynous reaches 94.1 in Omnidocbelch for document intelligibility, and reaches 860 in OCRBECH, which is reported as state of the art among 3B models, while a few commercial models such as QWEN3 VL 4B are mentioned in the top OCW benches.
Editorial notes
Huyunaanocr is a strong indicator that some OCR VLMs are being developed on a working infrastructure, not just a bench. Tencent includes a parameter limit of 1b to complete the construction of archites with a native transformer, flexible connectors of MLP and RL with guaranteed rewards to deliver more than 100 models, and it does so when translating ocrbench models with 74 models. Overall, Hunyo or HUNYUANOCR represents a significant change in compact, practical OCR engines for production deployments.
Look Paper, model weight and repo. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



