Moonshotai issued to checkpoint-engine: easy middleraware to update model instruments in llm engine engines, successfully strengthening

Moonshotai is open Checkpoint-engineLight-free Middleware To resolve one of the main bottles in the biggest model model (llm): Renewing the Model Items in all thousands of GPU
The library is mainly designed for reading of the learning (RLHF).
Llms how fast is the update?
Checkpoint-engine moves important success by renewing a 1-trillie parameter model in all thousands of GPU in 20 seconds.
The pipes distributed by traditional distribution can take a few minutes to reload the models. By reducing the time of the order of magnitude, the test engine addresses one of the major incomes of greater serving.
The program reaches this by:
- Update update in standing clusters.
- Peer Update (P2P) in stirring collections.
- Copy attached to a copy of memory by reducing reduced.
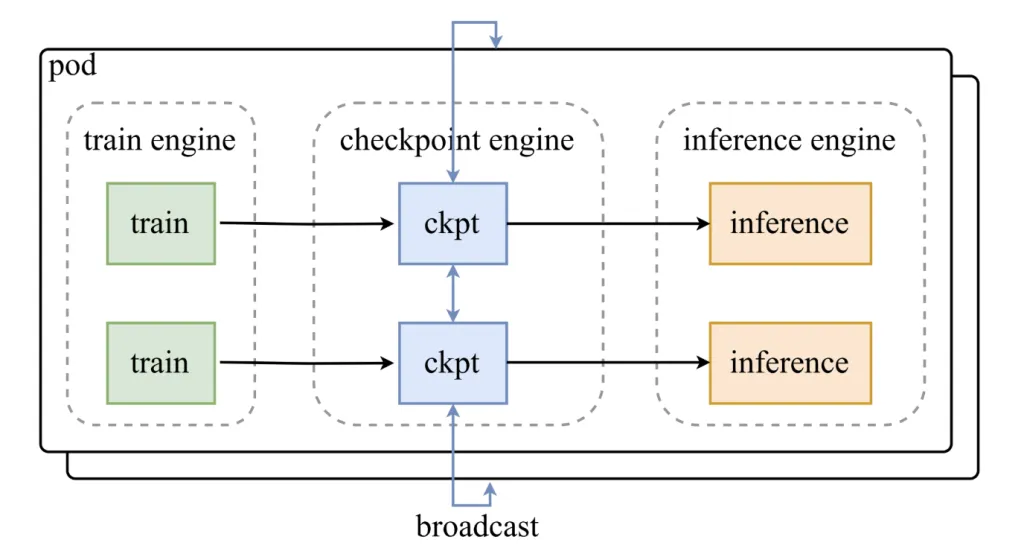
What does the building look like?
Checkpoint-engine stays between training engines and measurement collections. Its design includes:
- A Parameter server That link updates.
- Work extensions that is to meet up with the approval structures as VLLM.
The weight of the weight of the weight is running into three categories:
- Host-to-device (H2D): Parameters copied in the GPU memory.
- Spreading: Weights are distributed to all Cerfers using Cuda IPC Buffers.
- Reload: An Anferred Shard is only reloading the use of the weight we need.
This prescribed pipes are designed to escape, to ensure that the GPUS remains applies to all renewal process.
How does it make a practice?
The effects of measurement measurement guarantees the look at the engine scale:
- GL-4.5-AIR (BF16, 8 × H800): 3.94s (streaming), 8.83S (P2P).
- QWEN3-23B-I Teach (BF16, 8 × H800): 6.75s (Broadcast), 16.47s (P2P).
- Deepseek-V3.1 (FP8, 16 × H20): 12.22s (Broadcast), 25.77s (P2P).
- MI-k2-I am written (FP8, 256 × H20): ~ 21.5s (streaming), 34.49s (P2P).
Even in the Trillion-Parameter Scale with 256 GPUS, broadcast reviews are complete in 20 seconds, confirms its purpose for design.
What is one trade?
CheckPoint-engine launches significant benefits, but also comes with limits:
- Memory over: Designated pipes require additional GPU memory; Inadequate memory for memory caused a slow path.
- P2P LATENCY: Peer-to-peer renewal to support the Waitistic collections but at work costs.
- Care: Officially tested with VLLM; The broadcast engine support requires engineering activity.
- Quantity: FP8 Support are but remain in the test.
Where does the circumstances of being offered?
Checkpoint-engine is very important to:
- Strengthened Reading Pipes where normal weight reviews are required.
- Large tracking clusters Working for 100B-1S + parameter models.
- Good places With stronger estimate, when the P2P variable reduces the latency trade trade.
Summary
Checkpoint-engine represents a solution that focuses on one of the most difficult problems in the great LLM submission: Quick weight sync without stopping. With the updates displayed in a trillion-parameter area about 20 seconds, flexible support in both streaming and P2P systems, and a prepared telecommunication pipeline, provides effective methods of tightened learning pipes. While limited to VLLM and requires a powerful stigma and powerful estimate, promote an important basis for effective, ongoing remedies in production Ai Systems.
Look The project page here. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Max is an Ai MarkteachPost critic, based on Licon Valley, who diligently develop technical future. He teaches Bide Robatovsne, fighting spam with a compulseeMememail, and put AI daily interpreting the complexity of the technology in finding clear, understandable



