
# Introduction
Line-by-line iteration is one of the most common problems in practice the pandas the code. For small datasets it is negligible, but for processing large datasets, this has an effect.
pandas are built on top NumPywhich performs operations on all arrays simultaneously using compiled C code. Skipping lines in Python bypasses that entirely and forces all work back to the Python interpreter – one line at a time.
This article covers 7 methods of loops in pandas, each suitable for a different type of transition. Finally, you will have a clear mental map of which tool to reach for depending on the problem situation.
You can find the Colab notebook on GitHub.
# Sample Dataset Setup
We will use a dataset of real e-commerce orders throughout this article:
import pandas as pd
import numpy as np
np.random.seed(42)
n = 100_000
categories = ['Electronics', 'Clothing', 'Home & Kitchen', 'Sports', 'Books']
regions = ['North', 'South', 'East', 'West']
df = pd.DataFrame({
'order_id': range(1, n + 1),
'customer_age': np.random.randint(18, 70, n),
'product_category': np.random.choice(categories, n),
'region': np.random.choice(regions, n),
'price': np.round(np.random.uniform(5.0, 500.0, n), 2),
'quantity': np.random.randint(1, 10, n),
'days_to_ship': np.random.randint(1, 14, n),
})
display(df.head())Output:
We now have a data set of 100,000 rows to work with.
# 1. Using Vectorized Arithmetic Functions
For any arithmetic or column comparison, vectorized operations should be your first instinct.
What we want to do: calculate the amount of revenue per order.
df['revenue'] = df['price'] * df['quantity']
display(df[['price', 'quantity', 'revenue']].head())Output:
# 2. Using Conditional Mental Activity
If your conversion involves some logic that cannot be expressed as plain arithmetic, .apply() allows you to pass a function over a column or row.
What we want to do: label the shipment first based on the shipment dates.
def shipping_label(days):
if days <= 2:
return 'Express'
elif days <= 5:
return 'Standard'
else:
return 'Economy'
df['shipping_tier'] = df['days_to_ship'].apply(shipping_label)
display(df[['days_to_ship', 'shipping_tier']].head())Output:
Using .apply() it's clean, readable, and much easier to remove than a loop. Use it if your mind is conditioned too np.where() or np.select() you feel very nested.
# 3. Use np.where() In Binary Cases
If you have a binary state – one result if true, the other if false – np.where() a clean, quick choice.
What we want to do: flag orders where the customer is eligible for the maximum discount.
df['senior_discount'] = np.where(df['customer_age'] >= 60, True, False)
display(df[['customer_age', 'senior_discount']].head())Output:
np.where() it is fully vectorized and much faster than that .apply() with simple true or false conditions. Think of it as a vectorized ternary operator.
# 4. Choice in All Multiple Situations with np.select()
If you have more than two conditions, np.select() allows you to define a list of conditions and their corresponding values without the need for nested if/elif chains.
What we want to do: give the tax rate based on the region.
conditions = [
df['region'] == 'North',
df['region'] == 'South',
df['region'] == 'East',
df['region'] == 'West',
]
tax_rates = [0.08, 0.06, 0.07, 0.09]
df['tax_rate'] = np.select(conditions, tax_rates, default=0.07)
df['tax_amount'] = df['price'] * df['tax_rate']
display(df[['region', 'price', 'tax_rate', 'tax_amount']].head())Output:
np.select() it checks all the cases in order and selects the first match. I default parameter handles anything inconsistent, useful as a safety net.
# 5. Mapping Values to a Dictionary
When you need to translate values in a column — such as mapping category names to numeric codes, or replacing keys with labels — .map() with the dictionary clean and fast.
What we want to do: map product categories to internal door codes.
category_codes = {
'Electronics': 'ELEC',
'Clothing': 'CLTH',
'Home & Kitchen': 'HOME',
'Sports': 'SPRT',
'Books': 'BOOK',
}
df['dept_code'] = df['product_category'].map(category_codes)
display(df[['product_category', 'dept_code']].head())Output:
.map() it works like a lookup table. It's one of the least used tools for pandas – we often reach for it .apply(lambda x: dict[x]) when .map(dict) he quickly did the same.
# 6. Changing Strings with .str Accessory
String manipulation is where people often create for loops .apply(). I .str accessory allows you to run string operations on every column without exception.
What we want to do: extract the first word from product_category column and convert it to lowercase.
df['category_slug'] = df['product_category'].str.split().str[0].str.lower()
display(df[['product_category', 'category_slug']].head())Output:
You can chain .str methods like standard Python string methods. It also supports .str.contains(), .str.replace(), .str.extract() for regex, and more.
# 7. Joining Parties by .groupby()
A typical loop pattern iterates over subsets of the data to calculate group-level statistics. .groupby() handles this natively.
What we want to do: calculate the total revenue and average shipping days for each product category.
summary = (
df.groupby('product_category')
.agg(
total_revenue=('revenue', 'sum'),
avg_ship_days=('days_to_ship', 'mean'),
order_count=('order_id', 'count')
)
.round(2)
.reset_index()
)
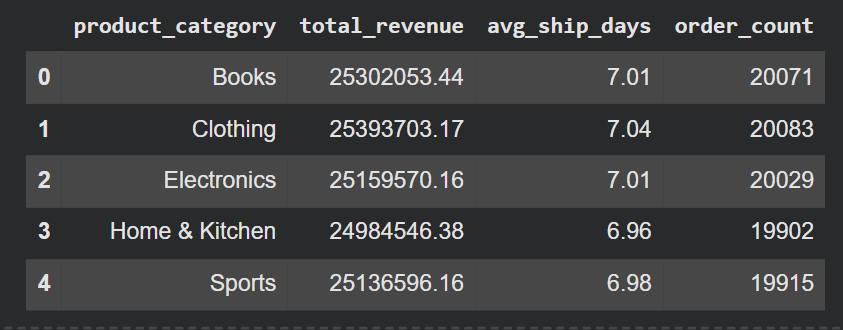
summaryOutput:
# Choosing the Right Tool
Most of the changes you can write a loop to fit cleanly in one of these patterns:
| Operation / Method | Use Case / Description |
|---|---|
| Arithmetic in columns |
Perform built-in mathematical operations such as addition, subtraction, multiplication, and division directly on DataFrame columns. |
Vectorized functions (*, +etc.) |
Use smart functions on all columns efficiently without explicit loops. |
| A simple true/false scenario |
Evaluate boolean conditions to filter or create conditional columns. |
np.where() |
Apply conditional logic (if not) to the vectorized method on the array and columns of the DataFrame. |
| Many situations, many consequences |
Manage complex conditional logic with multiple rules and results. |
np.select() |
Select values based on multiple conditions and return the corresponding output. |
| Changing the value by lookup |
Change values using map dictionaries to make quick changes. |
.map(dict) |
Map values to a String using a dictionary or function to convert. |
.apply() |
Use custom functions rowwise or columnwise to find variable changes. |
| Thread manipulation |
Use string functions with |
.groupby() + .agg() |
Group data and calculate aggregate statistics such as sum, average, count, etc. |
Once you start thinking in columns rather than rows, you'll find the pandas API starts to feel less like a workaround and more like the actual intended way of working.
Count Priya C is an engineer and technical writer from India. He loves working at the intersection of mathematics, programming, data science, and content creation. His areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, he works to learn and share his knowledge with the engineering community by authoring tutorials, how-to guides, ideas, and more. Bala also creates engaging resource overviews and code tutorials.



