
# Introduction
Many groups find that they need a feature store the hard way. The fraud model works on a notebook and breaks quietly into production. The support agent gives a generic answer because they don't know who the user is. The recommendation pipeline repeats the same “30-day disposal” figure for three jobs, and two of them disagree.
The feature store is part of the infrastructure that fixes those problems. It defines features once, stores them in two ways (one for training, one for deployment), and keeps them both synchronized. We will build small from scratch Pythonusing DuckDB, Parquet, Redisagain FastAPI. Then we'll look at how AI applications are changing what we use them for.
The full code is short enough that we'll go through all the parts.
# What a Self-Resolving Feature Store
The classic pitch is skew-serving skew: the SQL that makes up your training set is not the same code that runs in the target, so the values drift. That problem is real, and offline partitioning and online partitioning are standard fixes.
The modern tone is broad. Agents for large language modeling (LLM) and advanced retrieval generation (RAG) pipelines require a structured user context with a decision time, for every request, of less than 10ms. LLM has no memory of who the user is. If we want personalized output, we must include the user's program category, recent activity, and account status in the notification, and we need a system that can return those values quickly and consistently. That's exactly what the online feature store and retrieval API offers us.
So we built both. The same five sections deal with the predictive machine use case and the LLM context use case.
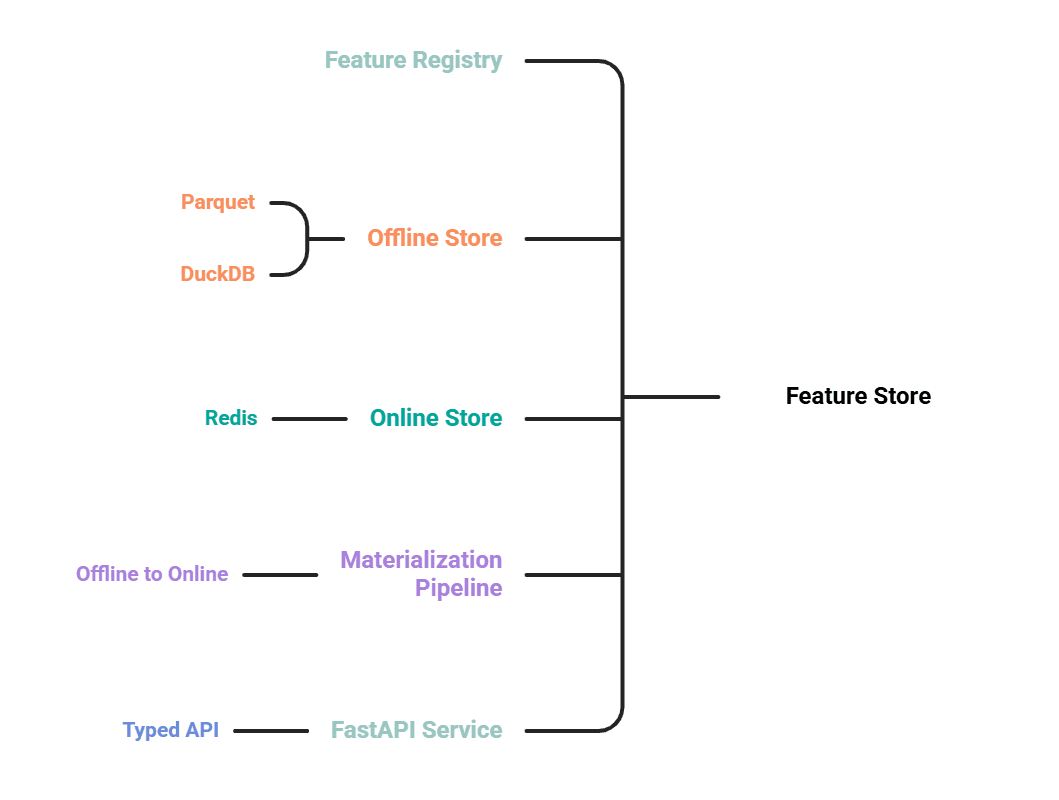
# The Five Parts
- Feature registration that describes features as code.
- An offline store on Parquet, queried from DuckDB, for training and back-filling.
- An online store on Redis for low-latency routing.
- A transaction pipeline that pushes the latest values from offline to online.
- A FastAPI service that exposes a typed retrieval API.
# Practical Example: A Personalized LLM Recommendation
We use a live streaming service. When the user opens the app, LLM generates a short, personalized “to watch you next” message. The LLM requires three things about the user:
| A feature | Kind of | Burning |
|---|---|---|
user_segment |
string | every day |
watch_count_30d |
int | per hour |
last_genre |
string | for each event |
Business says user_id. We will register these three features, make them available, and provide them to the LLM at the time of request.
// 1. Defining Feature Registration
A registry is simply a place where elements are declared along with their entity, dtype, and source. We use the data class.
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Feature:
name: str
entity: str
dtype: Literal["int", "float", "str"]
source: str # path to a Parquet file or a SQL view
REGISTRY: dict[str, Feature] = {
"user_segment": Feature("user_segment", "user_id", "str", "data/user_segment.parquet"),
"watch_count_30d": Feature("watch_count_30d", "user_id", "int", "data/watch_count_30d.parquet"),
"last_genre": Feature("last_genre", "user_id", "str", "data/last_genre.parquet"),
}The complete code can be found here.
When you run it, the output shows:
Registered features:
user_segment entity=user_id dtype=str source=data/user_segment.parquet
watch_count_30d entity=user_id dtype=int source=data/watch_count_30d.parquet
last_genre entity=user_id dtype=str source=data/last_genre.parquetThis is a contract. Every other part learns from REGISTRYso renaming an element, changing its dtype, or specifying a new source happens in one place. In production systems, this can be YAML or a Python module installed in a Git repo, with code updates for every change.
// 2. Building an Offline Store with DuckDB and Parquet
The offline store holds a full history of all value elements. We use Parquet files as the storage layer and DuckDB as the query engine. DuckDB reads Parquet directly, which means no separate database will work.
Here is a sample code:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame, features: list[str]
) -> pd.DataFrame:
con = duckdb.connect()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
con.execute(f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'")
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()The complete code can be found here.
When you run it, the output shows:
| User ID | event_timestamp | users_section | watch_count_30d | last_type |
|---|---|---|---|---|
| 8a2f | 2026-05-05 12:00:00 | common | 22 | And N |
| b13c | 2026-05-07 20:00:00 | common | 5 | happiness |
| 8a2f | 2026-05-07 22:00:00 | power_user | 47 | a documentary |
I AsOf joining joining point-in-time. For every line of business, it selects the latest value of the feature when the timestamp of the feature is on or before the timestamp of the event. That's what prevents leakage – where a training curve is built with a feature value that doesn't currently exist at the time we're predicting it.
Joining in time is still the right answer for any model we plan to train or fine-tune. For the pure LLM use case of inference time, we may never call this function. We still need an offline store, as this is where backfilling, analytical datasets, and audits come in.
// 3. Setting up an Online Store on Redis
The online store only stores the latest price for each business. Redis is a common choice because hash lookups are in subseconds.
import json
import fakeredis # use redis.Redis() against a real server in production
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={k: json.dumps(v) for k, v in values.items()},
)
def read_online(entity: str, entity_id: str, features: list[str]) -> dict:
raw = r.hmget(f"{entity}:{entity_id}", features)
return {f: json.loads(v) if v else None for f, v in zip(features, raw)}The complete code can be found here.
When you run it, the output shows:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
missing key -> {'user_segment': None}The important aspect is that entity:entity_id. The value is a hash with one field per element. One HMGET it returns all the elements we requested in a single return trip. For a local Redis instance with three elements, this ends up being less than 1ms.
// 4. Using the Materialization Pipeline
Virtualization moves values from offline to online. In a real system this works on a schedule (Airflow, cron, streaming job). Here is the job.
def materialize(features: list[str]) -> None:
by_entity: dict[str, dict] = {}
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row[f.entity], {})[fname] = row[fname]
for entity_id, values in by_entity.items():
write_online("user_id", entity_id, values)The complete code can be found here.
When you run it, the output shows:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'casual', 'watch_count_30d': 5, 'last_genre': 'thriller'}I QUALIFY clause stores the latest row for each entity. We combine all features of the same user into a single Redis script to cut round trips. Run this at the cadence each feature needs: every hour watch_count_30dnear the real time of last_genreevery day for user_segment. Registration is the right place to code that cadence in actual use.
// 5. Introducing the FastAPI Retrieval Service
Production location service. That's what the LLM program calls for.
f = resp.json()["features"]
print("nPrompt the LLM would receive:")
print(
f" System: You recommend shows for a streaming service.n"
f" User context: segment={f['user_segment']}, "
f"watched {f['watch_count_30d']} titles in last 30 days, "
f"last genre watched: {f['last_genre']}.n"
f" Task: suggest 3 titles in a friendly, short message."
)The complete code can be found here.
When you run it, the output shows:
POST /get-online-features -> 200
body: {'user_id': '8a2f', 'features': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
Prompt the LLM would receive:
System: You recommend shows for a streaming service.
User context: segment=power_user, watched 47 titles in last 30 days, last genre watched: documentary.
Task: suggest 3 titles in a friendly, short message.The feature store is the piece that converts “user 8a2f” into a structured context that LLM can use.
# Where the Feature Store Ends and the Vector Database Begins
The vector database (Pine, Weaviate, pgvector) is not a feature store, even if they both sit in front of the model in thinking. They solve different retrieval problems.
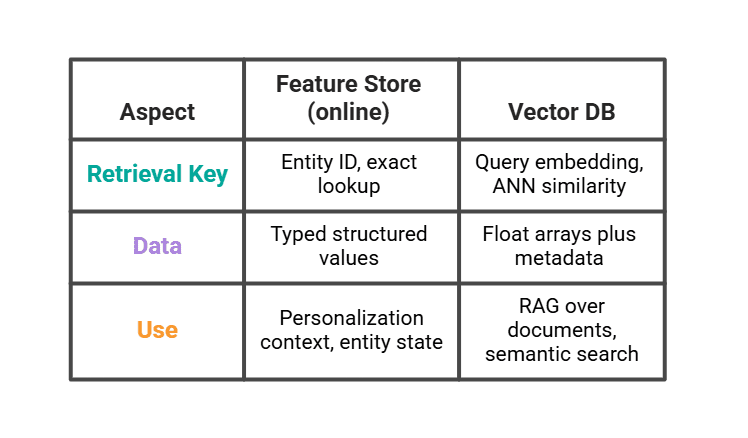
The actual LLM stack uses both. The vector database returns the three most similar past viewing sessions. The feature store returns the user's segment and latest count. The solution combines them.
# Common Anti-Patters
A few patterns we often see fail:
- Computer features within the service model. The same concept ends up in the training manual and the API, and the two definitions move between quarters.
- Managing the online store as a source of truth. Redis loses data on bad restarts. The offline store is legal; the online store is a repository.
- Skipping registration. The three groups describe independently
active_userand dashboards stop matching the model. - Calling a vector database an element store. It can't do a structured lookup with an entity key, and information that needs both will end up being wired to the two systems anyway.
- Backfilling without point-in-time joins. The training set looks good, the production model looks broken, and the gap is a leak.
# Comparing This to Deal, Tecton, and Databricks
Our ~200 lines do the same job at a minimum.
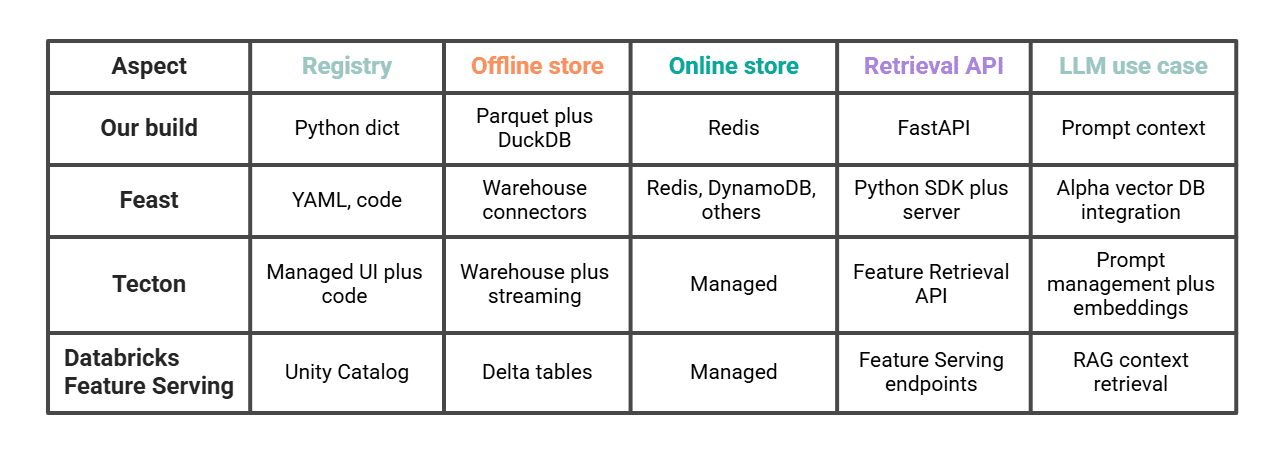
A feast the closest comparison is if we want to move forward in the same pattern, we hold for ourselves. Tecton again Databricks managed methods and has clear LLM features (Tecton's Feature Retrieval API for LLMs, Data Bricks feature for integrated AI Manufacturing Systems). Choosing between them is often a question of how much automation we want to do ourselves and whether our entire stack already resides on Databricks.
# The conclusion
A functional feature store fits into five parts: a registry, an offline store, an online store, a virtualization step, and a discovery API. Building it sometimes teaches us why production systems look the way they do. It also shows where design is changing AI: online retrieval is a hit with LLM, point-in-time includes matter when training or testing, and the vector database lives next to the feature store, not inside it.
Once we have these pieces, swapping our own version of Feast, Tecton, or Databricks is usually a registry move. The state of the system remains the same.
Nate Rosidi he is a data scientist and product strategist. He is also an adjunct professor of statistics, and the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real interview questions from top companies. Nate writes about the latest trends in the job market, provides interview advice, shares data science projects, and covers all things SQL.



