OpenAI Releases GPT-5.5, Retrained Agent Model Achieves 82.7% in Terminal-Bench 2.0 and 84.9% in GDPval

OpenAI has released GPT-5.5, its most powerful model to date and a fully retrained base model since GPT-4.5. The GPT-5.5 is designed to complete complex, multi-step computing tasks with minimal human supervision. Think of it as the difference between an assistant who needs a checklist and one who understands the basic goal and calculates the steps themselves. The release is rolling out today to Plus, Pro, Business, and Enterprise subscribers across ChatGPT and Codex.
What 'Agentic' Really Means Here
The agent model doesn't just respond to a single notification – it takes a sequence of actions, uses tools (such as web browsing, writing code, running scripts, or operating software), checks its work, and continues until the work is done. Previous models often stop at exit points, requiring the user to re-teach or adjust the path. GPT-5.5 is designed to reduce that inconvenience.
OpenAI introduced GPT-5.5 as a model aimed at agent computing – writing and debugging code, browsing the web, filling out spreadsheets, and continuing to work on multi-step tasks without requiring a human to oversee every move.
Four Areas Where Profits Are Concentrated
Benefits are focused on four places: agent code, computing, knowledge work, and early scientific research – domains OpenAI describes as those 'where progress depends on thinking in context and acting over time.'
For software developers, it's a very fast benchmark SWE-Bench Prowhich tests real-world GitHub problem solving in all four programming languages. GPT-5.5 solves 58.6% of tasks at the end in a single pass. Of note: Claude Opus 4.7 scores a high of 64.3% in this same benchmark, although OpenAI noted that Anthropic reported headaches on a subset of those issues, which may affect the comparison.
With long-horizon coding, OpenAI also reports results Specialist-SWEinternal benchmarking tasks with an average human completion time of 20 hours. GPT-5.5 outperforms GPT-5.4 in Expert-SWE. This benchmark is important because it shows the kind of extended, multi-time engineering work — major refactors, feature builds, deep codebase debugging — that agent tools are increasingly being asked to handle automatically.
Developers who have tested the system early say that GPT-5.5 has a better understanding of the “shape” of the software system, and can better understand why something fails, when a fix is needed, and what else in the codebase may be affected.
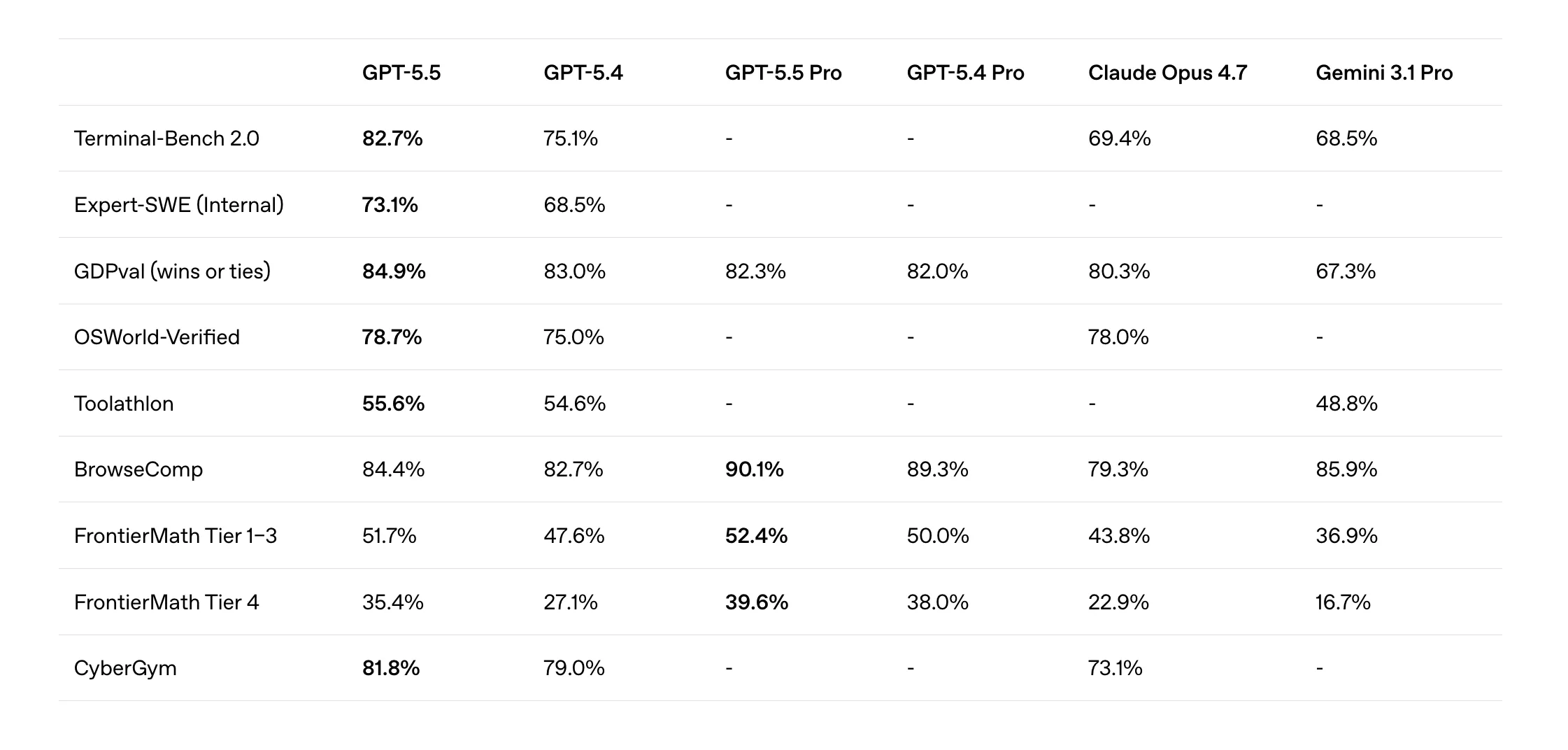
For ML engineers and data scientists who spend significant time in endpoints programming pipelines and debugging scripts, Terminal-Bench 2.0 the results are a very compelling signal. GPT-5.5 scores 82.7% in Terminal-Bench 2.0, which tests complex command-line workflows that require programming, iteration, and tool communication – beating Claude Opus 4.7 at 69.4% and Gemini 3.1 Pro at 68.5%. That's not a small lead.
For the broad knowledge task, GPT-5.5 achieves 84.9% in GDPval, evaluating agents in all 44 tasks of the knowledge task. Opened OSWorld-Verifiedthe benchmark that measures whether the model can independently use real computer environments, reaches 78.7%.
The GPT-5.5 also ships with a Pro variant built for high-precision, heavy-duty tasks. In BrowseComp, which tests the model's ability to track hard-to-find information across the web, the GPT-5.5 Pro scores 90.1%, ahead of the Gemini 3.1 Pro at 85.9%. The model is also the top ranking system in the Artificial Analysis Intelligence Index.
Speed and Signal Performance
Another concern with high-performance models is that they tend to be slow or expensive to run. OpenAI has addressed this directly. GPT-5.5 matches the per-token latency of GPT-5.4 in real-world performance while outperforming in almost every test measured. It also uses far fewer tokens to complete the same Codex tasks – meaning they are shorter, run more efficiently even in complex agent workflows.
In terms of pricing, the standard GPT-5.5 API will be charged at $5 per million input tokens and $30 per million output tokens. In context, GPT-5.4 had a price of $2.50 per billion input tokens and $15 per million output tokens – so the token price has doubled. The OpenAI team argued that tokenization reduces costs, as GPT-5.5 completes the same Codex operations with fewer tokens, meaning it is completely cheaper even with a higher price per token. GPT-5.5 Pro, a high precision variant, is priced at $30 per million input tokens and $180 per million output tokens in the API.
For teams using Codex at scale, the bottom line is what matters: if GPT-5.5 completes a job with materially fewer tokens than GPT-5.4, the effective cost per completed workflow can still come out low despite the high rate.
Scale and Acceptance
OpenAI has seen an increase in use of Codex, with approximately 4 million developers using the tool every week. That scale is important for understanding the context of use: GPT-5.5 is not a research preview but a production model that is pushed to a working, large developer base immediately upon launch.
Key Takeaways
- GPT-5.5 is the first OpenAI base model fully retrained since GPT-4.5designed specifically for the agent's workflow — it can understand complex goals, use tools, evaluate its work, and carry multi-step tasks to completion with minimal human supervision.
- Major career benefits are in agent coding, computing, information work, and early scientific research. — GPT-5.5 scores 82.7% in Terminal-Bench 2.0, 84.9% in GDPval, and 78.7% in OSWorld-Verified, outperforming both Claude Opus 4.7 and Gemini 3.1 Pro in several key benchmarks.
- GPT-5.5 matches the per-token latency of GPT-5.4 while outperforming it in almost all benchmarks – and uses far fewer tokens to complete the same Codex tasks, which means better results without a significant increase in speed or cost per completed workflow.
- API price increases to $5/M for input tokens and $30/M for output tokens (up from $2.50 and $15 for GPT-5.4), and GPT-5.5 Pro with an input price of $30/M and an output of $180/M – The OpenAI team argues that efficient token acquisition reduces the maximum rate of each token for many tasks.
- GPT-5.5 is being released today to Plus, Pro, Business, and Enterprise users of ChatGPT and Codexwith nearly 4 million developers already using Codex every week.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



