Hexo Labs Open-Sources SIA: A Self-Developing Agent That Updates Both Harness and Model Weights

Most AI agents stop improving when people stop tuning them. The model is fixed. The scaffolding around us has been repaired. Hexo Labs wants to deliver both at the same time. It released SIA (Self-Improving AI) this week as an open source framework under the MIT license.
The core claim of this study is small but strong. SIA organizes both the agent framework and the model weights within a single self-optimizing loop.
What is SIA (Self-improvement AI)
SIA divides the task-specific agent into two parts. The first is a harness, also called a scaffold. That includes system information, tool deployment logic, retry policy, and response output code. The second part weights the model itself.
The three parts of LLM drive the loop. Meta-Agent writes the initial scaffolding from the task specification and any reference code. A Special Task Agent runs the task and logs every step. The Feedback Agent then reads that full route and decides what to change.
That decision is the main idea. After each run, the Response Agent chooses one of two actions. It can rewrite the scaffolding while the weights remain constant. Or it can initiate a weight update while the scaffolding remains unchanged.
The base model is openai/gpt-oss-120b. Weight updates use LoRA, a low-level adapter, at position 32. Meta-Agent and Feedback-Agent both work in Claude Sonnet 4.6. Training runs on H100 GPUs with Modal, the RL team's platform.
The research team labels its two operating points SIA-H and SIA-W+H. SIA-H uses harness updates only. SIA-W+H adds weight updates above.
The Benchmark Case
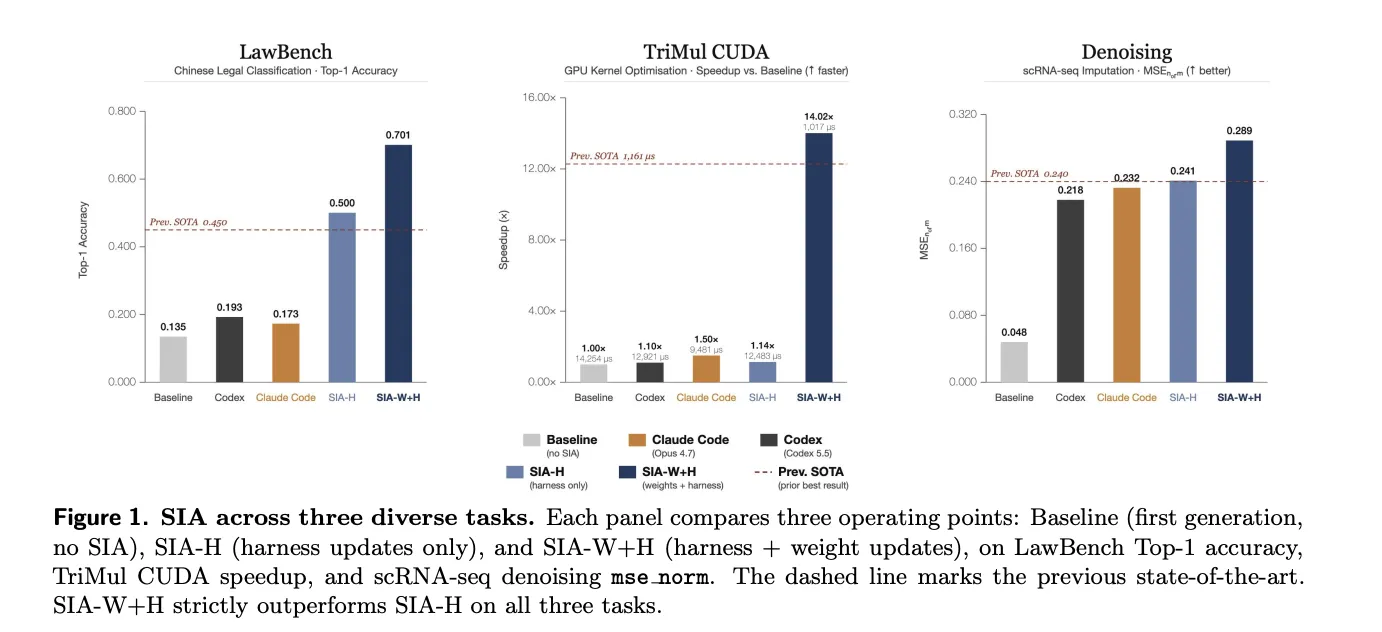
The research team tested SIA in three different domains on purpose. The pattern holds for all three. Weight updates added benefits beyond what was achieved by scaffolding alone. “First” the basic model by using the first Meta-Agent scaffold, before any response.
| Work | First of all | The past. SOTA | SIA-H (harness only) | SIA-W+H (harness + weights) |
|---|---|---|---|---|
| LawBench (top-1 acc) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul (reward) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
In LawBench, the task is the classification of 191 categories of Chinese criminal cases. Harness iteration built the TF-IDF pipeline and LinearSVC and is 50.0% higher. Weight update with PPO then pushes the accuracy to 70.1%. That's a 20.1 percent gain over the harness-only best.
The TriMul task requests a custom CUDA kernel on the H100 GPU. The kernel computes the key functionality in the Evoformer module of AlphaFold2. Scaffold alignment reached a speed of 1.14× over baseline. The weight update then runs the runtime from 12,483 to 1,017 microseconds. That's a 91.9% reduction from just the top of the harness.
One reliable warning comes from the same chart. Code agent Claude Code reached 1.50× on TriMul unaided, beating SIA-H's 1.14×. SIA-W + H still leads at 14.02 ×.
By emitting sound, the agent tunes MAGIC, the single-cell RNA pathway. Harness sweeps have their hyperparameters resolved at 0.241 mse_norm. The first test site to review the weight added a two-line step that the scaffolding did not produce. Rounded the calculated values to non-negative integers, increasing the score to 0.289.
How a Response Agent Chooses Its Traffic
SIA does not use one fixed RL recipe. The Feedback-Agent chooses a training algorithm based on the reward signal it perceives.
At LawBench, the reward was a pure score based scale, so it used PPO with GAE. In TriMul, many kernels failed to converge, so they used the entropic approximation to gain. That way it lifts the weights for rare releases with high rewards. When denoising, use GRPO, which eliminates the value network completely.
The research team also lists REINFORCE with KL-to-base, DPO, and best-of-N behavioral cloning. Each map goes to a different shape of reward and risk of failure.
Power and What to Watch
Power:
- The first system to arrange both scaffolding and weights in one loop, according to the authors' comparison table.
- Consistent gains over previous SOTA in three unrelated domains.
- Open source under MIT, which can be installed as a sia agent, with four integrated functions.
- Algorithm selection is based on observed rewards, not a fixed schedule.
What you can watch:
- The study reports three activities; the broad effects of the selection algorithm are reversed.
- Both instruments prepare the same constant verifier, which compromises Goodhart's consistent results.
- The study warns that a fixed joint surface may be fragile under the disturbance.
Marktechpost Visual Explainer
01 / 09
Key Takeaways
- SIA is the first self-optimizing loop that organizes both the agent scaffold and its model weights.
- The Feedback-Agent reads the full trace of each run, and chooses a harness rewrite or weight update.
- Combining both levers beat scaffold-only across three functions: LawBench, TriMul kernels, scRNA-seq denoising.
- Cable management adds to the cleanliness of software engineering; Weight database information is not readily available.
- Open source under MIT (hexo-ai/sia), built on gpt-oss-120b with LoRA level 32.
Check it out Repo again Research Paper. Also, feel free to follow us Twitter and don't forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? Connect with us



