Sakana AI Proposes DiffusionBlocks: a Block-wise Training Framework That Converts Residual Networks into Independently Trainable Denoising Modules

Researchers from Sakana AI and the University of Tokyo propose DiffusionBlocks. It trains transformer-based networks one block at a time. Training memory is reduced by a factor of B, where B is the number of blocks. Performance is maintained across diverse architectures.
The Memory Problem in Neural Network Training
End-to-end backpropagation requires storing intermediate activations across every layer. Memory consumption grows linearly with network depth. As models grow deeper, this becomes a significant training bottleneck.
One existing technique, activation checkpointing, reduces activation memory by recomputing activations on demand. However, it does not reduce memory for parameters, gradients, or optimizer states. With the Adam optimizer, each layer requires memory for parameters, gradients, and two optimizer states (momentum and variance). This totals 4 times the parameter size per layer, unchanged by activation checkpointing.
Block-wise training offers a different approach. Partitioning a network into B blocks and training each independently reduces memory to roughly 1/B. The reduction is proportional to the number of blocks. The challenge is defining a principled local objective for each block that still produces a globally coherent model.
Prior approaches like Hinton’s Forward-Forward algorithm and greedy layer-wise training rely on ad-hoc local objectives. They consistently underperform end-to-end training and are largely limited to classification tasks.
DiffusionBlocks addresses both the theoretical gap and the limited applicability of prior methods.
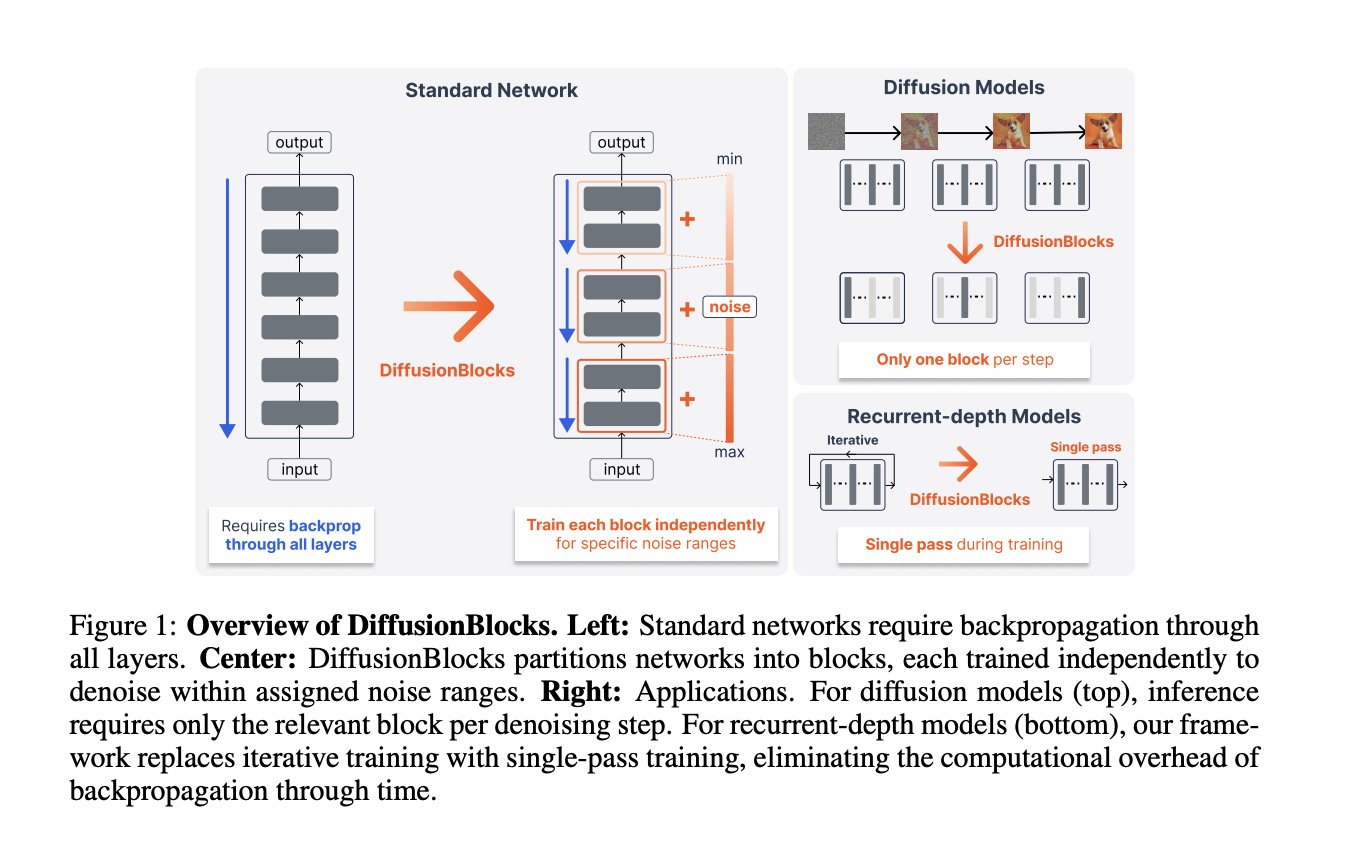
The Core Idea: Residual Connections as Euler Steps
The key insight builds on an established connection in the literature. Residual networks update each layer input via . This corresponds to Euler discretization of ordinary differential equations.
The research team show these updates correspond specifically to the probability flow ODE in score-based diffusion models. In the Variance Exploding (VE) formulation, the reverse diffusion process follows:
Applying Euler discretization to this equation produces an update rule that structurally matches the residual connection update. A stack of residual blocks can be interpreted as discretized denoising steps. The steps span a noise level range [𝞂min, 𝞂max]
In score-based diffusion models, the score matching objective can be optimized independently at each noise level. This means each block can be trained independently, using only its own local objective. No inter-block communication is needed during training.
Converting a Network: Three Steps
Converting a standard residual network to DiffusionBlocks requires three modifications:
- Block partitioning: Split the L-layer network into B blocks. Each block contains a contiguous group of layers.
- Noise range assignment: Define a noise distribution pnoise and a noise range
[𝞂min, 𝞂max] - Noise conditioning: Extend each block’s input to include a noisy version of the target. Add noise-level conditioning via AdaLN (Adaptive Layer Normalization). Each block learns to predict the clean target from its noisy version within its assigned noise range.
During training, a single block is sampled per iteration. The other blocks are not computed. Memory consumption corresponds to L/B layers, not all L layers.
Equi-probability Partitioning
A naive uniform partition divides [𝞂min, 𝞂max]
DiffusionBlocks uses equi-probability partitioning instead. Boundaries are chosen so each block handles exactly 1/B of the total probability mass under pnoise. Blocks assigned to intermediate noise levels receive narrower intervals. Blocks handling extreme noise regions receive wider intervals.
In ablation studies on CIFAR-10 using DiT-S/2, block overlap was disabled to isolate each component. Equi-probability partitioning achieved FID of 38.03 versus 43.53 for uniform partitioning (lower is better). Both used a uniform layer distribution of [4,4,4] across 3 blocks.
Experimental Results
The research team evaluated DiffusionBlocks across five architectures spanning three task categories. All results compare DiffusionBlocks (trained block-wise) against the same architecture trained with end-to-end backpropagation.
| Architecture | Dataset | Metric | Baseline | DiffusionBlocks | Memory Reduction |
|---|---|---|---|---|---|
| ViT, 12-layer, B=3 | CIFAR-100 | Accuracy (higher is better) | 60.25% | 59.30% | 3x |
| DiT-S/2, 12-layer, B=3 | CIFAR-10 | FID test (lower is better) | 39.83 | 37.20 | 3x |
| DiT-L/2, 24-layer, B=3 | ImageNet 256×256 | FID test (lower is better) | 12.09 | 10.63 | 3x |
| MDM, 12-layer, B=3 | text8 | BPC (lower is better) | 1.56 | 1.45 | 3x |
| AR Transformer, 12-layer, B=4 | LM1B | MAUVE (higher is better) | 0.50 | 0.71 | 4x |
| AR Transformer, 12-layer, B=4 | OpenWebText | MAUVE (higher is better) | 0.85 | 0.82 | 4x |
| Huginn recurrent-depth | LM1B | MAUVE (higher is better) | 0.49 | 0.70 | ~10x compute |
Forward-Forward comparison: On CIFAR-100, the Forward-Forward algorithm achieved only 7.85% accuracy under the same ViT architecture. This highlights the gap between ad-hoc contrastive objectives and the score matching objective used by DiffusionBlocks.
DiT inference efficiency: For diffusion models, each denoising step during inference activates only one block. A 12-layer DiT with B=3 uses only 4-layer evaluations per denoising step. This is a 3x inference compute reduction versus running all 12 layers.
Huginn training: Huginn applies the same 4-layer recurrent block recurrently. It uses stochastic recurrence depth averaging 32 iterations. Training uses 8-step truncated backpropagation through time (BPTT). DiffusionBlocks replaces this with a single forward pass per training step. The K-iteration inference procedure is kept unchanged. The 32x iteration reduction outweighs the 3x longer training schedule. DiffusionBlocks trains for 15 epochs versus Huginn’s 5 epochs. Total compute is reduced by approximately 10x.
OpenWebText results: On OpenWebText, DiffusionBlocks MAUVE was 0.82 versus 0.85. Generative perplexity under Llama-2 was 14.99 versus 15.05. Results on this dataset were mixed, with some metrics slightly worse than the baseline.
Masked diffusion partitioning: For masked diffusion models, block partitioning targets the masking schedule rather than continuous noise levels. Each block handles an equal decrement in the unmasking probability alpha
Comparison with NoProp
NoProp is a concurrent work that uses a diffusion framework for backpropagation-free training. It is evaluated only on classification tasks using a custom CNN-based architecture. It does not provide a procedure for applying the method to other architectures or tasks.
| Method | Continuous-time | Block-wise | Accuracy on CIFAR-100 |
|---|---|---|---|
| Backpropagation | No | No | 47.80% |
| NoProp-DT | No | Yes | 46.06% |
| NoProp-CT | Yes | No | 21.31% |
| NoProp-FM | Yes | No | 37.57% |
| DiffusionBlocks (ours) | Yes | Yes | 46.88% |
DiffusionBlocks is the only method combining a continuous-time formulation with block-wise training. It stays within 1 percentage point of the end-to-end backpropagation baseline.
Strengths and Weaknesses
Strengths:
- Principled theoretical grounding via score matching, not ad-hoc local objectives
- Works across five distinct architectures without task-specific modifications
- B× training memory reduction, proportional to the number of blocks
- For diffusion models, inference compute is also reduced by B× during generation
- Equi-probability partitioning significantly outperforms uniform partitioning (FID 38.03 vs 43.53 on CIFAR-10)
- Replaces K-iteration BPTT in recurrent-depth models with a single forward pass
- Blocks can be trained in parallel across GPUs with zero communication overhead
- Moderate block counts (B=2 or B=3) sometimes improve FID over end-to-end training
Weaknesses:
- Requires matching input and output dimensions; cannot currently be applied to U-Net-style architectures
- Validated only on models trained from scratch; fine-tuning of pretrained models is untested
- No principled method for selecting optimal block count for a given architecture and task
- Adds noise conditioning overhead: aggregated wall time is 0.0543s versus 0.0507s under standard training
- On OpenWebText, some metrics are marginally worse than the autoregressive baseline
Marktechpost’s Visual Explainer
DiffusionBlocks · Sakana AI
ICLR 2026 · Block-wise Training
01 / 10
Key Takeaways
- DiffusionBlocks partitions residual networks into B independently trainable blocks, reducing training memory by a factor of B
- Residual connections in transformers map to Euler steps of the reverse diffusion process, providing a principled local training objective for each block
- Equi-probability partitioning assigns equal probability mass per block, not equal noise intervals, improving image generation FID significantly over uniform partitioning
- Validated across five architectures: ViT, DiT, masked diffusion, autoregressive, and recurrent-depth transformers
- For recurrent-depth models like Huginn, replaces K-iteration BPTT with a single forward pass, reducing total training compute by approximately 10x
Check out the Research Paper, Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us



