Rest: Checking frame to stress a more problematic thinking in large thoughts of thinking

The largest consultation models (LRMS) promotes, indicates an impressive functionality in complex activities to solve projects such as figures such as mathematical, codes, and scientific thinking. However, current assessments focus on the examination of one questions, which indicates a major limitations. This scripture introduces Relaxation (checking for testing simultaneously) – Framework for assessment problems that are designed to push LRMs more than only problems of solving problems and has better reflected its real powers in the world.
Kungani ama-benchmark e-CHAVA ASHRABRCRCRCRCRCRCRCRCRCRICRS ewa amamodeli amakhulu abonisana
Multiple benches, such as GSM8K and statistics, check the LRMs by asking one question at a time. While effective the development of the first models, this method of question is experiencing two critical issues:
- Reduces power of discrimination: Many ART-ART LRRMs reach scores near popular benchmarks (eg Deepseek-R1 that reaches 97% correctness in Math500). These full results make it more difficult to distinguish the development of true models, forcing expensive, progressive creatures of difficult datasets to distinguish skills.
- Lack of real-life tests in the world: Real Earth's Requests – such as educational teaching, technical support, or multitasking AI-assistant assistants – they need to think about many, disturbing questions at the same time. One question examination does not include these powerful challenges, many problems that show genuine responsibility for understanding and reasoning.
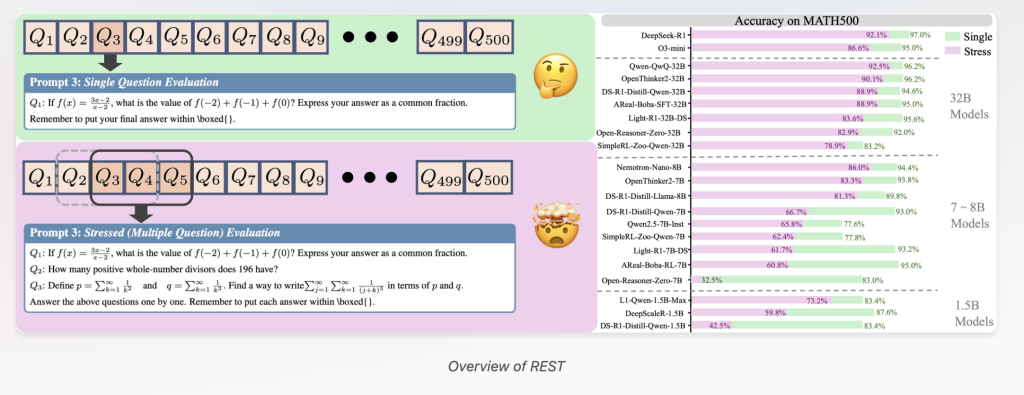
Introduced to rest: LRMS to check on to stress many problems at the same time

Dealing with these challenges, researchers from Tinghua University, Opennatalabab, Shanghai Ai laboratory, and the Renmin University has been developed RestThe easiest way to test but the power to test at the same time LRMS in multiple questions integrated with one acceleration.
- Multi-Pongting Benchmark reconstruction Resting Makes existing benches by cleaning many questions in one orientation, converting The level of stress The parameter regulates how many questions are presented at the same time.
- Complete Assessment: Relaxation is analyzing sensitive skills of thinking can prohibit the solving basic problems – including The allocation of the preservation of the context, Opposition of the problem disorderbeside The management of the psychological load.
- Wide performance: The framework is confirmed in 34 advanced LRMs from 1.5 billion parameters, tested on 7 varied benches in all various difficulties (from GSM8A to GPQA).
Resting Proments the Important Information About LRM consultation skills
The rest assessment approves several sensitive detections:
1. Important performance degeneration under the pressure of many problems
Even LRMS of state Like Deepseek-R1 Indicate the tasks that are visible when handling multiple questions together. For example, Deepseek-R1 correctness on challenging benches like AIs24 Falls about 30% Under rest in comparison with a different question tests. This contradicts previous consideration that large language models are in trouble.
2. Developed the power to discriminate between the same models
A wonderful rest increases the differences between models with the same background scores. In Math500, for example:
- R1-7B including R1-32b Access the intimate accuracy of 93% and 94.6%, respectively.
- Under rest, the accuracy of R1-7b accuracy of plummets in 66.75% While R1-32B ends up high 88.97%stacking stack 22% gap app.
Similarly, between the same size models such as Areal-Boba-RL-7B and Opennhinker2-7b, rest, relaxation is caught a huge difference in the skills of testing.
3
Well structured models by strengthening or directing surveillance in one problem's thinking often fails to keep their beauty in the arrangement of many questions. This requires recurring training strategies to enhance the ability to consult under practical conditions with many forms.
4. “DEMBERS T2SHORT” training improves working under pressure
Models are trained “Long2short Techniques” – Promoting short and effective chains – keep high accuracy under rest. This suggests the promising way of designing models better suited to many problems.
How to relax promotes practical refunds
By exposing Responsibility In LRMS through the problem talk at the same time, rest imitating the actual world demands when consultation programs should prioritize one problem, avoiding one problem, and opposes the same disorder.
Relaxation and is analyzed in order of mistakes, reveals the usual ways of failing such as:
- Release of questions: To ignore the latest questions on mugri-question immediately.
- Deep Eres: Summarizing the answers to problems.
- Errors that show: Mindal or calculations within a consultation process.
This unethical understanding is not very visible in the test of one questions.
Practical Assessment and Benchmark Setting
- Rest tested 34 LRMS sizes from 1.5B to 671B Parameters.
- Checked benches include:
- Simple: Gsm8k
- Medium: Math500, AMC23
- CHALLENGE: Aiese24, AIED25, GPPAFA Diamond, LiveCorebelch
- Periments of production model are set in accordance with legal guidelines, with outgoing token tokens for 32k with reasoning models.
- Using Apecapass Toolkit confirms consistent, renewable results.

Conclusion: Rest as a future evidence, the LMM Avitation Paradigm
Relax create an important line for ahead to examine the large model models:
- To prepare the full benchmark: Reviewing existing datasets without full full replacement.
- Displays the actual worldwide demand: Models assessed under facts, the higher understanding conditions.
- Guide the development of model: It highlights the importance of training methods such as long2forest to reduce excessive thinking and encourage the focus of changing thinking.
In SUM, rest closing the method of having strong consideration, as well as effective use of the next consultation of AI Systems.
Look Paper, the project page including Code. All credit for this study goes to research for this project. Sign up now In our Ai Newsletter

Sajjad Ansari final year less than qualifications from Iit Kharagpur. As a tech enthusiasm, he extends to practical AI applications that focus on the understanding of AI's technological impact and their true impacts on the world. Intending to specify the concepts of a complex AI clear and accessible manner.


: Protect your ML models")
